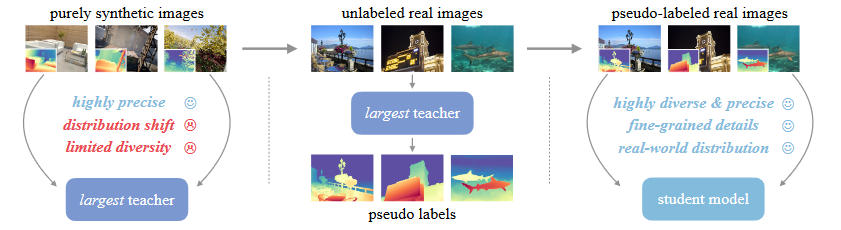
Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution
ABSTRACT
提出目前存在的问题
神经网络方法得到的深度图远低于1兆像素的分辨率,缺少细粒度的细节,限制了其实用性
本文方法和创新点
证明了一致的场景结构和高频细节之间存在一种权衡,并利用一个简单的深度融合网络来融合低分辨率和高分辨率的估计,来利用这种二元性
采用双重估计方法提高整幅图像的深度估计,采用patch选择方法,为最终的结果添加局部细节
通过合并不同分辨率的估计以及不断变化的context,可以用预训练好的模型生成高水平细节的数百万像素深度图。
INTRODUCTION
问题:
单目深度估计网络的输出特性随着输入图像的分辨率改变,高分辨率的图像输入网络,能够更好地捕捉高频细节,但估计的结构一致性会降低,这种二元性源于给定模型的容量和感受野大小限制
当深度线索相比于感受野间隔太大时,模型会生成结构不一致地结果,不同区域的正确分辨率发生局部改变
本文提出(创新点)
① 提出一个双重估计框架,根据图像内容自适应地融合同一张图像不同分辨率地深度估计,得到的结果能够拥有高频细节并保持结构一致性
②从输入图像选择patch,并根据局部深度线索密度以自适应的分辨率输入到模型,并将这些估计融合到一个结构性一致基础估计上,得到详细的高分辨率估计。
PROPOSED METHOD
模型结构

模型分解—1:准备工作
估计Contextual线索
使用通过阈值化的RGB梯度得到的图像的近似边缘图
融合单目深度估计
由低分辨率输入得到的低分辨率估计图
同一图像的高分辨率深度图或在深度不连续点精确度更高,但存在低频伪影的patch
目标:将第二个输入的高频细节和第一个输入相结合,后者能提供一致性结构和固定的深度范围
方法
使用一个标准的网络,采用Pix2Pix结构,一个10层的U-net作为生成器,训练网络将高分辨率输入的细粒度细节传输到低分辨率输入
采用672*672作为输入分辨率。
对patch使用一个引导滤波,用ground truth估计作为指引。
模型分解—2:双重估计
对具有不同分辨率的感受野大小的核的边缘图应用二进制扩展。扩张边缘图停止产生同一个结果时的分辨率就是每个像素能够接受到语义信息的最大分辨率
低分辨率估计设置为网络感受野的大小,能够决定图像的整体结构
模型分解—3:用于局部增强的Patch估计
base estimate:对整幅图像进行双重估计
Patch selection:以基本的分辨率平铺图像,比较patch中的边缘密度与整幅图像的边缘密度比较,前者小则抛弃,若大,则增加patch尺寸知道边缘密度与原图像匹配。
Patch estimates:将高分辨率估计的尺寸固定为感受野尺寸的两倍,使用另外的双重估计估计patch的深度估计,然后逐一将patch估计融合到base估计上
Base resolution adjustment:一些图像其大部分都缺少边缘,以至于选择的patch会很小。所以对base estimate上采样到更高的分辨率
 微信
微信 支付宝
支付宝