WildRayZer: Self-supervised Large View Synthesis in Dynamic Environments
作者:Xuweiyi Chen, Wentao Zhou, Zezhou Cheng
单位:University of Virginia
会议:2026 CVPR
链接:https://wild-rayzer.cs.virginia.edu/
研究动机
现有自监督新视角合成方法均基于三维场景静态假设
核心方法

1.构造动态数据集
通过挖掘网络手持影像构建动态数据集D-RE10K
2.融合DINOV3特征的伪运动标签构建

3.mask动态物体进行render
数据集
- Dynamic RealEstate-10K
- D-RE10K-iPhone
- RealEstate10K
算力
4张H100
实验结果




优势与不足
优势
- 完全自监督
- 拓展了自监督NVS在动态场景中的应用
不足
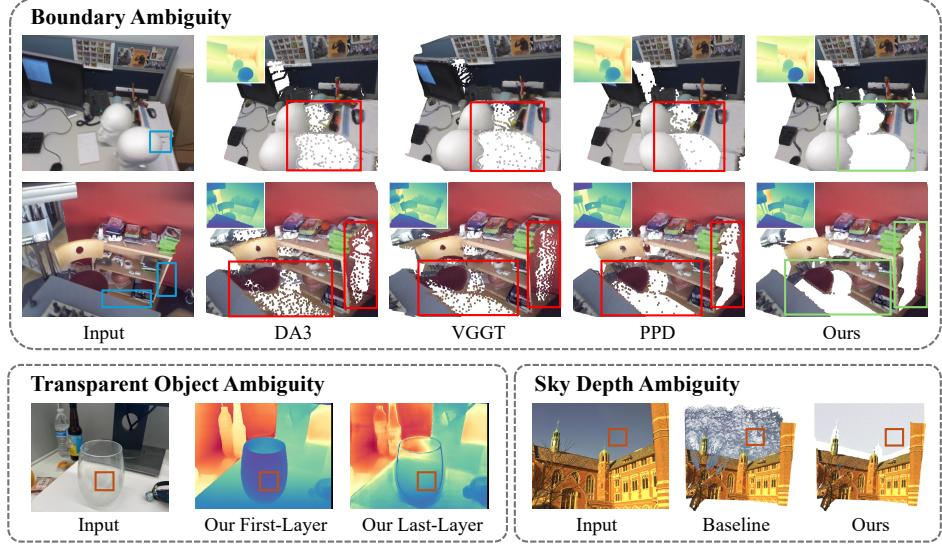
- 所预测的运动mask质量仍有待提高,对于特殊的纹理,如人影等仍然work得不好,部分分割与欠分割
- 并不算是真正的动态场景重建,并不能够将动态的物体重建出来
记忆点
- Unposed
- 用COCO数据集的物体标签直接复制粘贴到图像中,以增强模型对随机物体的鲁棒性
- DINOV3特征能够加快收敛,预测结果更加Sharp
 微信
微信 支付宝
支付宝
相关推荐

2026-06-15
2DGS: 2D Gaussian Splatting for Geometrically Accurate Radiance Fields
作者:Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, Shenghua Gao 单位:ShanghaiTech University, University of Tübingen, Tübingen AI Center 会议:SIGGRAPH 2024 Conference Papers 链接:arXiv, Project, Code 研究动机 3D Gaussian Splatting 的吸引力在于它把新视角合成做到了高质量、快速训练和实时渲染,但它的几何表达并不天然适合表面重建。3DGS 的基本单元是三维体素状 Gaussian blob,它可以很好地拟合视图相关外观,却会在几何上产生一个矛盾:真实世界的许多物体表面是薄的二维流形,而 3D Gaussian 表示的是有体积的密度分布。颜色可以通过体渲染被拟合出来,但表面在哪里、法向是否一致、不同视角看到的交点是否稳定,并没有被表示方式直接约束。 这篇文章要解决的问题不是单纯提升 PSNR,而是把 Gaussian Splatting...

2026-07-24
MetaView: Monocular Novel View Synthesis with Scale-Aware Implicit Geometry Priors
作者:Yufei Cai, Xuesong Niu, Hao Lu, Kun Gai, Kai Wu, Guosheng Lin 单位:Nanyang Technological University, Kolors Team at Kuaishou Technology, The Hong Kong University of Science and Technology (Guangzhou) 会议:ECCV 2026 链接:论文 | 项目页 | 代码 研究动机单张图像的新视角合成同时面对两个互相牵制的目标:一方面,输出必须遵守相机运动和场景几何;另一方面,当视角变化很大、目标视图出现源图不可见区域时,模型又必须依靠生成先验补全内容。 已有扩散式方法大致分为两类。显式几何路线先重建点云或网格,再把重投影结果交给扩散模型补洞;它的局部对应关系较可靠,但错误深度、稀疏重建和遮挡会被直接传入生成阶段。纯隐式路线只给生成模型相机位姿,保留了强大的开放域生成能力,却容易出现“相机走了、场景尺度也跟着漂移”的问题。 MetaView...

2026-05-14
RoSplat: Robust Feed-Forward Pixel-wise Gaussian Splatting for Varying Input Views and High-Resolution Rendering
作者:Hoang Chuong Nguyen, Renjie Wu, Jose M. Alvarez, Miaomiao Liu 单位:Australian National University; NVIDIA 会议:2026 Arxiv 链接:https://arxiv.org/abs/2605.13093 研究动机 Generalizable 3D Gaussian Splatting 的目标是跳过 per-scene optimization,用少量输入视角直接前馈预测一组 pixel-wise Gaussians,然后完成 novel view synthesis。PixelSplat、MVSplat、DepthSplat、TranSplat 等方法已经证明了这条路线的效率和泛化潜力。 但这篇论文指出,现有 pixel-wise feed-forward GS 有两个很实际的问题。 输入视角数变化会导致过亮。很多模型训练时只用固定数量的输入视角,例如 RealEstate10K 上常用 2 views;测试时如果给 4/8/16 views,同一 3D...

2026-05-18
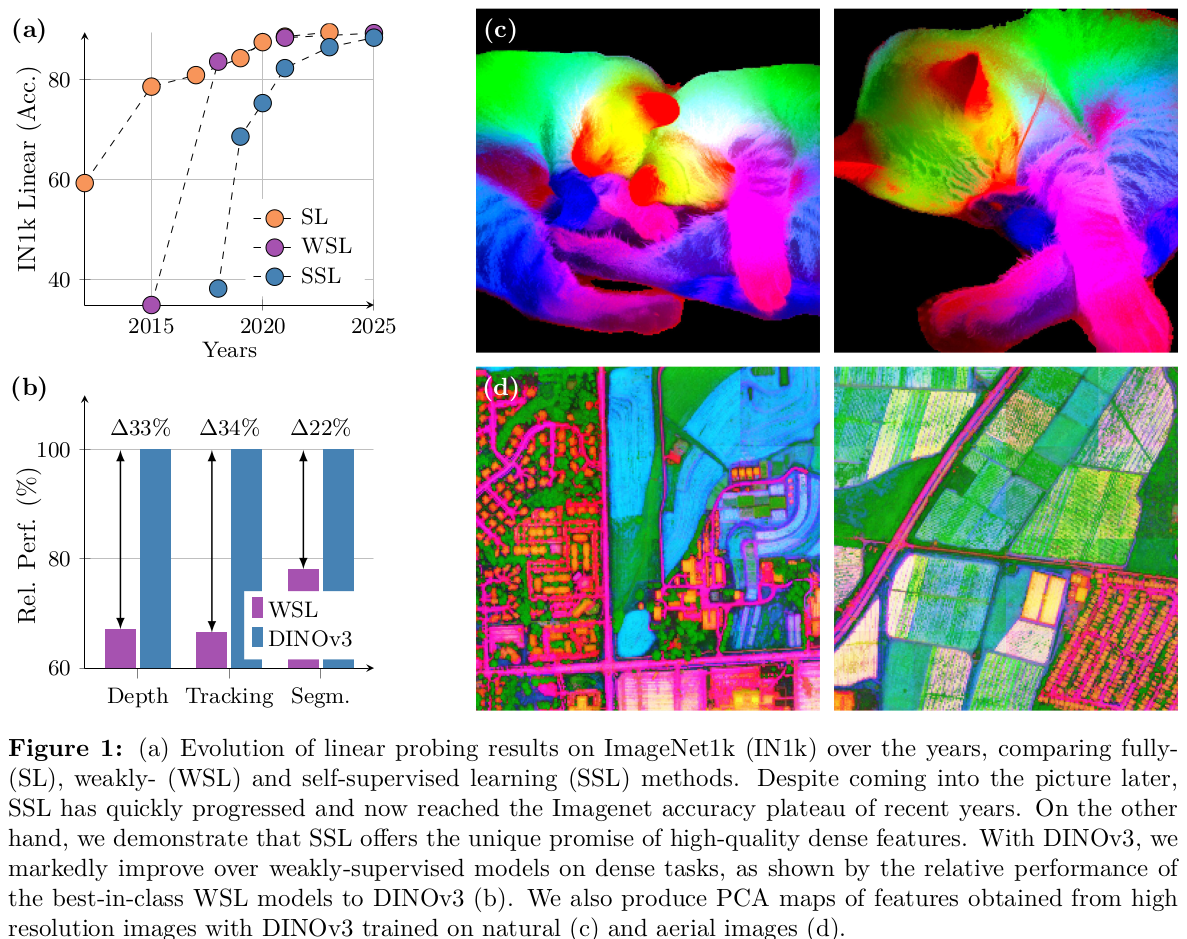
Emerging Properties in Self-Supervised Vision Transformers
作者:Mathilde Caron, Hugo Touvron, Ishan Misra, Herve Jegou, Julien Mairal, Piotr Bojanowski, Armand Joulin 单位:Facebook AI Research, Inria, Sorbonne University 会议:ICCV 2021 / arXiv 2021 链接:https://arxiv.org/abs/2104.14294 研究动机 这篇论文关心的问题不是“ViT 能不能做自监督”,而是“自监督会不会让 ViT 学到和监督学习、卷积网络不同的性质”。当时 ViT 在视觉任务上已经能和卷积网络竞争,但代价是更多数据和更高算力,而且特征并没有表现出特别清晰的独特优势。作者的判断是:如果 Transformer 在 NLP 中的成功很大程度来自自监督预训练,那么视觉 Transformer 也应该检查监督标签是否压缩了图像中的丰富信息。 论文给出的两个核心观察很直接。第一,自监督 ViT 的最后一层 [CLS] token...

2026-05-18
DINOv2: Learning Robust Visual Features without Supervision
作者:Maxime Oquab, Timothee Darcet, Theo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski 单位:Meta AI Research, Inria, Universite Paris-Saclay, ENS-PSL 会议:TMLR 2024 / arXiv...
2026-05-18
DINOv3
作者:Oriane Simeoni, Huy V. Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michael Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothee Darcet, Theo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julien Mairal, Herve Jegou, Patrick Labatut, Piotr Bojanowski 单位:Meta AI Research, WRI, Inria 会议:2025...
评论
最新文章