BEVFormer
BEV Queries
where H, W are the spatial shape of the BEV plane.
Each grid cell in the BEV plane corresponds to a real-world size of s meters.
The center of BEV features corresponds to the position of the ego car by default.
Spatial Cross-Attention
Temporal Self-Attention
 微信
微信 支付宝
支付宝
相关推荐
2026-05-18
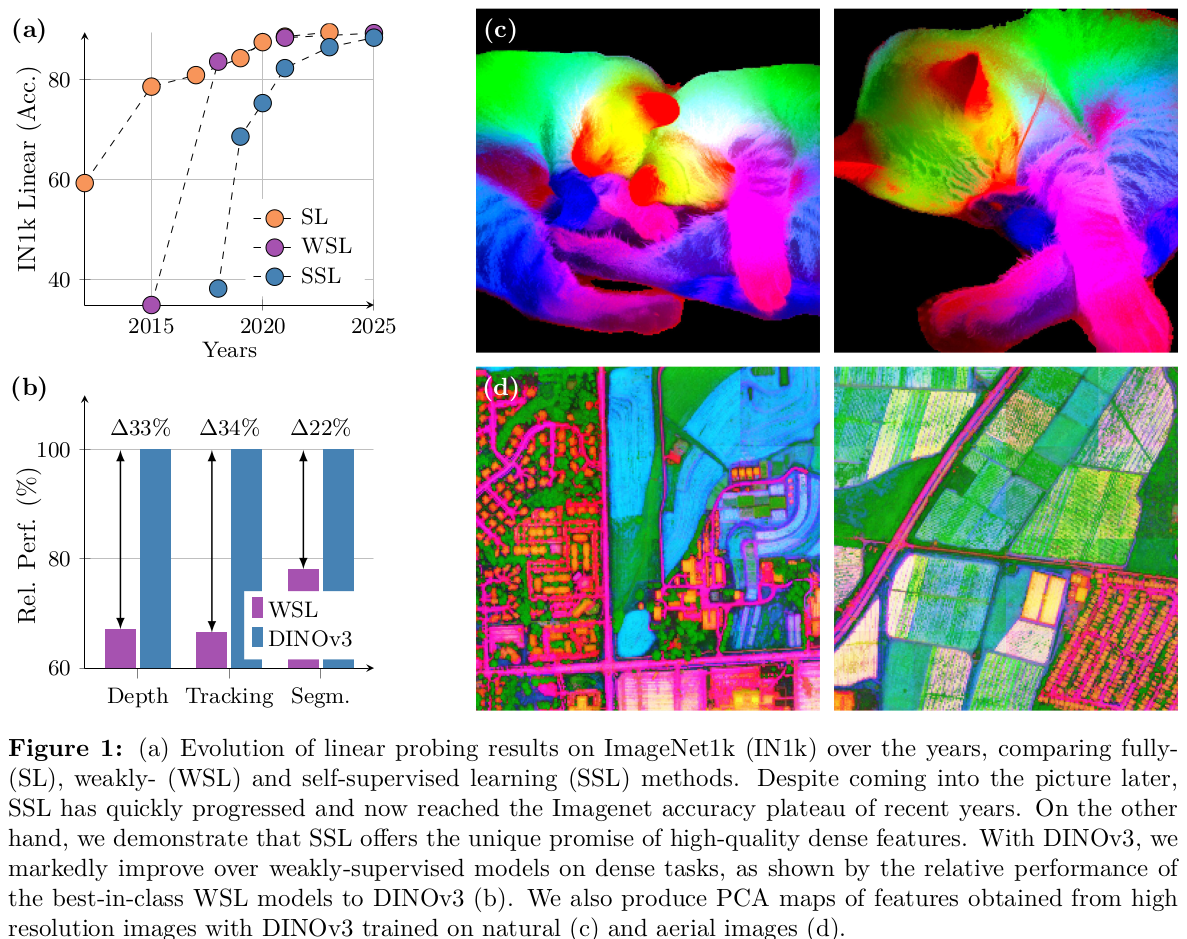
DINOv3
作者:Oriane Simeoni, Huy V. Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michael Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothee Darcet, Theo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julien Mairal, Herve Jegou, Patrick Labatut, Piotr Bojanowski 单位:Meta AI Research, WRI, Inria 会议:2025...

2026-05-20
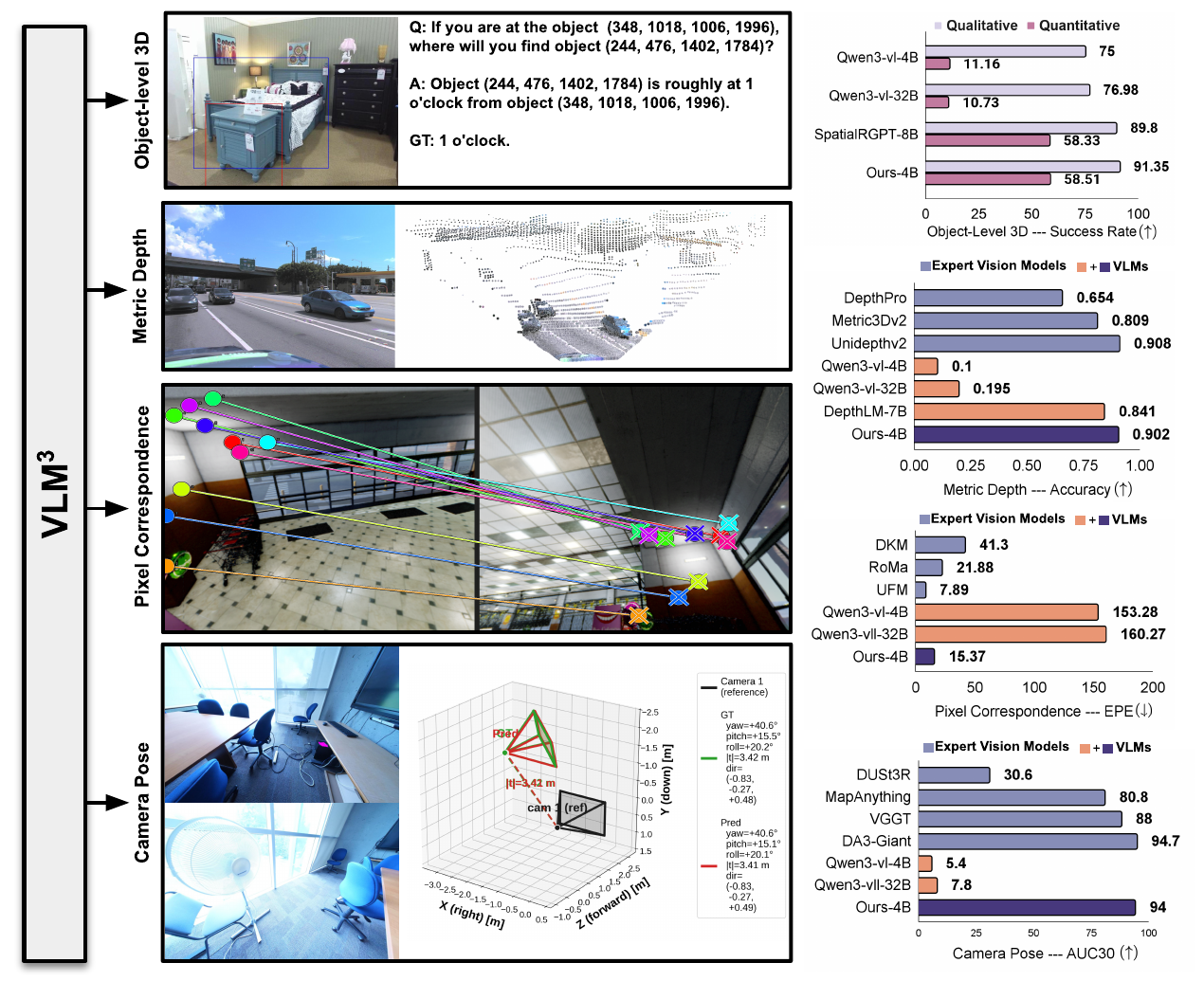
Tango3D: Towards Alignment for Global and Local 2D-3D Correspondence
作者:Zebin He, Mingxin Yang, Shuhui Yang, Hanxiao Sun, Xintong Han, Chunchao Guo, Wenhan Luo 单位:HKUST, Tencent Hunyuan 会议:2026 Arxiv 链接:https://arxiv.org/abs/2605.19727 研究动机现有 3D foundation model 很多都沿着同一条路线走:把整段点云或 shape 压成一个全局向量,再去对齐 CLIP 这类 2D 语义空间。这样做对 zero-shot 分类、shape retrieval 很有效,但它天生有一个缺口: 全局向量只保留“这是什么”,很难回答“图中这个像素在 3D 形体的哪一个局部”。 纯语义对齐能够建立 category-level matching,却无法自然支持 pixel-to-point 这种细粒度几何 grounding。 如果只追 global retrieval,3D token 本身就不需要保留局部拓扑和几何结构,这会让很多 dense downstream task...
2026-06-17
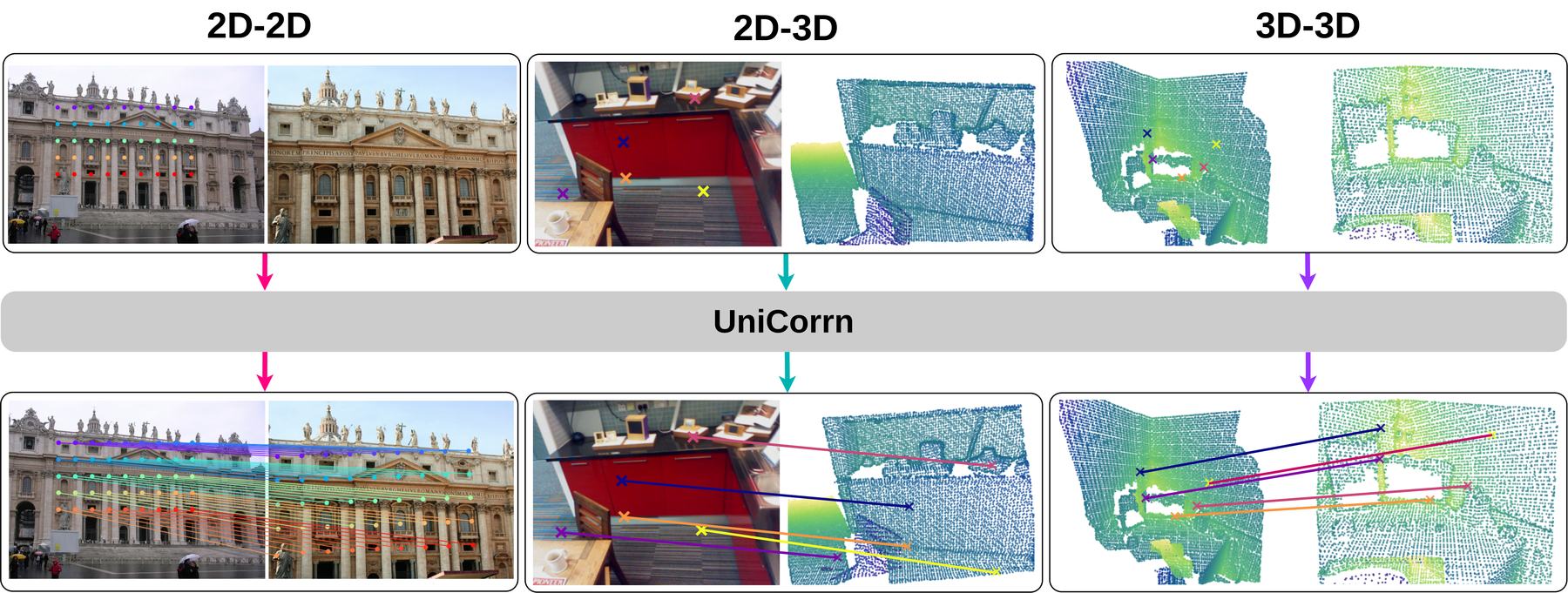
UniCorrn: Unified Correspondence Transformer Across 2D and 3D
作者:Prajnan Goswami, Tianye Ding, Feng Liu, Huaizu Jiang 单位:Northeastern University, Adobe Research 会议:CVPR 2026 链接:arXiv, Project, Code 研究动机视觉对应关系是 3D 视觉里非常底层的一类能力:给定同一场景的不同观测,模型要找出一个点在另一个观测里的对应位置。传统上这件事会按输入模态拆成三类任务:图像到图像的 2D-2D matching、图像到点云的 2D-3D matching、点云到点云的 3D-3D matching。 这篇论文想解决的问题不是单个 benchmark 的精度,而是一个更大的建模问题: 能否用一个共享权重的模型,同时处理 2D-2D、2D-3D 和 3D-3D 几何匹配? 作者认为已有路线有三个关键限制: 基于 cost volume / pyramid / recurrent refinement 的 2D...
2024-12-28
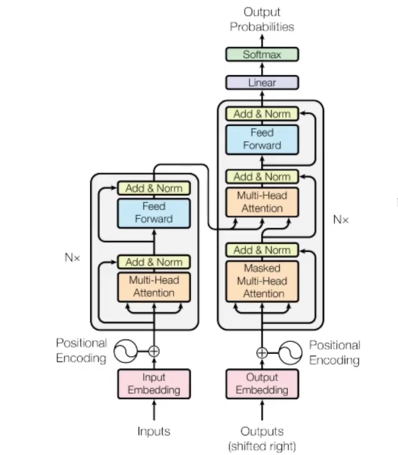
Transformer系列讲解
Transformer传统方法存在的问题传统RNN存在的问题各层之间不为独立,无法并行计算 传统word2vec存在的问题预训练好的向量不变,在不同的语境中可能存在不同的意思 整体结构EncoderAttention对于不同的数据集有不同的关注点,关注对完成任务重要的特征,是由计算机自己提取的 self-attention把上下文的一些信息加入到当前词编码的过程中,考虑整体的信息 Q:query查询矩阵,要去查询的内容;K:Key键,等待被查的V:value实际特征信息 要求当前词与其他词之间的关系,用当前词的q与各词的k内积得到相关程度,相关性越大内积越大 将分支归一化转换成对应的比例,同时不能让结果被向量本身维度所影响,并与v相乘得到最终的attention...
评论