Unsupervised Learning of Depth and Ego-Motion from Video
ABSTRACT
本文方法和创新点
提出了一个无监督学习框架用于单目深度和相机运动估计任务
使用了单视角深度网络和多视角位姿网络,利用计算的深度和位姿将附近的视角扭曲到目标视角上,定义了一个损失
实验效果提升
在单目深度估计上的性能与有监督的方法相当
在相当的输入的情况下,位姿估计的新能要优于已建立的SLAM系统
INTRODUCTION
问题:
多年的研究还不能够使得对真实世界场景的建模能力与人类水平相当
几何视角合成系统只有当它对场景几何及相机位姿的中间预测和物理ground-truth一致时,其表现才能一致良好。
本文提出(创新点)
① 训练了一个模型,观察图像序列,并通过预测可能的相机运动和场景结构来解释其观察。
② 采用了一种端到端的方法,能够从输入像素直接预测自运动(用六自由度的变换矩阵参数化表示),得到场景结构(用一个参考视角下的逐像素的深度图表示)
RELATED WORK
Structure from motion
传统的方法依赖于精确的图像对应,这可能在弱纹理,复杂的几何/光度,薄结构和遮挡等部分造成问题。
基于学习的技术能够在训练的时候使用额外的监督,能够克服上述问题。
Warping-based view synthesis
一个典型范例是首先明确地估计三维几何或建立输入视角之间的像素对应关系,然后通过从输入视角组合图像块来合成新视角。
PROPOSED METHOD
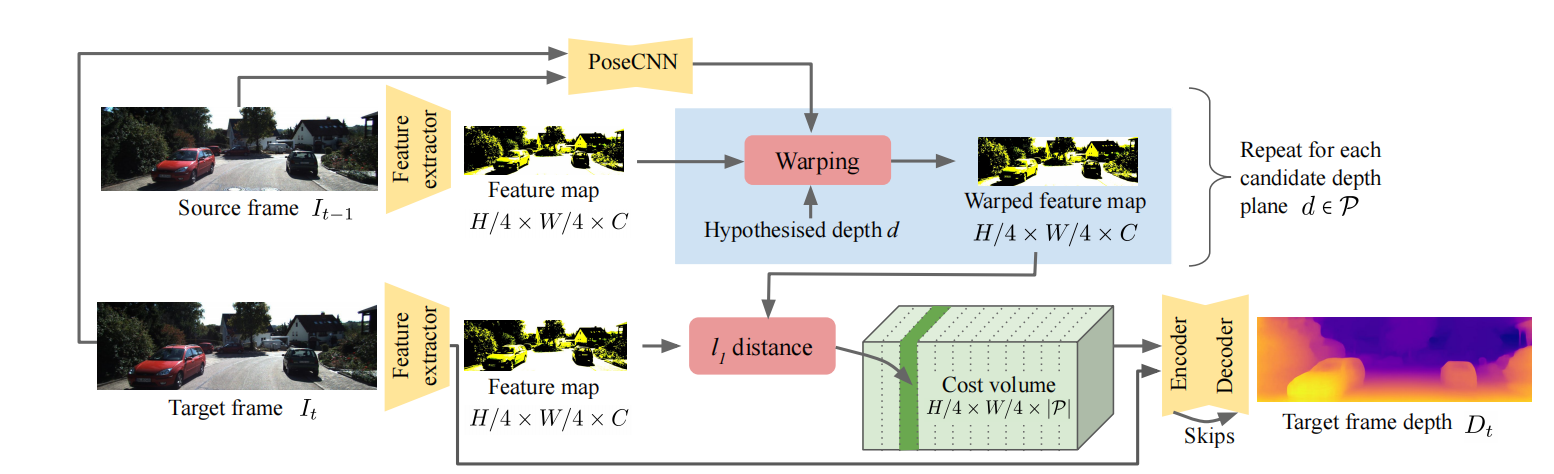
模型结构
一个单视角的深度CNN以及一个相机位姿估计CNN,两者同时训练,在测试时可独立使用。
假设:场景表面的变化是由于相机运动导致的
模型分解1:单视角深度网络

采用DispNet结构
模型分解2:位姿网络

输入为目标视角以及所有源视角,输出是目标视角与每一个源视角之间的相对位姿
模型分解3:可解释性预测网络
与pose网络共享前五个特征编码层,后面接着五个去卷积层。
加权的视角合成目标
同时添加正则化项,对模型未考虑的因素给予一定的松弛
视角合成

输入一个场景的视角,然后从不同的相机位姿合成看到的场景的新图像
视角合成的目标
基于图像的可微深度渲染
pt在源视角ps上的投影坐标
对应坐标的获得:将目标视角上的点投影到源视角,利用插值来获得warp后图像点的值

模型限制建模
隐形假设
场景是静止的
在目标视角和源视角之间没有遮挡或去遮挡
表面满足lambertian,光度一致性误差是有意义的
克服梯度局部性
使用一个卷积的编解码结构,将输出约束为全局平滑的,促进梯度从有意义的区域向邻域传播
多尺度和平滑损失
最终损失函数
 微信
微信 支付宝
支付宝