DVD: Deterministic Video Depth Estimation with Generative Priors
作者:Hongfei Zhang, Harold Haodong Chen, Chenfei Liao, Jing He, Zixin Zhang, Haodong Li, Yihao Liang, Kanghao Chen, Bin Ren, Xu Zheng, Shuai Yang, Kun Zhou, Yinchuan Li, Nicu Sebe, Ying-Cong Chen
单位:HKUST(GZ), HKUST, UCSD, Princeton University, MBZUAI, SZU, Knowin, UniTrento
会议:2026 Arxiv
链接:https://arxiv.org/abs/2603.12250
研究动机
1.生成式方法具有强大的视频先验和零样本泛化能力,但容易出现随机采样带来的几何幻觉和尺度漂移
2.判别式方法虽然稳定高效,但又高度依赖大规模标注数据来消除语义歧义
3.打破这种 trade-off,将预训练视频扩散模型中的丰富生成先验,以确定性回归的方式迁移到视频深度估计中,从而实现兼具稳定性、泛化性、数据效率和长视频可扩展性的统一框架
[!IMPORTANT]
能否设计一种视频深度估计框架,既能有效兼顾判别式模型的结构稳定性与生成式方法的丰富时空先验,又能在推理和部署上保持高效与可扩展
核心方法

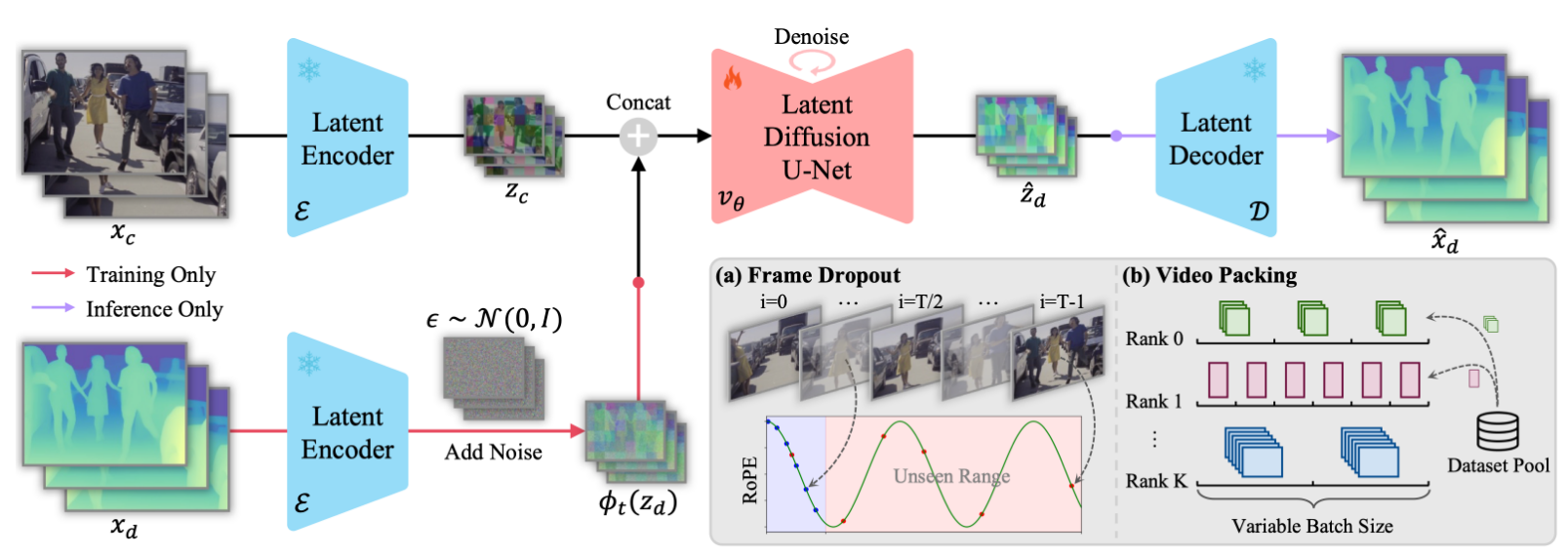
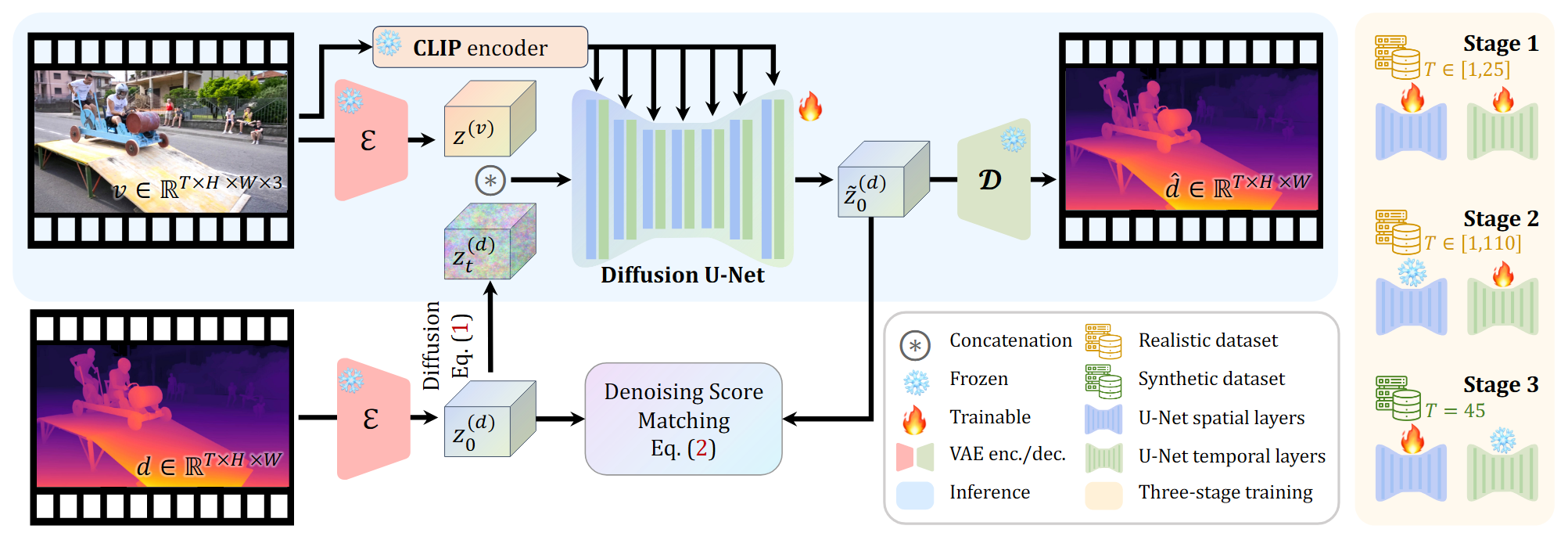
1.将时间步作为结构锚点

越大的t,模型会预测低频的全局结构,信噪比越低;越小的t,模型会预测高频的局部细节,信噪比越高
在DVD中,具体的时间步t首先被展开为正余弦编码:
然后通过一个MLP投影注入模型。处于中间区域的时间步整体上与其他时间步的相似性更高,因此能够更好地平衡高频以及低频的内容。

2.潜在流形修正
使用像素级的训练目标,会导致mean collapse问题,抹去高频细节。

通过时序和空间上的一阶一致性进行对齐
空间:
时间:
3.全局仿射一致性
由于模型是确定性的,所以不会出现尺度的不稳定性,而相邻窗口之间的尺度不一致主要是由VAE Decoder带来的,而这种不一致性是一种全局的仿射不变性,可以通过重叠部分进行对齐。
4.图像-视频联合训练
使用视频数据训练会损失空间细节,因为模型会更关注时序的一致性以及运动,忽略边缘等细节的平滑性。
采用顺序的图像到视频的训练策略,可能会导致灾难性遗忘问题,在第二阶段忘掉第一阶段的预测细节。
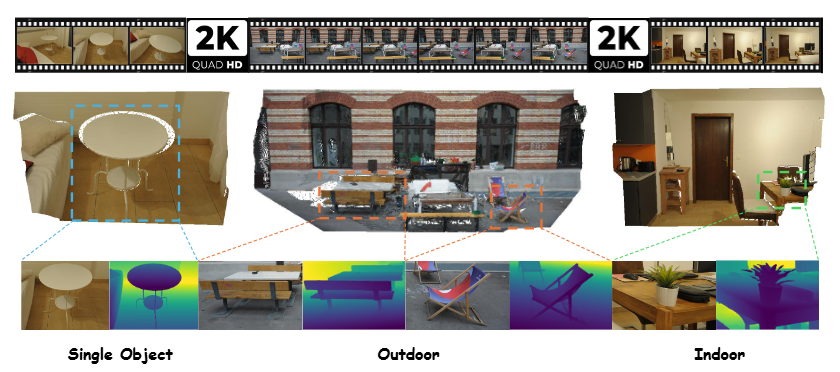
数据集
Train:TartanAir,Virtual KITTI,Hypersim
Eval:KITTI,ScanNet,Bonn,Sintel,DIODE,NYU
算力
8张H100
实验结果






优势与不足
优势
1.采用了强大的视频生成模型作为主干网络,在少量训练数据的情况下,能够达到SOTA性能,同时采用确定性模型输出,消除了生成式模型的模糊性。
2.通过timestep anchor,LMR,Joint Training多种策略,实现了空间时序一致,细节丰富的预测
不足
1.使用的视频生成模型对于实时部署来说还是太过Heavy
2.不依赖VAE,或许能够得到更加精细的几何结构
记忆点
- Latent Mainifold Rectification对齐时间和空间两个维度上的微分信号
- timestep可以作为生成模型中的一个anchor
- 图像视频联合训练
 微信
微信 支付宝
支付宝