
D4D: An RGBD diffusion model to boost monocular depth estimation

方法
阶段一
对NYU和KITTI中的RGBD样本进行预处理,进行归一化以及rescale,分辨率跟第三阶段所采用的model有关
阶段二
第二阶段对输入的RGBD进行前向和后向操作训练网络,同时通过S1和S2两种不同的训练配置,得到不同的生成数据,其中$S1$使用$L1$ loss,$β$策略采用线性策略,$S2$使用$L2$ loss,$β$采用余弦策略
最终得到的$S3$就是$S1$和$S2$的并集
最终用于后续训练的增强训练数据集由$S3$和原始的训练数据组成
阶段三
用构建的增强训练数据集对多个model进行训练
 微信
微信 支付宝
支付宝
相关推荐
2024-12-08
SSD:Stealing Stable Diffusion Prior for Robust Monocular Depth Estimation
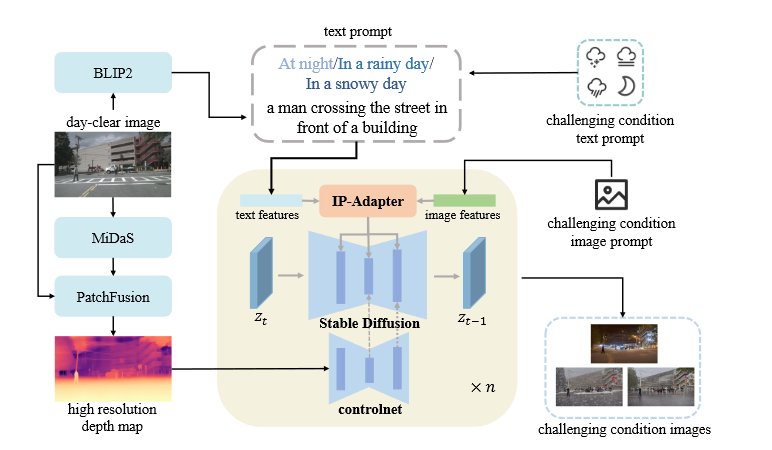
背景现有的MDE方法在标准的环境下(例如晴天)表现的很好,但是在一些具有挑战性的条件下效果会变得很差,这主要是由于一些关键的假设失效了,例如光度一致性假设,同时也没有可靠的ground truth包含这些场景。 现有的一些鲁棒的解决方案 基于模型的方法 这一方法通过修改网络结构来增强模型处理各种条件的能力 缺点:网络模型过于复杂,不能够适应各种环境 基于数据的方法 利用域自适应或其他模态的数据来增强图像信号 缺点:缺乏高质量的数据,需要后处理 方法Generative Diffusion Model-based Translation生成在深度方面与白天清晰图像非常相似的训练样本 I_{g}=S D ( I P ( T_{p}, I_{p} ), C N ( D_{h} ), z ) BILP2:获取场景描述符,保留图像内容信息 ControlNet d2i:保持近似深度一致性 MiDas:获取初始深度图 PatchFusion:获得高分辨率的深度图 text prompt=BILP2 场景描述符+challenging condition...
2024-12-08
BetterDepth: Plug-and-Play Diffusion Refiner for Zero-Shot Monocular Depth Estimation
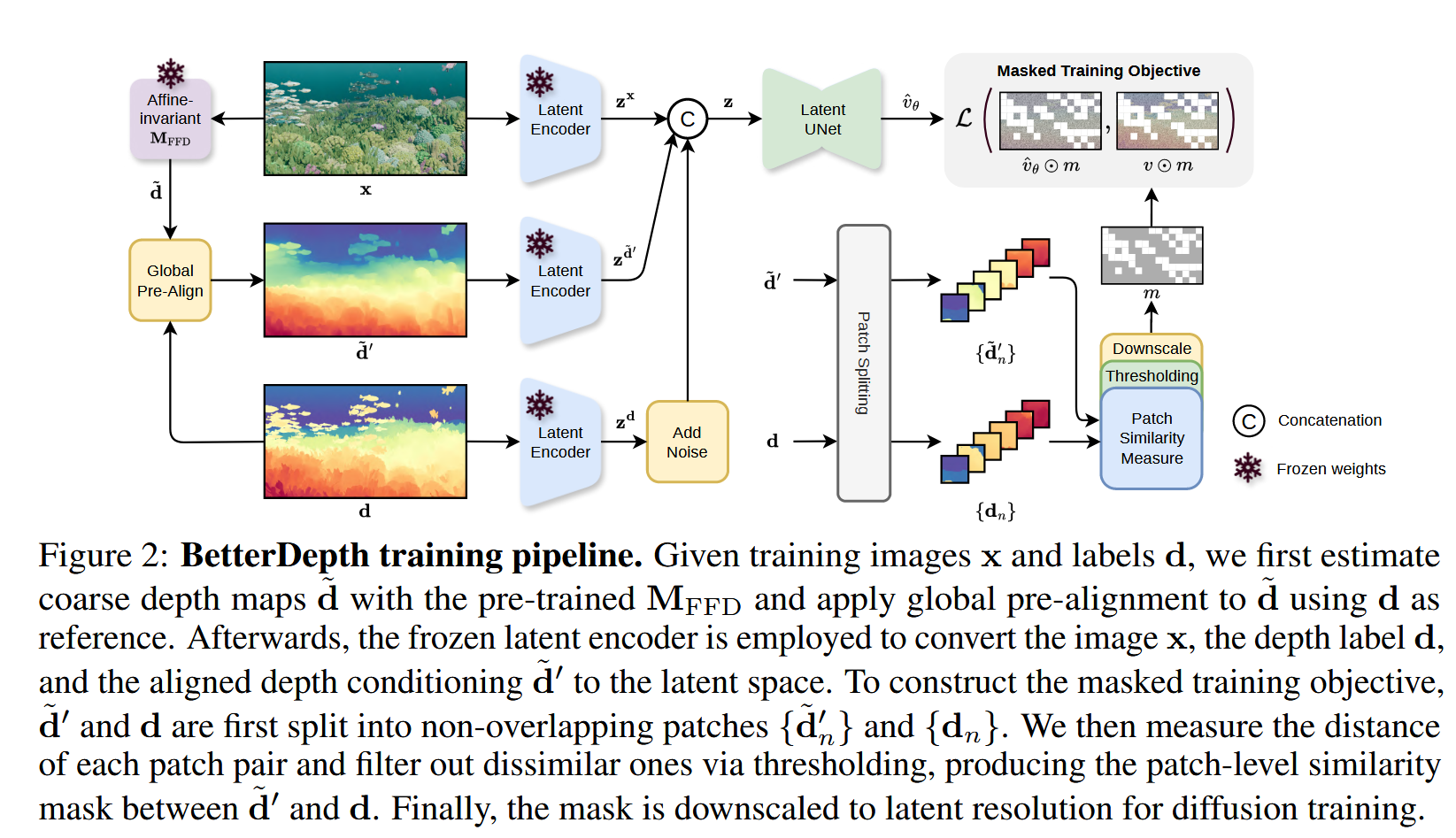
Problem Formulationfeed-forward model: {\cal L}_{\mathrm{M D E}} ( {\bf d}_{i}, {\bf M}_{\mathrm{F F D}} ( {\bf x}_{i} ) ), \tag{1}Diffusion model: {\cal L}_{\mathrm{D M}} \left( \epsilon, {\bf M}_{\mathrm{D M}} \left( {\bf x}_{i}, \mathrm{A d d N o i s e} ( {\bf d}_{i}, \epsilon, t ) \right) \right), \tag{2}Framework Global Pre-Alignment给定预训练仿射不变深度模型$\bf{M}_{FFD}$ 和数据对$\bf{(x, d)} ∈ \bf{D}_{syn}$...

2024-12-06
Depth Anywhere: Enhancing 360 Monocular Depth Estimation via Perspective Distillation and Unlabeled Data Augmentation
方法 数据清洗及合理数据掩码生成为了消除不合理像素对训练的影响,使用GroundingSAM将不合理的区域滤除。对于有效像素占比低于20%的图像也进行溢出。 教师模型对无标签图像使用立方体投影,然后用Depth Anything对投影后的patch进行预测,将360度模型的预测结果投影到立方体视图,再和Depth Anything的输出计算Loss。 随机旋转处理由于Depth Anything在立方体的每一个面上进行估计,缺乏对场景的综合理解,所以会出现伪影。 在等矩形坐标系下应用旋转矩阵: ( \hat{\theta}, \hat{\phi} )=\mathcal{R} \cdot( \theta, \phi). \tag{1}从等矩形到立方体投影,立方体每一个面的视场角等于90度,每一个面都能够看作一个焦距为$w/2$的透视相机,所有的面共用世界坐标系中的中心点。因此每一个相机的外参矩阵能够用一个旋转矩阵定义,则每个面上的像素表示为: p=K \cdot R_{i}^{T} \cdot q, \tag{2} q=\left[ \begin{matrix} q_{x}...
2024-12-06
Depth Anything v2
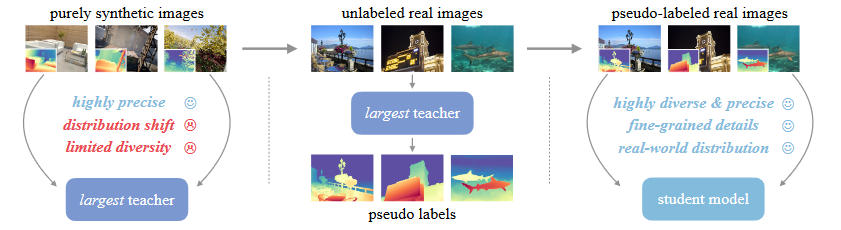
三个关键方法:1)将所有有标签的真实图像更换为合成图像 2)增强了教师模型的capacity 3)通过大规模伪标签真实图像对学生模型进行训练 真实标签数据的缺点:1)标签噪声:传感器固有的缺点、透明等场景 2)忽略的细节:边缘、洞 导致错误的估计,过度平滑的估计 合成数据的局限性:1)合成图像与真实图像之间的分布偏移 真实图像包含更多随机性,合成图像场景的布置较为有序。 2)所覆盖的场景有限,难以与真实世界的场景相匹敌 大规模无标签真实图像的作用:1)缩小合成图像与真实场景之间的领域差异 2)增大所覆盖的场景范围 3)知识迁移 sparse的gt在评估的时候真的会影响指标的可靠性么? 能否直接训练或者使用一个强大的metric depth网络来生成metric的伪标签,从而使得学生模型能够具备metric depth预测能力?
2025-03-31
Amodal Depth Anything: Amodal Depth Estimation in the Wild
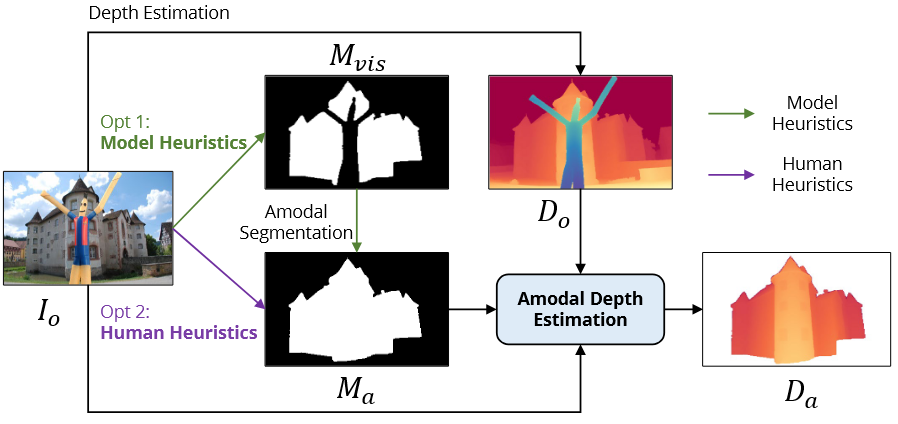
摘要Amodel 深度估计旨在预测场景中遮挡区域的物体的深度。这个任务可以解答模型是否可以根据可见的视觉线索感知到遮挡区域的几何关系。 提出了开放环境下amodel深度估计的全新范式,引入了一个新的大规模数据集Amodel Depth In the Wild(ADIW) 提出了两个互补的框架,一个基于Depth Anything V2的确定性模型AmodelDAV2,一个集成了条件流匹配原理的生成模型AmodelDepthFM 简介目前已有的方法在合成数据集上进行amodel的深度估计,但是合成数据获取成本高,与现实场景的复杂性与多样性存在差距。同时预测的绝对深度难以在数据有限的条件下泛化到未见过的场景上。 方法amodel深度估计旨在给定输入观察图像$I_o$、对应的深度图$D_o$和目标amodel分割mask $M_a$ 时,估计遮挡区域的深度值。 数据集构建 通过将对象放置在自然图像上来构建数据对。使用了图像分割数据集,相较于深度估计数据集规模更大。使用Segment...

2024-12-28
Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution
ABSTRACT提出目前存在的问题神经网络方法得到的深度图远低于1兆像素的分辨率,缺少细粒度的细节,限制了其实用性 本文方法和创新点证明了一致的场景结构和高频细节之间存在一种权衡,并利用一个简单的深度融合网络来融合低分辨率和高分辨率的估计,来利用这种二元性 采用双重估计方法提高整幅图像的深度估计,采用patch选择方法,为最终的结果添加局部细节 通过合并不同分辨率的估计以及不断变化的context,可以用预训练好的模型生成高水平细节的数百万像素深度图。 INTRODUCTION问题:单目深度估计网络的输出特性随着输入图像的分辨率改变,高分辨率的图像输入网络,能够更好地捕捉高频细节,但估计的结构一致性会降低,这种二元性源于给定模型的容量和感受野大小限制 当深度线索相比于感受野间隔太大时,模型会生成结构不一致地结果,不同区域的正确分辨率发生局部改变 本文提出(创新点)①...
最新文章




