

DepthMaster: Taming Diffusion Models for Monocular Depth Estimation
作者:Ziyang Song, Zerong Wang, Bo Li , Hao Zhang , Ruijie Zhu , Li Liu , Peng-Tao Jiang , Tianzhu Zhang 单位:University of Science and Technology of China, VIVO 会议:2025 Arxiv 链接:https://indu1ge.github.io/DepthMaster_page/ 研究动机 现有的生成式深度估计模型,生成模型的中间特征会对纹理进行过度表达,导致错误的纹理预测 为了提高推理速度,采用单步去噪推理,但会丢失细节 核心方法 1.通过特征对齐模块,引入额外的视觉特征增强生成模型特征2.通过傅立叶增强模块提高模型的细节表达能力数据集Train: Hypersim Virtual KITTI Eval: NYUv2 ScanNet KITTI ETH3D DIODE 算力1张H800 实验结果 优势与不足优势 率先采用了Feature...

PointWorld: Scaling 3D World Models for In-The-Wild Robotic Manipulation
作者:Wenlong Huang, Yu-Wei Chao, Arsalan Mousavian, Ming-Yu Liu Dieter Fox, Kaichun Mo, Li Fei-Fei 单位:Stanford University,NVIDIA 会议:2026 Arxiv 研究动机 对于通用机器人而言,在非结构化环境中进行世界建模是至关重要的 基于物理的模型 : 预测精准,但面临“虚实差距 ”,且需要针对特定环境进行繁琐的建模。 基于学习的动力学模型: 虽然能从交互中学习,但通常依赖于特定领域的归纳偏置 视频生成模型: 虽然能生成逼真的视觉效果(如 Sora 等),但缺乏明确的动作条件控制,且在物理一致性上往往表现不佳 核心方法 1.利用Point Flow对状态动作进行统一的建模 2.对静态动态点的Loss进行加权处理,对noise...

MetricAnything: Scaling Metric Depth Pretraining with Noisy Heterogeneous Sources
作者:Baorui Ma,Jiahui Yang,Donglin Di,Xuancheng Zhang, Jianxun Cui, Hao Li, Xie Yan, Wei Chen 单位:Li Auto Inc 会议:2026 Arxiv 链接:https://metric-anything.github.io/metric-anything-io/ 研究动机由于数据来源复杂,暂无工作将Scaling原则应用于绝对深度估计,实现一个通用的模型 核心方法1.构造20M数据 2.Deep-to-Deep...

WildRayZer: Self-supervised Large View Synthesis in Dynamic Environments
作者:Xuweiyi Chen, Wentao Zhou, Zezhou Cheng 单位:University of Virginia 会议:2026 CVPR 链接:https://wild-rayzer.cs.virginia.edu/ 研究动机现有自监督新视角合成方法均基于三维场景静态假设 核心方法 1.构造动态数据集通过挖掘网络手持影像构建动态数据集D-RE10K 2.融合DINOV3特征的伪运动标签构建 3.mask动态物体进行render数据集 Dynamic RealEstate-10K D-RE10K-iPhone RealEstate10K 算力4张H100 实验结果 优势与不足优势 完全自监督 拓展了自监督NVS在动态场景中的应用 不足 所预测的运动mask质量仍有待提高,对于特殊的纹理,如人影等仍然work得不好,部分分割与欠分割 并不算是真正的动态场景重建,并不能够将动态的物体重建出来 记忆点 Unposed 用COCO数据集的物体标签直接复制粘贴到图像中,以增强模型对随机物体的鲁棒性 DINOV3特征能够加快收敛,预测结果更加Sharp



VGGT: Visual Geometry Grounded Transformer
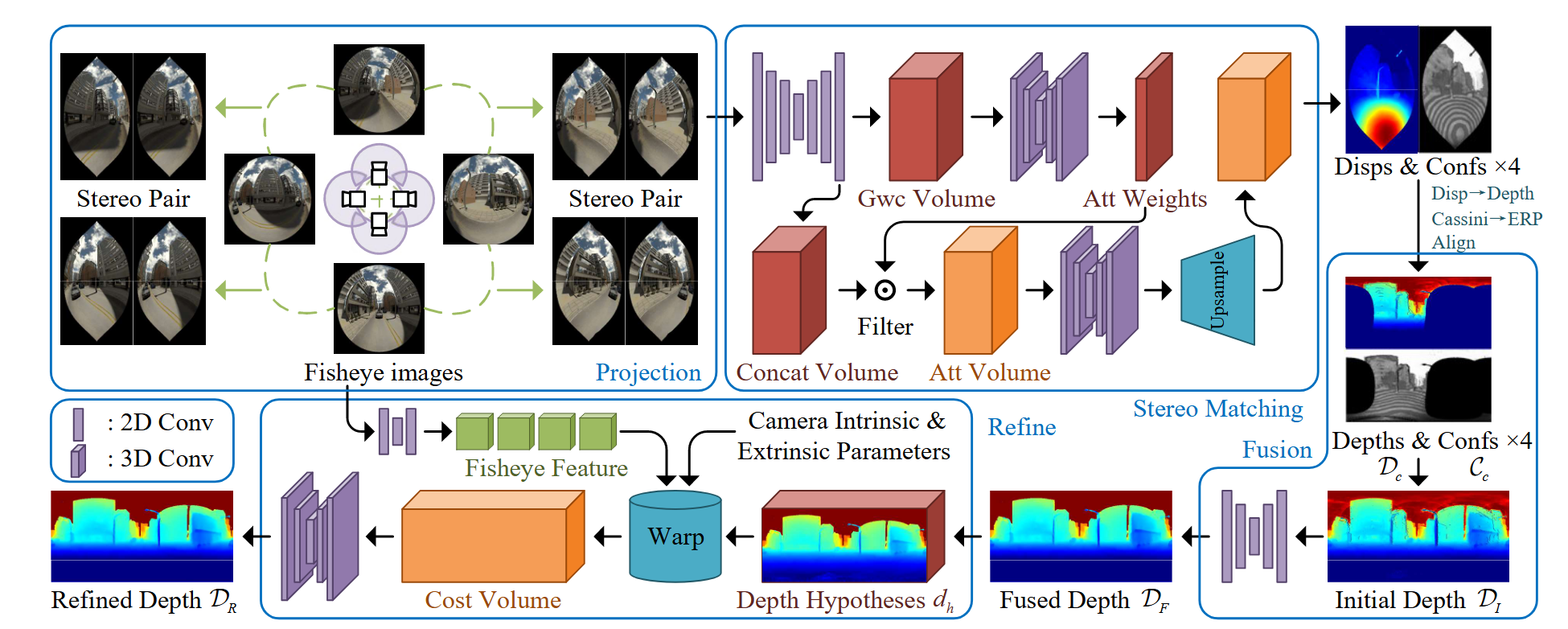
摘要三维计算机视觉通常被约束在单个任务中,因此我们提出了VGGT,一个前馈神经网络,直接推理场景的所有三维属性,包括相机参数,点云,深度图和三维点轨迹。同时该方法简单且效率高,可以在一秒内重建图像。 简介传统的三维重建任务采用视觉几何方法,但是会增加求解的复杂性和计算成本。DUSt3R等方法虽然能直接使用一个神经网络实现三维任务,但只能接受两个图像的输入,需要后处理来重建更多的图像。 VGGT不需要特定的网络,使用的是标准的transformer结构,在大规模公开数据集上训练。尽管存在潜在的冗余,但学习预测这些相互关联的3D属性可以提高整体准确性。在推理过程中,我们可以从单独预测的深度和相机参数中推导出点云,相比使用点云head可以得到更高的精度。 方法 问题定义和符号输入是$N$张图像$I_i \in \mathbb{R}^{3 \times H \times W}$ 的序列$(I_i)^N_{i=1}$,VGGT transofrmer将序列映射为对应的三维注释: f \left( (I_i)_{i=1}^N \right) = (\mathbf{g}_i, D_i,...
Amodal Depth Anything: Amodal Depth Estimation in the Wild
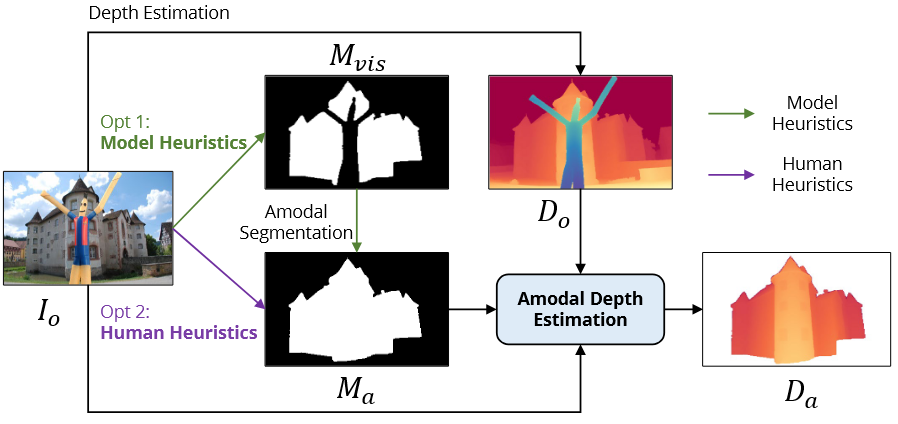
摘要Amodel 深度估计旨在预测场景中遮挡区域的物体的深度。这个任务可以解答模型是否可以根据可见的视觉线索感知到遮挡区域的几何关系。 提出了开放环境下amodel深度估计的全新范式,引入了一个新的大规模数据集Amodel Depth In the Wild(ADIW) 提出了两个互补的框架,一个基于Depth Anything V2的确定性模型AmodelDAV2,一个集成了条件流匹配原理的生成模型AmodelDepthFM 简介目前已有的方法在合成数据集上进行amodel的深度估计,但是合成数据获取成本高,与现实场景的复杂性与多样性存在差距。同时预测的绝对深度难以在数据有限的条件下泛化到未见过的场景上。 方法amodel深度估计旨在给定输入观察图像$I_o$、对应的深度图$D_o$和目标amodel分割mask $M_a$ 时,估计遮挡区域的深度值。 数据集构建 通过将对象放置在自然图像上来构建数据对。使用了图像分割数据集,相较于深度估计数据集规模更大。使用Segment...
Depth Prompting for Sensor-Agnostic Depth Estimation
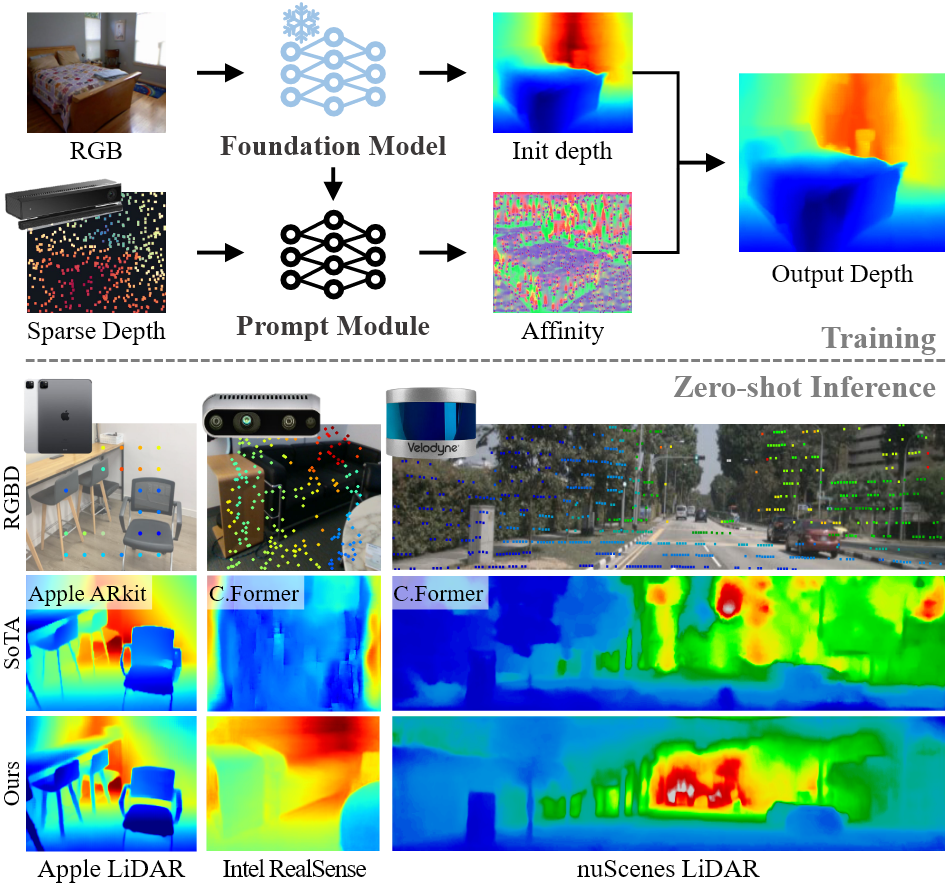
摘要由于系统性的测量偏差,例如密度、感知模式和扫描范围,当前方法在现实世界的应用范围有限。 学习联合表示的输入模式对偏差敏感。 设计了深度提示模块,根据传感器类型或场景配置的新深度分布获得希望的特征表示。 通过将这个模块嵌入基本的单目深度估计模型,可以解决深度扫描范围的限制,提供绝对的带尺度的深度图。 简介目标是构建一个传感器不可知的深度估计模型,能够在各种主动深度传感器上工作。深度提示首先编码稀疏的深度信息,并将其和图像特征进行融合构建一个逐像素的亲和力图。最后对亲和力图和最初的深度图进行细化操作。采用偏差调优技术,只需要对0.1%的模型参数进行微调。 Prompt EngineeringPrompt...
最新文章