DUSt3R: Geometric 3D Vision Made Easy
相关概念
Pointmap
将三维点的稠密二维场表示为pointmap $X \in\mathbb{R}^{W \times H \times3}$ ,对应分辨率为$W×H$ 的RGB图像 $I$,$X$描述了图像像素和三维场景点之间的一一对应关系。
假设每一条相机光线只会击中一个三维点,即忽略半透明表面的情况
Cameras and scene
给定相机内参矩阵$K \in\mathbb{R}^{3 \times3}$ ,pointmap就能够根据给定的ground-truth 深度图$D \in\mathbb{R}^{W \times H}$ 获得:
$X^{n,m}$表示相机$n$的pointmap $X^n$在相机$m$坐标系中的表示:
其中$P{m}, P{n} \in\mathbb{R}^{3 \times4}$ 是世界坐标系到相机坐标系的位姿,$h ~ : ~ ( x, y, z ) ~ \to~ ( x, y, z, 1 )$ 是齐次映射。
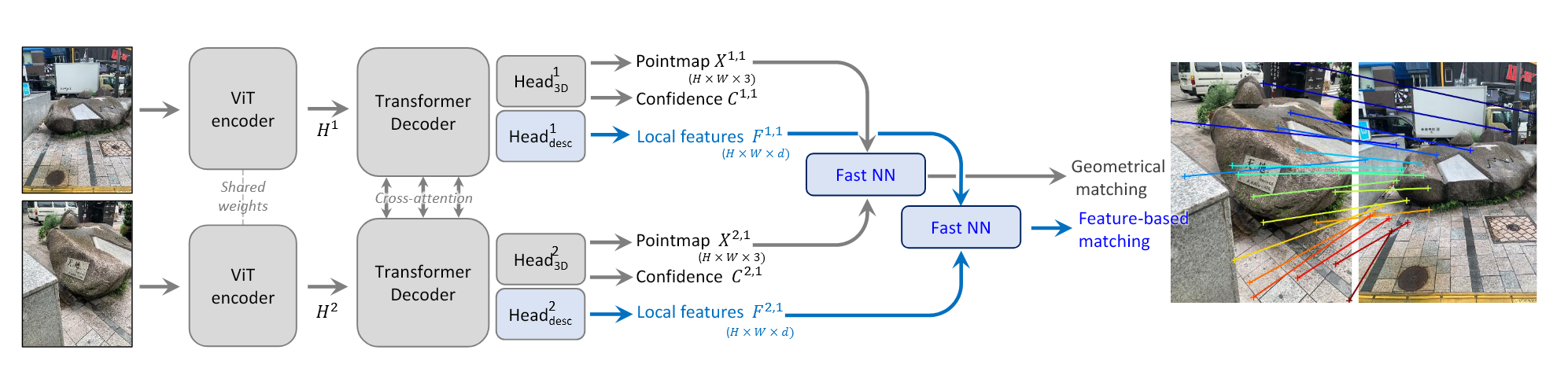
Method
input:两张RGB图像 $I^{1}, I^{2} \in\mathbb{R}^{W \times H \times3}$ ,输出对应的两张pointmap $X^{1, 1}, X^{2, 1} \in\mathbb{R}^{W \times H \times3}$ 和置信度图 $C^{1, 1}, C^{2, 1} \in\mathbb{R}^{W \times H}$ 。pointmap都是在 $I^{1}$ 的坐标系下表示的。
Network architecture

输入图像通过相同共享权重的ViT encoder得到两个token表示$F^1$ , $F^2$ :
在decoder内分别进行cross-attention 和self-attention操作,self-attention中每一个视角中的每一个token和相同视角下的其他token进行操作,cross-attention中一个视角下的一个token和另一个视角下的所有token进行操作。最后输入到MLP中。
decoder有$B$ 个blocks,$\mathrm{D e c o d e r B l o c k}_{i}^{v} ( G^{1}, G^{2} )$ 表示分支 $v$ 中的第 $i$ 个block,其中 $G^1,G^2$ 表示输入的tokens,则有:
最终每一个分支的decoder token集合分别输入到 regression head中,得到pointmap和置信度图:
输出的pointmap按道理没有尺度约束,因此尺度因子不可知,但可以在训练的时候让网络从训练集中学习到具有几何一致性的pointmap
Training Objective
3D Regression loss
设根据公式(1)得到的gt pointmap为 ${\bar{X}}^{1, 1}$ 和 ${\bar{X}}^{2, 1}$ ,regression loss为:
(只针对valid pixel)
为了解决scale ambiguity的问题,将prediction 和gt都进行归一化,缩放因子分别为 $z \,=\, \mathrm{n o r m} ( X^{1, 1}, X^{2, 1} )$ 和 $\bar{z} \,=\, \mathrm{n o r m} ( \bar{X}^{1, 1}, \bar{X}^{2, 1} )$ ,表示所有valid points到原点的平均距离:
Confidence-aware loss
在现实情况下,在天空或者半透明物体上可能会存在难以定义的三维点,因此同时也对每一个像素定义一个分数来表示网络对该像素的置信度,最终的训练目标是在valid pixels上的 confidence-weighted regression loss:

Downstream Applications
Point matching
两张图像中点的对应关系表示为:
Recovering intrinsics
pointmap $X^{1,1}$ 是在图像 $I^1$ 的坐标系中,若假设principal point近似在中心,像素是方形的,则只需要估计焦距 $f^{*}_1$ :
其中
Relative pose estimation
一种方法是用上述方法恢复内参,然后估计对极矩阵恢复相对位姿
另一种方法是用 Procrustes alignment 直接比较pointmap得到相对位姿
更加鲁棒的方法为RANSAC、PnP
Absolute pose estimation(Visual localization)
一种方法是让 $I^Q$ 表示 query image , $I^B$ (其2D-3D的对应关系是可获得的)表示reference image。首先 $I^Q$ 的内参可以从 $X^Q$ 得到,然后可以对 $I^Q$ 和 $I^B$ 之间的二维像素对应关系运行PnP-RANSAC,从而得到 $I^Q$ 的2D-3D对应关系。
另一种方法是获得两个图像的相对位姿,然后根据 $X^{B,B}$ 和 $I^B$ 的gt pointmap之间的尺度将这个位姿转换到世界坐标系下。
Global Alignment
所构建的网络只能够处理图像对,因此需要进行快速简单的后处理来构建更大的场景,使得更多预测的pointmaps能够统一到同一个三维空间当中。
Pairwise graph
给定一个图像集 ${I^{1}, I^{2}, \ldots, I^{N} } $ ,首先构建一个连通图 ${\mathcal{G}}=( {\mathcal{V}}, {\mathcal{E}} )$ ,$N$ 张图像构成了顶点 $\mathcal{V}$ ,每一条边 $e \,=\, ( n, m ) \, \in\, \mathcal{E}$ 表示了图像 $I^n$ 和 $I^m$ 之间共有的视觉内容,然后通过现有的图像检索方法或者将所有图像对通过网络计算所有图像对的平均置信度,评估重叠的部分,从而滤除掉低置信度的图像对。
Global optimization
使用连通图 $ \mathcal{G} $ 对所有相机 $n=1…N$ 恢复全局对齐的pointmap ${\chi^{n} \in\mathbb{R}^{W \times H \times3} } $,首先预测每一个图像对的pointmaps 和对应的置信度图。为了表示方便,定义 $ X^{n, e} :=X^{n, n}\quad and \quad X^{m, e} :=X^{m, n} $ ,为了将所有图像对的预测都在同一个坐标系下进行表示,所以引入每一个图像对的 pairwise pose $ P_{e} \in \mathbb{R}^{3 \times 4} $ 和 scaling $ {\sigma}_e > 0 $,则对应的优化问题描述为:
其思想就是给定一个图像对,采用相同的刚性变换应当要把两个pointmaps 和世界坐标系下的pointmaps相对齐,为了避免陷入局部最优,对任意图像对,设定
Recovering camera parameters
进一步的拓展是恢复所有的相机参数。
让
,就可以根据内参和深度图估计所有相机的位姿。
为了加快收敛,用沿着maximum spanning tree的成对相对位姿初始化参数。
 微信
微信 支付宝
支付宝