
![[马克思主义原理]专题三:唯物辩证法](/img/my.png)
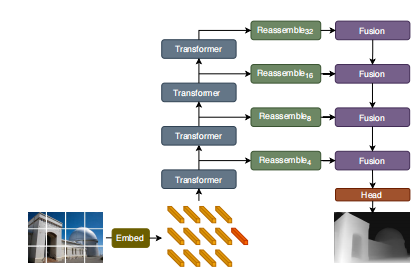
Vision Transformers for Dense Prediction
ABSTRACT本文方法和创新点提出使用稠密vision transformers在卷积网络中作为backbone进行稠密估计任务 将vision...
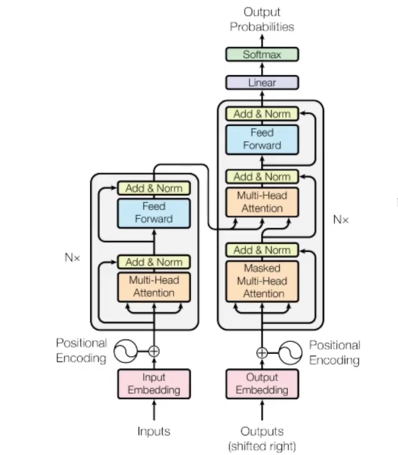
Transformer系列讲解
Transformer传统方法存在的问题传统RNN存在的问题各层之间不为独立,无法并行计算 传统word2vec存在的问题预训练好的向量不变,在不同的语境中可能存在不同的意思 整体结构EncoderAttention对于不同的数据集有不同的关注点,关注对完成任务重要的特征,是由计算机自己提取的 self-attention把上下文的一些信息加入到当前词编码的过程中,考虑整体的信息 Q:query查询矩阵,要去查询的内容;K:Key键,等待被查的V:value实际特征信息 要求当前词与其他词之间的关系,用当前词的q与各词的k内积得到相关程度,相关性越大内积越大 将分支归一化转换成对应的比例,同时不能让结果被向量本身维度所影响,并与v相乘得到最终的attention...
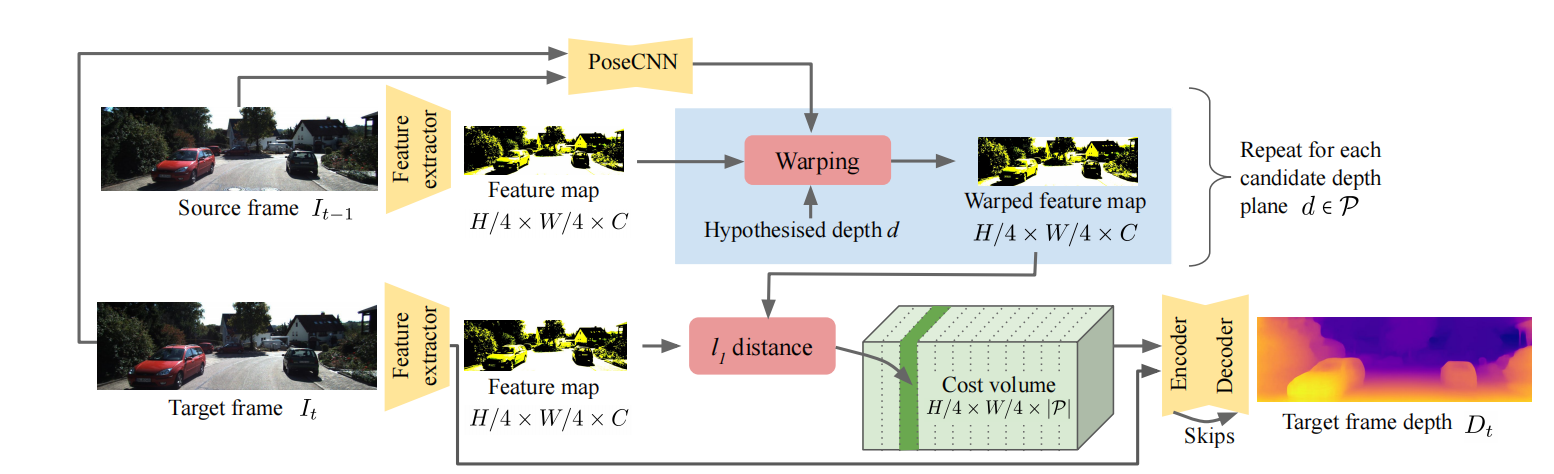
The Temporal Opportunist: Self-Supervised Multi-Frame Monocular Depth
ABSTRACT提出目前存在的问题对于许多应用来说,视频帧的序列信息在测试阶段也可以获得,但大多数单目网络没有使用这个额外的信号,忽略了重要的信息;这些方法要么在测试阶段使用计算量大的细化技术,要么采用非循环网络,间接使用那些本就可获得的几何信息。 本文方法和创新点提出了ManyDepth,一种自适应的稠密深度估计方法,能够在测试阶段利用序列信息。 提出了一个端到端的cost volume,基于只用自监督训练的方法 采用了一个新的一致性损失,当cost volume不可靠时忽略它 实验效果提升在KITTI和Cityscape上的实验表明我们的方法比所有已发布的自监督baseline都要好,包括那些在测试阶段使用单帧或多帧的方法。 INTRODUCTION问题:在测试阶段,实际情况下可以得到不止一帧,而现有的单目方法没有使用这些额外的帧 将子监督训练直接应用于多视角平面扫描立体结构会产生较差的结果 本文提出(创新点)① 在训练和测试阶段都使用这些额外的帧来对多帧的深度估计系统进行自监督 ②...
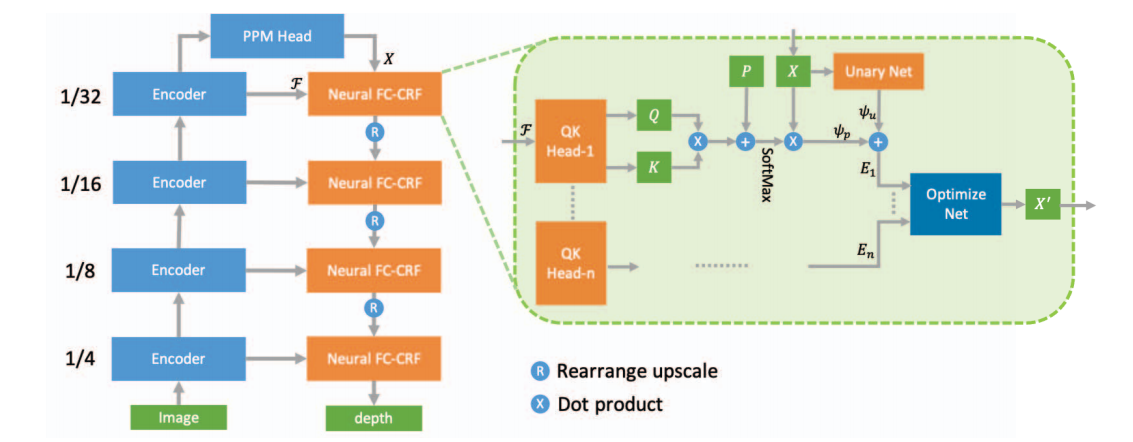
Neural Window Fully-connected CRFs for Monocular Depth Estimation
ABSTRACT 提出目前存在的问题由于较大的计算成本,CRF通常只在邻域间使用,这就不能够充分利用全连接CRF的能力。 本文方法和创新点将输入分为多个窗,并对每个窗应用FC-CRF优化,减小了计算的复杂度,使得FC-CRF可行。 为了更好的得到节点之间的关系,应用多头机制计算多头势函数,并将此势函数用于网络,输出优化的深度图。 整体为自下而上,自上而下的结构,神经窗FC-CRF模块在其中作为解码器,同时vision...
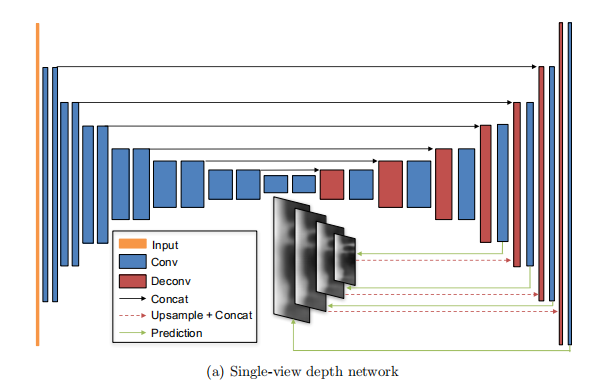
Unsupervised Learning of Depth and Ego-Motion from Video
ABSTRACT本文方法和创新点提出了一个无监督学习框架用于单目深度和相机运动估计任务 使用了单视角深度网络和多视角位姿网络,利用计算的深度和位姿将附近的视角扭曲到目标视角上,定义了一个损失 实验效果提升在单目深度估计上的性能与有监督的方法相当 在相当的输入的情况下,位姿估计的新能要优于已建立的SLAM系统 INTRODUCTION问题:多年的研究还不能够使得对真实世界场景的建模能力与人类水平相当 几何视角合成系统只有当它对场景几何及相机位姿的中间预测和物理ground-truth一致时,其表现才能一致良好。 本文提出(创新点)① 训练了一个模型,观察图像序列,并通过预测可能的相机运动和场景结构来解释其观察。 ② 采用了一种端到端的方法,能够从输入像素直接预测自运动(用六自由度的变换矩阵参数化表示),得到场景结构(用一个参考视角下的逐像素的深度图表示) RELATED WORKStructure from...
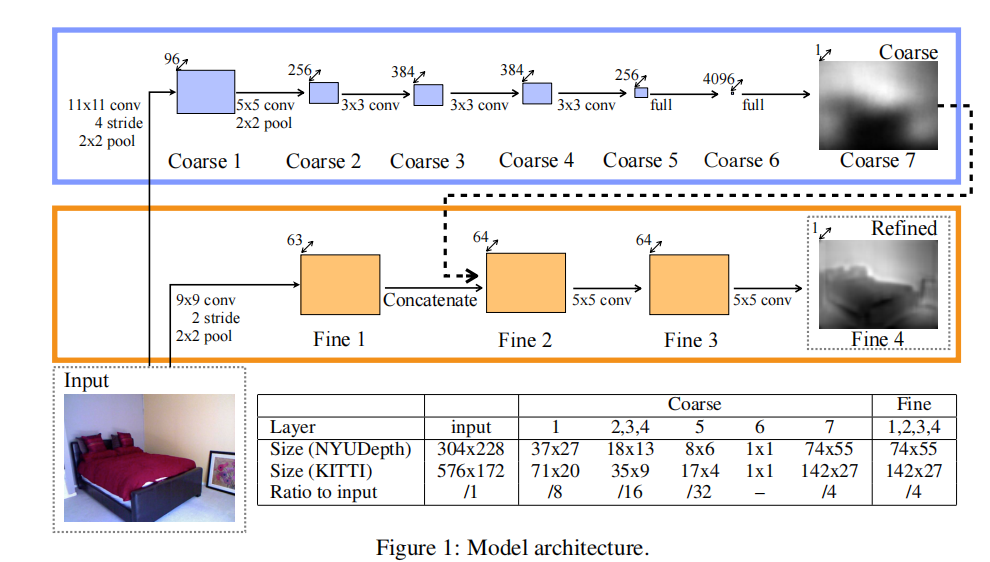
Depth Map Prediction from a Single Image using a Multi-Scale Deep Network
ABSTRACT提出目前存在的问题单目深度估计任务本身是模糊的,具有很多不确定性 本文方法和创新点两个深度网络stacks 一个从整个图像得到粗糙全局预测 另一个将预测进行局部细化 采用尺度不变误差测量深度关系 实验效果提升在NYU和KITTI上达到了先进水平,在不需要超像素化的情况下,能够匹配详细的深度边界 INTRODUCTION问题:进行单目深度估计需要很多单目深度线索,而不想立体深度估计能够利用对应同名点 单目深度估计是一个不适定的问题,一幅图像可能对应无穷多可能的场景 尽管在数据集中不存在极端的例子,但房间和家具的尺寸还是有适度的变化 本文提出(创新点)① 采用尺度不变误差,聚焦于空间关系而不是整体尺寸 ② 利用神经网络直接对深度回归,包含两个部分 一个首先估计场景的全局结构 另一个用局部信息对估计的深度进行细化 PROPOSED METHOD模型结构 输入图像同时经过两个部分,coarse网络的输出传输到fine网络中作为第一层额外的图像特征,使得局部网络能够对全局预测进行编辑,获得更细化的细节。 模型分解—1:Global Coarse-Scale...

Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution
ABSTRACT提出目前存在的问题神经网络方法得到的深度图远低于1兆像素的分辨率,缺少细粒度的细节,限制了其实用性 本文方法和创新点证明了一致的场景结构和高频细节之间存在一种权衡,并利用一个简单的深度融合网络来融合低分辨率和高分辨率的估计,来利用这种二元性 采用双重估计方法提高整幅图像的深度估计,采用patch选择方法,为最终的结果添加局部细节 通过合并不同分辨率的估计以及不断变化的context,可以用预训练好的模型生成高水平细节的数百万像素深度图。 INTRODUCTION问题:单目深度估计网络的输出特性随着输入图像的分辨率改变,高分辨率的图像输入网络,能够更好地捕捉高频细节,但估计的结构一致性会降低,这种二元性源于给定模型的容量和感受野大小限制 当深度线索相比于感受野间隔太大时,模型会生成结构不一致地结果,不同区域的正确分辨率发生局部改变 本文提出(创新点)①...
最新文章




