
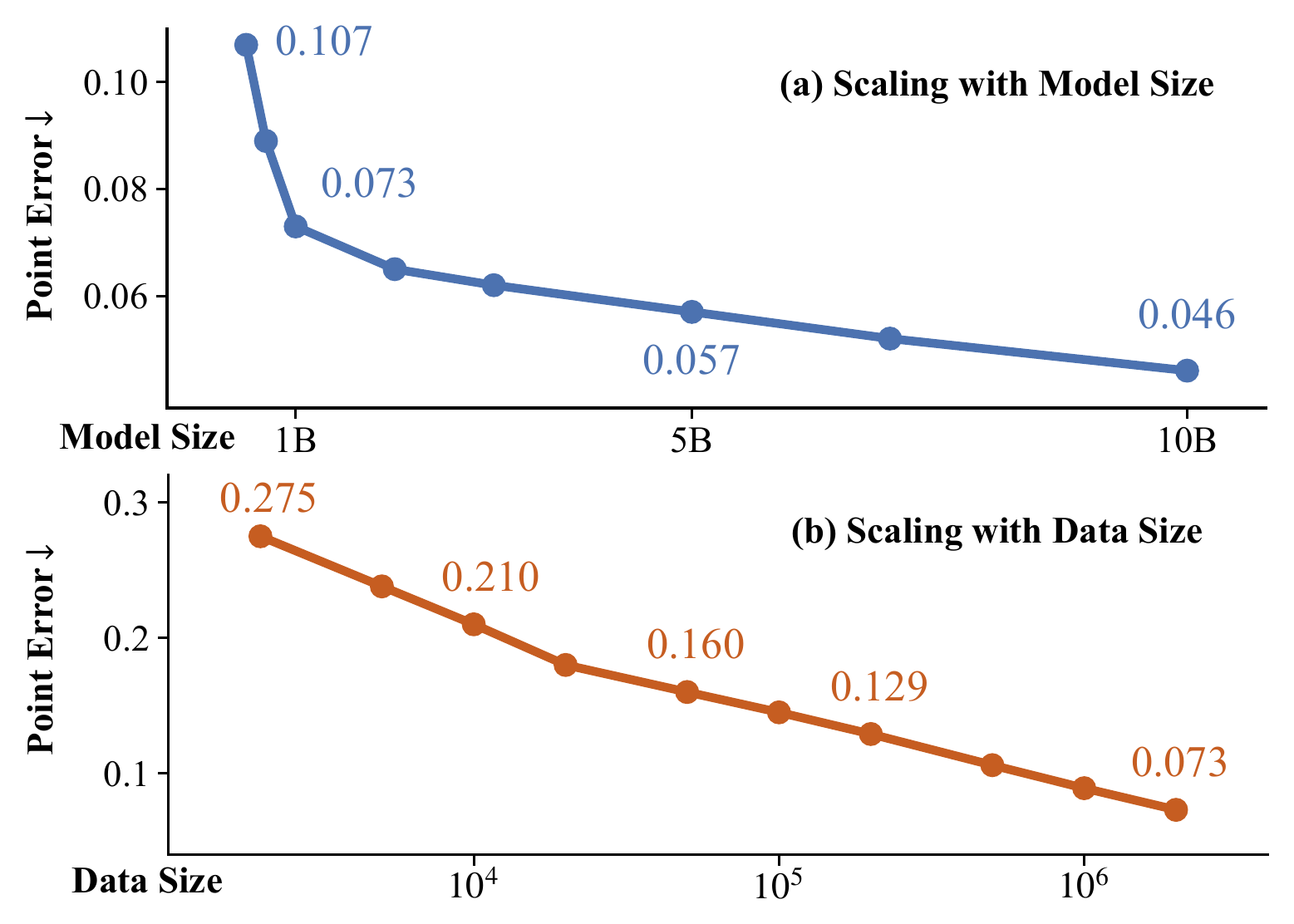
VGGT-Ω
作者:Jianyuan Wang, Minghao Chen, Shangzhan Zhang, Nikita Karaev, Johannes Schönberger, Patrick Labatut, Piotr Bojanowski, David Novotny, Andrea Vedaldi, Christian Rupprecht 单位:Visual Geometry Group, University of Oxford; Meta AI 会议:CVPR 2026 Oral / 2026 Arxiv 链接:https://arxiv.org/abs/2605.15195, Project Page 研究动机VGGT-Ω 这篇文章关心的不是“能不能再把 VGGT 做强一点”,而是一个更底层的问题:前馈式三维重建模型是否也像语言模型、2D 视觉基础模型一样,具有可预期的 scaling law。原始 VGGT 已经证明了 feed-forward reconstruction 可以在很多场景中接近甚至超过传统 SfM/优化式方法,但它仍然有几个限制: 全局...

MoGe-3: Fine-Detail Monocular Geometry Estimation with Self-Guided Sparse Volumetric Refinement
作者: Lingyu Kong、Ruicheng Li、Ruicheng Wang、Sicheng Xu、Chengtang Yao、Jianfeng Xiang、Jiaolong Yang单位: Tsinghua University、University of Science and Technology of China、Microsoft Research会议: arXiv 2026 预印本(截至 2026-07-24 未核实正式会议录用)链接: arXiv | Project Page | Code(论文页面标注为即将公开) 研究动机1. 深度图看起来清晰,不代表三维几何正确近年来的单目深度与单目几何基础模型已经能给出相当可靠的全局布局,但在真正把预测反投影成点图并改变视角后,细杆、栏杆、电线、树枝、小物体边缘等区域仍会出现明显扭曲: 细结构被加粗、折弯或粘连; 前景轮廓与背景表面发生几何串扰; 二维 disparity 边缘看起来锐利,三维点图却不在正确表面上; 全局深度指标较好,但局部结构无法用于高保真重建。 MoGe-3...
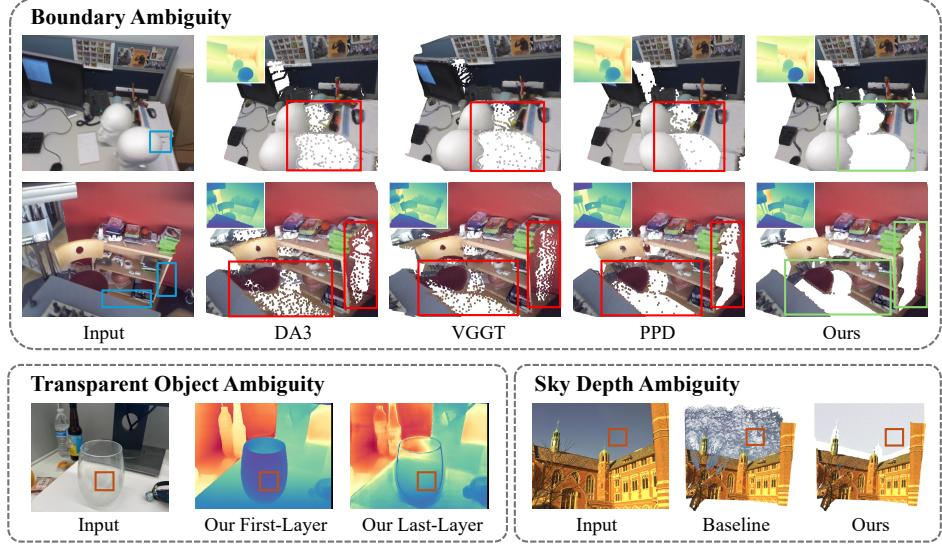
Modeling Depth Ambiguity: A Mixture-Density Representation for Flying-Point-Free Depth Estimation
作者: Siyuan Bian、Congrong Xu、Jun Gao单位: University of Michigan、NVIDIA会议: arXiv 2026 预印本(截至 2026-07-24 未核实正式会议录用)链接: arXiv | Project Page | Code 研究动机1. 飞点并不只是“边缘不够锐利”深度图在二维平面上看起来可能相当平滑,但一旦反投影到三维空间,物体轮廓附近常会出现一圈悬浮在前景和背景之间的离群点,即 flying points。这类错误会直接破坏点云、网格和新视角渲染,也会影响机器人抓取、碰撞检测等依赖真实表面的任务。 以往常见解释是网络分辨率不足、解码器过度平滑或输入模糊。因此,Pixel-Perfect Depth 等方法尝试使用生成式细化,Depth Anything 3、VGGT...

DepthART: Scaling Foundation Monocular Depth to Tiny Models
作者:Feng Xue, Wu Chen, Mingshuai Zhao, Guofeng Zhong, Anlong Ming, Haozhe Wang, Dianqiao Lei, Zhaowen Lin, Haiyang Zhang, Nicu Sebe 单位:University of Trento, Beijing University of Posts and Telecommunications, The Hong Kong University of Science and Technology, Tsinghua University 会议:2026 Arxiv 链接:论文 | 项目页 研究动机Depth Anything、Metric3D、UniDepth 等几何基础模型已经证明,大规模混合数据可以带来跨场景相对深度和度量尺度泛化。但把骨干缩小到几百万参数后,这些能力往往不能自动保留。 DepthART 把问题归纳为两个与小容量直接相关的瓶颈: 数据分布偏置更容易被记住。...

VAR: Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
作者:Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, Liwei Wang 单位:Peking University, ByteDance Inc. 会议:NeurIPS 2024 链接:论文 | 会议页面 | 代码 | 演示 研究动机把图像离散成 token 后,最直接的做法是照搬语言模型:把二维 token 网格按光栅顺序拉平成一维,再从左到右、从上到下逐 token 生成。但图像并不是天然的一维序列,这种做法带来四个问题: 单向顺序与图像的二维联合分布并不自然匹配; 当前 token 只能使用“之前”的区域,难以执行需要双向上下文的任务; 拉平破坏了近邻像素或 patch 的空间局部性; $n\times n$ token 需要 $n^2$ 次串行解码,分辨率上升后速度迅速恶化。 VAR 的核心变化非常简单:不再预测“下一个 token”,而是预测“下一个尺度”。模型先生成低分辨率语义布局,再逐级补充更高分辨率的结构和纹理;同一尺度内的所有 token...
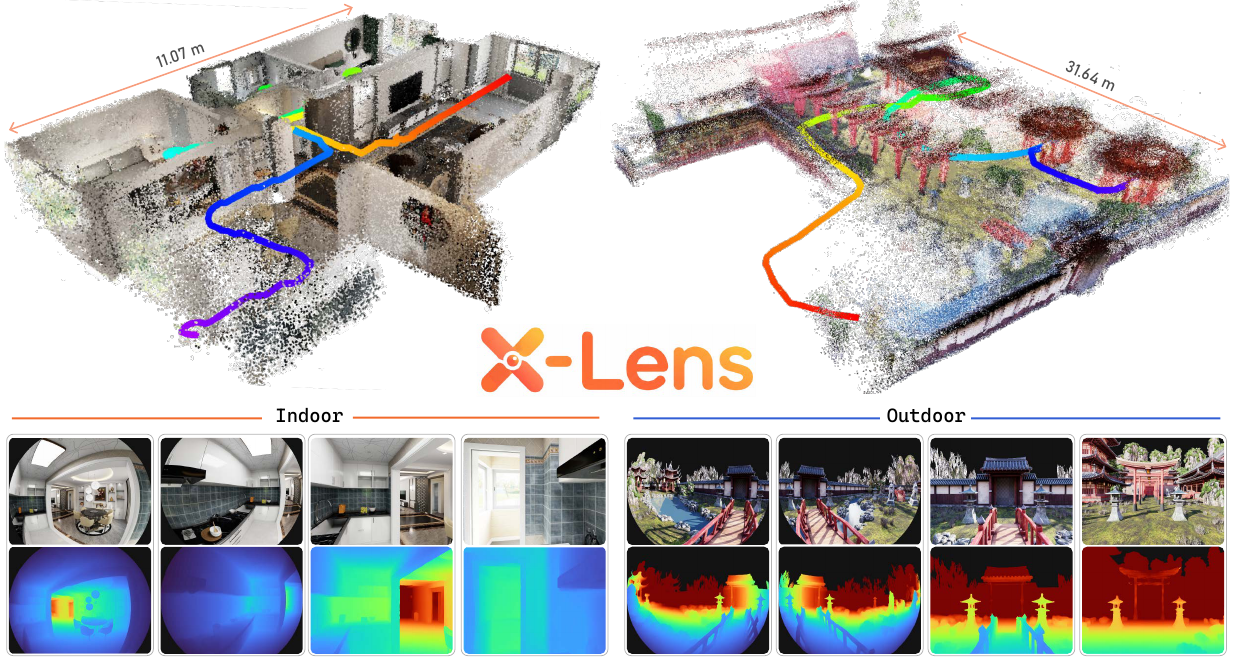
X-Lens: Real-Time Metric Depth Estimation with Heterogeneous Cameras
作者:Heng Zhou, Shuhong Liu, Yonghao He, Bohao Zhang, Fa Fu, Chenhui Hou, Xianbao Hou, Lijun Han, Cong Yang, Wei Sui 单位:D-Robotics, The University of Tokyo, Soochow University 会议:2026 Arxiv 技术报告 链接:论文 | 项目页 | 代码 研究动机机器人、自动驾驶和多相机空间感知系统很少只使用一种镜头:针孔相机适合保留远处细节,鱼眼相机适合覆盖近场和周边区域。真正的设备往往把它们组合在同一刚性相机架上,但这会带来两个问题: 针孔与鱼眼的投影规律不同,相同大小的图像 patch 对应的视线分布和局部尺度并不一致; 通用三维基础模型通常同时预测相机、点图、位姿和深度,模型很大,也不一定能在边缘设备上实时运行。 全景拼接可以把输入统一到球面或 ERP 表示,但重采样会改变原始成像几何,也可能损失相机之间本来可利用的共视信息。X-Lens...

MetaView: Monocular Novel View Synthesis with Scale-Aware Implicit Geometry Priors
作者:Yufei Cai, Xuesong Niu, Hao Lu, Kun Gai, Kai Wu, Guosheng Lin 单位:Nanyang Technological University, Kolors Team at Kuaishou Technology, The Hong Kong University of Science and Technology (Guangzhou) 会议:ECCV 2026 链接:论文 | 项目页 | 代码 研究动机单张图像的新视角合成同时面对两个互相牵制的目标:一方面,输出必须遵守相机运动和场景几何;另一方面,当视角变化很大、目标视图出现源图不可见区域时,模型又必须依靠生成先验补全内容。 已有扩散式方法大致分为两类。显式几何路线先重建点云或网格,再把重投影结果交给扩散模型补洞;它的局部对应关系较可靠,但错误深度、稀疏重建和遮挡会被直接传入生成阶段。纯隐式路线只给生成模型相机位姿,保留了强大的开放域生成能力,却容易出现“相机走了、场景尺度也跟着漂移”的问题。 MetaView...

ARDepth: Auto-regressive Monocular Depth Estimation with Progressive Visual Conditioning
作者:Zijie Wang, Wei Zhang, Weiming Zhang, Xiao Tan, Weikai Chen, Xiaoxu Li, Guanbin Li 单位:Sun Yat-sen University, Shenzhen Loop Area Institute, Baidu Inc., LightSpeed Studios (Tencent America), Lanzhou University of Technology 会议:2026 Arxiv(Under review) 链接:https://arxiv.org/abs/2607.12433 文中图表均引自原论文;该 arXiv 版本标注为 CC BY 4.0。 研究动机当前零样本单目深度估计常借助扩散模型:把深度视为一张全局连续的场,经由多轮去噪逐步恢复。但真实几何并不总是平滑的——遮挡边界、细杆、表面相交处恰恰是离散且有层级的高频结构。作者认为,统一的全局去噪并没有显式表达“先有整体布局、再有表面与边界”的构造过程。 另一条路是视觉自回归(AR),但把完整深度图拉平成单一长序列的 Flat...

ZipDepth: Bringing Lightweight Zero-Shot Monocular Depth Anywhere, on Any Device
作者:Fabio Tosi, Luca Bartolomei, Matteo Poggi, Stefano Mattoccia 单位:University of Bologna, Bologna, Italy 会议:ECCV 2026(论文与作者项目页标注;本文未独立核验 ECCV 会务目录) 链接:arXiv | PDF | 项目页 | 官方代码 研究动机单目深度估计的难点不只是“从一张 RGB 图预测深度”,而是同一张二维图像可能对应许多不同的三维结构。近年的基础模型借助大规模数据和重型视觉主干,已经能在室内、道路、合成场景之间取得很强的零样本泛化;代价是数亿参数、数百到数千 GMAC,以及难以放进嵌入式设备的延迟和能耗。另一端的轻量模型虽然跑得快,却大多在 KITTI 或 NYUv2 等单一域的自监督设置中训练,换域后容易失效。 ZipDepth 要解决的正是这条断层:能否把基础模型的跨域知识迁移到一张真正可部署的小网络中,而不是在精度和实时性之间二选一?作者用 Depth Anything v2-Large 生成伪深度监督,以 17 个异构域、约 14.1M...
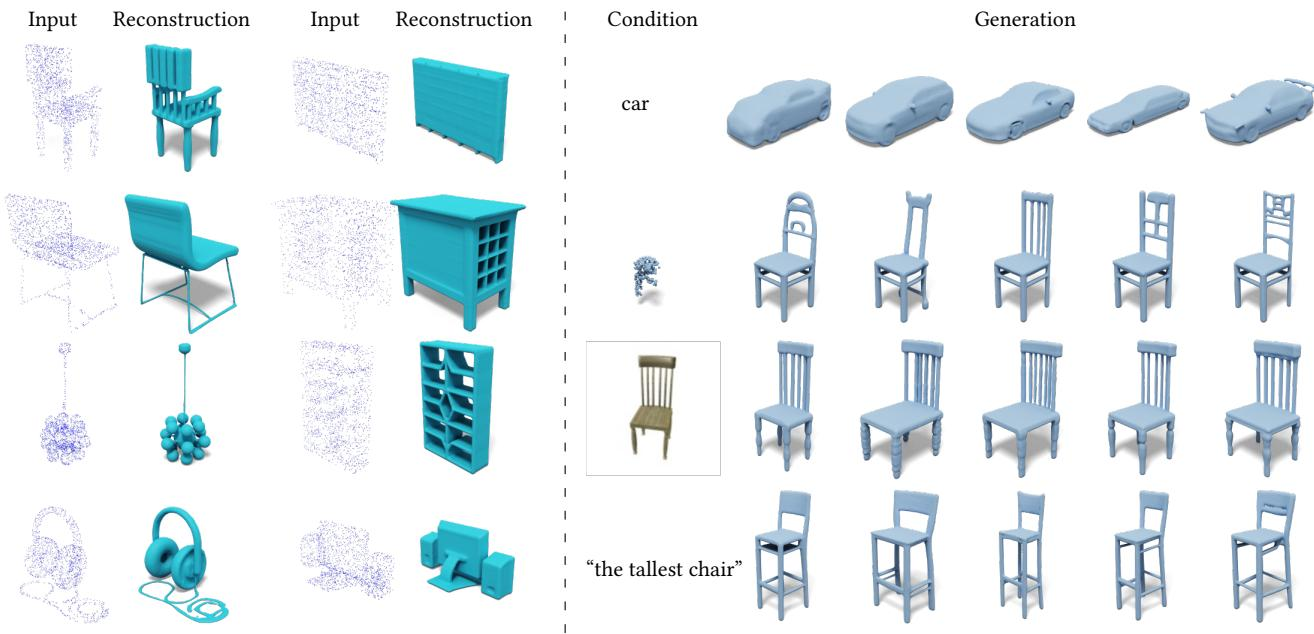
3DShape2VecSet: A 3D Shape Representation for Neural Fields and Generative Diffusion Models
作者:Biao Zhang, Jiapeng Tang, Matthias Nießner, Peter Wonka 单位:KAUST, Technical University of Munich 会议:ACM Transactions on Graphics 42(4), SIGGRAPH 2023 链接:arXiv / Project / Code / DOI 研究动机3DShape2VecSet 讨论的是一个很基础但容易被低估的问题:如果要把扩散模型真正搬到 3D 形状生成里,应该在什么表示空间里扩散? 2D 图像扩散模型可以直接在像素或压缩 latent 上工作,因为图像天然是规则网格。但 3D 形状没有这么统一的表示:voxel 规则但立方级开销太大,point cloud 轻量但缺少连续表面,mesh 结构复杂,neural field 连续且能表达完整表面,却本身像一个无限维函数,不能直接作为扩散模型的固定长度输入。 论文选择的路线是 latent diffusion:先训练一个 shape autoencoder,把 3D 形状压成固定大小...
最新文章