
M²Depth: Self-supervised Two-Frame Multi-camera Metric Depth Estimation

MFF

STF

Depth Decoder

Adaptive Depth Sample

 微信
微信 支付宝
支付宝
相关推荐
2024-12-08
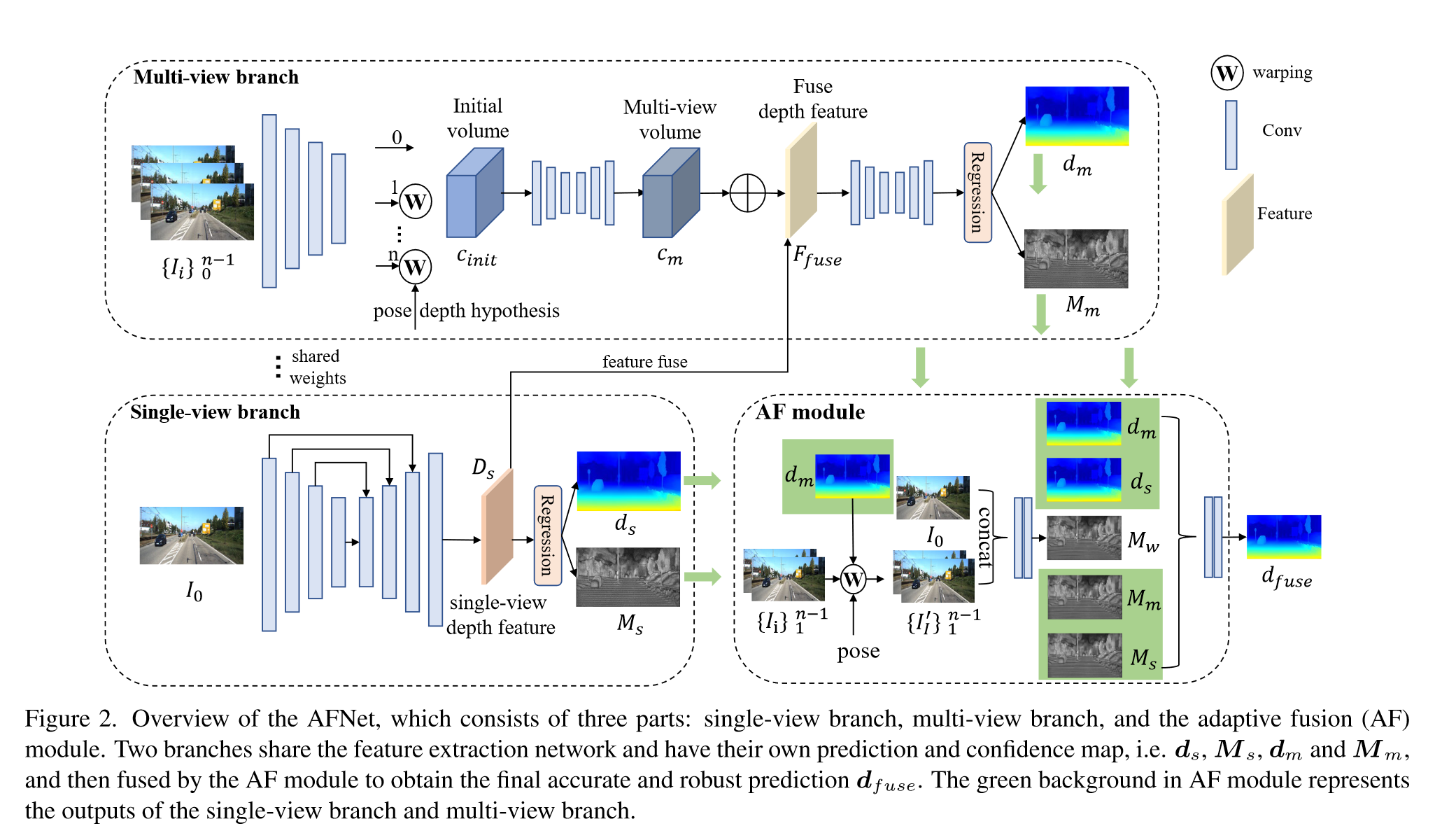
Adaptive Fusion of Single-View and Multi-View Depth for Autonomous Driving
Input: $n-1$ 个源图像 ${I_i}^{n-1}_{i=1}$、参考图像 $I_0$、相机内参和相机姿态 Output:depth $d$ Part:single-view depth module, multi-v iew depth module, adaptive fusion module and pose correction module Single-view and Multi-view Depth Module使用ConvNeXt-T作为backbone提取四个尺度上的特,征$F_{ i,l} (l = 1, 2, 3, 4)$,特征维度分别为$C=96,192,384,768$ Single-view branch采用多尺度的decoder聚合特征获得深度特征$D_s ∈ R^{H/4×W/4×257}$ 对$D_s$的前256个通道使用softmax得到depth probability volume $P_s ∈ R^{H/4×W/4×256}$,最后一个通道作为置信度图$M_s ∈...

2024-12-06
Depth Anywhere: Enhancing 360 Monocular Depth Estimation via Perspective Distillation and Unlabeled Data Augmentation
方法 数据清洗及合理数据掩码生成为了消除不合理像素对训练的影响,使用GroundingSAM将不合理的区域滤除。对于有效像素占比低于20%的图像也进行溢出。 教师模型对无标签图像使用立方体投影,然后用Depth Anything对投影后的patch进行预测,将360度模型的预测结果投影到立方体视图,再和Depth Anything的输出计算Loss。 随机旋转处理由于Depth Anything在立方体的每一个面上进行估计,缺乏对场景的综合理解,所以会出现伪影。 在等矩形坐标系下应用旋转矩阵: ( \hat{\theta}, \hat{\phi} )=\mathcal{R} \cdot( \theta, \phi). \tag{1}从等矩形到立方体投影,立方体每一个面的视场角等于90度,每一个面都能够看作一个焦距为$w/2$的透视相机,所有的面共用世界坐标系中的中心点。因此每一个相机的外参矩阵能够用一个旋转矩阵定义,则每个面上的像素表示为: p=K \cdot R_{i}^{T} \cdot q, \tag{2} q=\left[ \begin{matrix} q_{x}...
2024-12-06
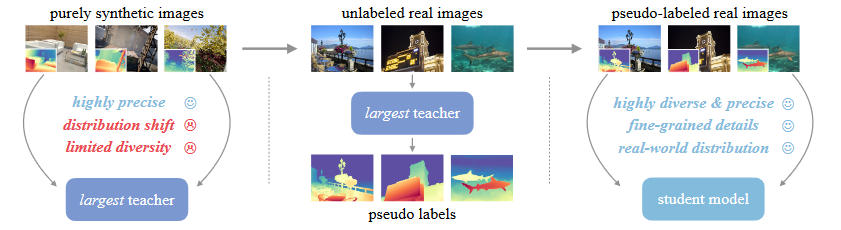
Depth Anything v2
三个关键方法:1)将所有有标签的真实图像更换为合成图像 2)增强了教师模型的capacity 3)通过大规模伪标签真实图像对学生模型进行训练 真实标签数据的缺点:1)标签噪声:传感器固有的缺点、透明等场景 2)忽略的细节:边缘、洞 导致错误的估计,过度平滑的估计 合成数据的局限性:1)合成图像与真实图像之间的分布偏移 真实图像包含更多随机性,合成图像场景的布置较为有序。 2)所覆盖的场景有限,难以与真实世界的场景相匹敌 大规模无标签真实图像的作用:1)缩小合成图像与真实场景之间的领域差异 2)增大所覆盖的场景范围 3)知识迁移 sparse的gt在评估的时候真的会影响指标的可靠性么? 能否直接训练或者使用一个强大的metric depth网络来生成metric的伪标签,从而使得学生模型能够具备metric depth预测能力?

2024-12-08
NVDS+: Towards Efficient and Versatile Neural Stabilizer for Video Depth Estimation
整体网络结构与NVDS保持一致 稳定网络深度感知特征编码对于一个滑动窗口中的一组初始深度图 $F^{norm}_i={F_1,F_2,F_3,F_4}$ ,其归一化的方式为: F_{i}^{n o r m}=\frac{F_{i}-\operatorname* {m i n} \left( \mathbf{F} \right)} {\operatorname* {m a x} \left( \mathbf{F} \right)-\operatorname* {m i n} \left( \mathbf{F} \right)} \,, i \in\left\{1, 2, 3, 4 \right\}. \tag{1}将归一化后的深度图与RGB图像连接形成RGBD序列,通过transformer backbone编码成深度感知的特征图 交叉注意力模块目标帧的特征图中的像素作为query,keys和values是从参考帧中生成的。 采用了patch merging的方法,并将交叉注意力机制限制在局部窗口内,减小计算开销。 用 $T$...

2024-12-28
Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution
ABSTRACT提出目前存在的问题神经网络方法得到的深度图远低于1兆像素的分辨率,缺少细粒度的细节,限制了其实用性 本文方法和创新点证明了一致的场景结构和高频细节之间存在一种权衡,并利用一个简单的深度融合网络来融合低分辨率和高分辨率的估计,来利用这种二元性 采用双重估计方法提高整幅图像的深度估计,采用patch选择方法,为最终的结果添加局部细节 通过合并不同分辨率的估计以及不断变化的context,可以用预训练好的模型生成高水平细节的数百万像素深度图。 INTRODUCTION问题:单目深度估计网络的输出特性随着输入图像的分辨率改变,高分辨率的图像输入网络,能够更好地捕捉高频细节,但估计的结构一致性会降低,这种二元性源于给定模型的容量和感受野大小限制 当深度线索相比于感受野间隔太大时,模型会生成结构不一致地结果,不同区域的正确分辨率发生局部改变 本文提出(创新点)①...
2024-12-06
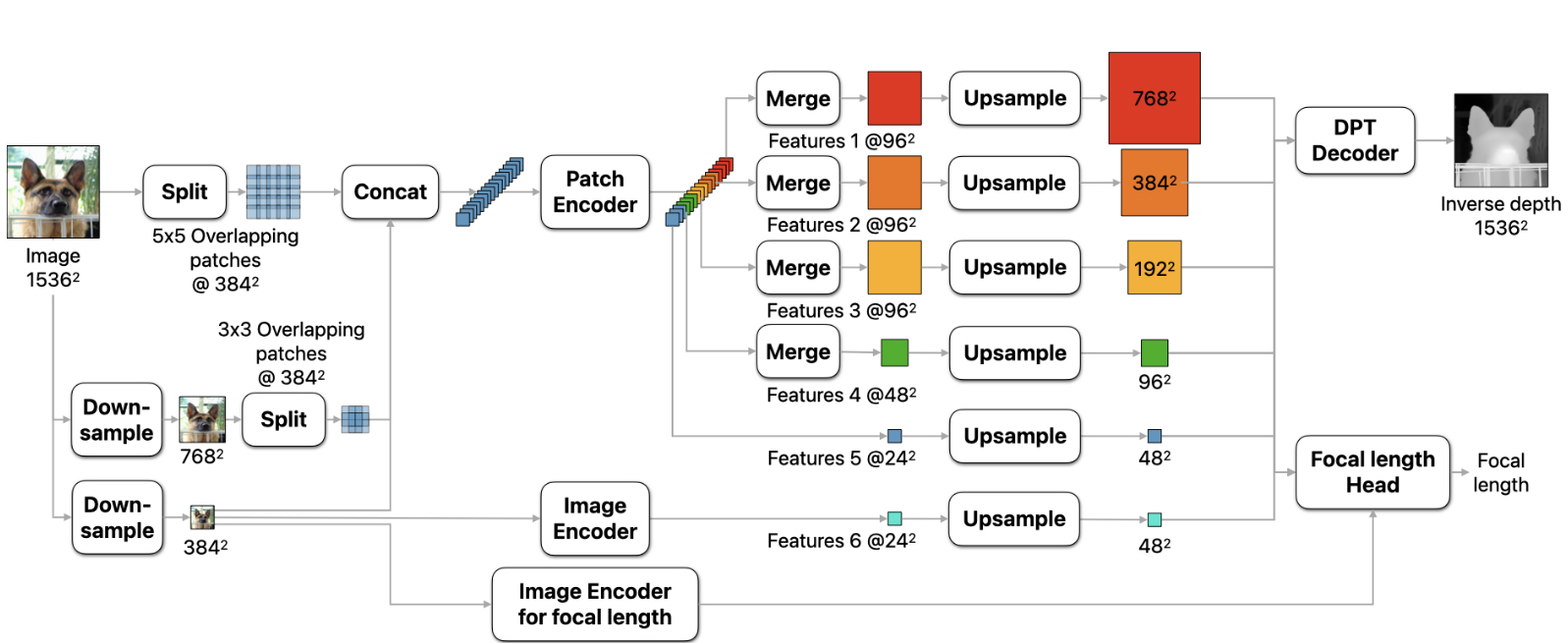
DEPTH PRO: SHARP MONOCULAR METRIC DEPTH IN LESS THAN A SECOND
思路:在不同的尺度提取patches,对patches应用ViT encoders,将patches 的预测结果融合成一个单独的高分辨率的稠密估计。 方法 1.相对于可变分辨率的方法,将输入分辨率固定为了1536×1536,保证了足够大的感受野,防止了out-of-memory的问题。使用普通的ViT encoder,能够利用多种预训练ViT的主干网络。 2.将输入图像分成5×5个分辨率为384×384的重叠patch,下采样至786×786后分成3×3个重叠的patch。将patch链接后输入patch encoder,每一个patch得到分辨率为24×24的feature。在精细的尺度上,进一步提取中间特征。得到特征之后将特征patches融合成maps输入decoder。 Sharp 单目深度估计训练目标网络预测的输出为canonical inverse depth,然后通过视场角转换为metric depth D_m=\frac{f_{px}}{wC}对于metric datasets,使用MAE...
最新文章




