DEPTH ANY VIDEO WITH SCALABLE SYNTHETIC DATA
构建合成视频数据集
在不同的虚拟环境中,利用synthetic engines获取深度信息,构建了一个包含40000个视频切片的数据集,涵盖室内外场景。
在部分的图像和深度图之间可能存在不对齐的现象,首先采用 scene cut 方法,根据显著颜色变化检测场景的转变,然后用深度模型去滤除掉那些指标低的视频序列。
直接过滤指标低的视频序列可能会对导致过滤到一些网络没有见过的数据,因此,进一步使用 CLIP 来计算真实深度和预测深度之间的语义相似性。
最终方法是对每个视频序列均匀采样10帧,如果语义和深度的指标都低于预先定义的阈值,就滤除该片段
生成视频深度模型
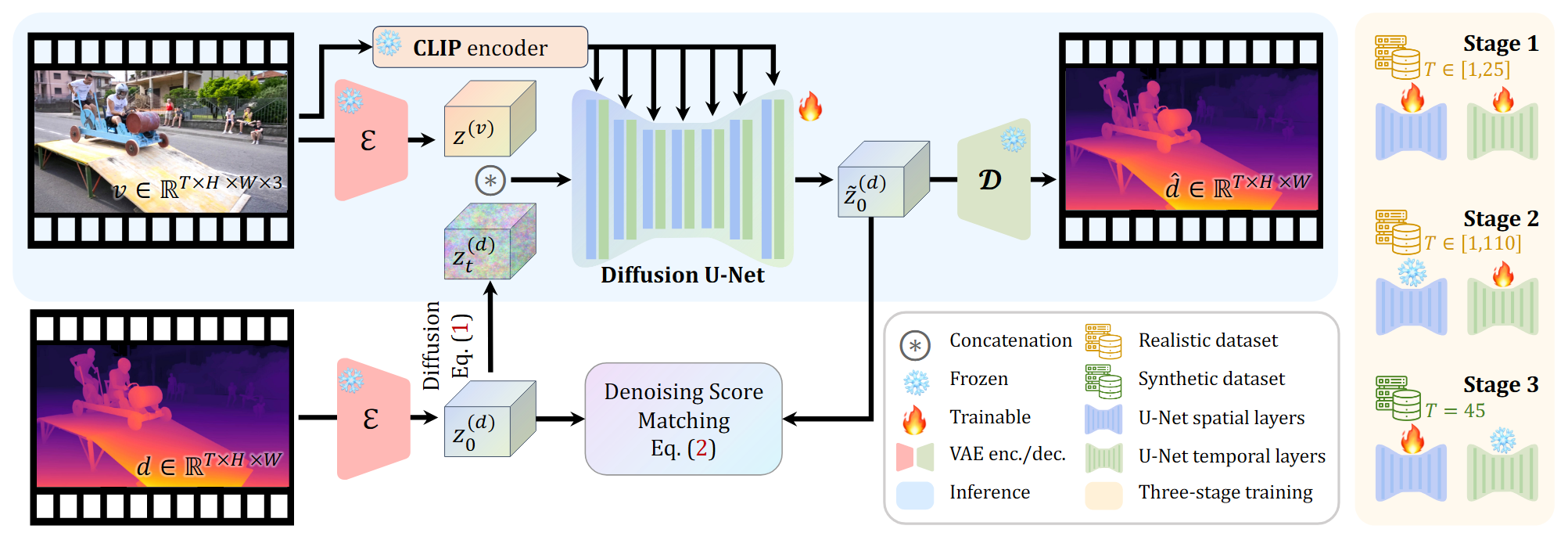
模型设计

训练和推理的过程与其他基于diffusion 的model保持一致。采用和Marigold一样的归一化方法。
由于在时间维度上进行压缩会导致运动模糊伪影,所以只在空间维度上进行压缩。
将latent video和latent depth逐帧拼接,同时移除CLIP的 embedding。
Conditional Flow Matching
为了加速去噪的过程,将原本SVD当中的EDM替换为了 conditional flow matching,能够一步得到满意的结果。
具体而言,给数据加噪的过程定义为在数据和高斯噪声之间进行线性插值:
这个公式表示了以固定速度在数据和噪声之间进行的均匀变换,对应的基于时间的,从噪声到数据的速度场定义为:
速度场定义了一个常微分方程:
为了求解这个常微分方程,可以用估计的速度场将噪声转换为数据样本。
Frame Dropout
在处理长的视频序列时能够保证训练效率
对于SVD中使用的 temporal transformer block,将其中的正弦绝对值位置编码替换为旋转位置编码。
在短视频上训练仍然难以泛化到长视频上,因此,保留长视频原始的位置索引,随机采样$K$帧进行训练。
Video Packing
若是在一个batch中只包含一个样本,对与短视频来说内存的使用效率很低。
首先将多个相同分辨率的视频列为一组进行裁切,对于每个batch,从相同的组中进行采样,并应用相同的Dropout参数$K$。对于低分辨率和短视频增加batchsize提高训练效率。
长视频推理

采用一个帧插值网络,首先在关键帧上进行预测,然后用关键帧和预测结果共同作为condition,对齐中间帧的尺度和偏移。
插值网络在上面的网络上进行微调,微调时,每一个window中的第一帧和最后一帧也作为条件输入网络。
其中$\hat{z}_d$表示预测的关键帧,mask map对于已知的关键帧来说设为1,其他帧设为0。
 微信
微信 支付宝
支付宝