M²Depth: Self-supervised Two-Frame Multi-camera Metric Depth Estimation

MFF

STF

Depth Decoder

Adaptive Depth Sample

 微信
微信 支付宝
支付宝
相关推荐
2024-12-08
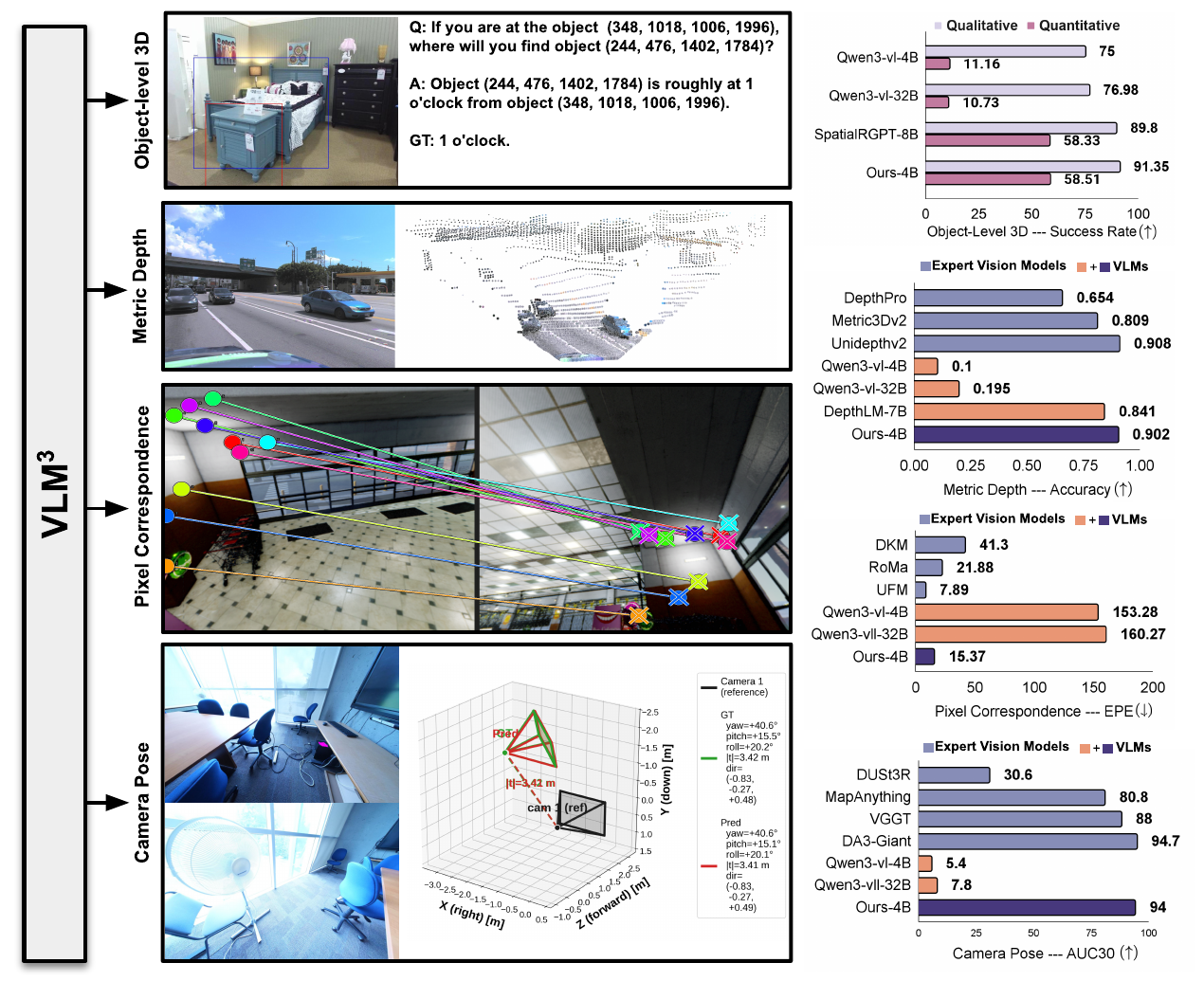
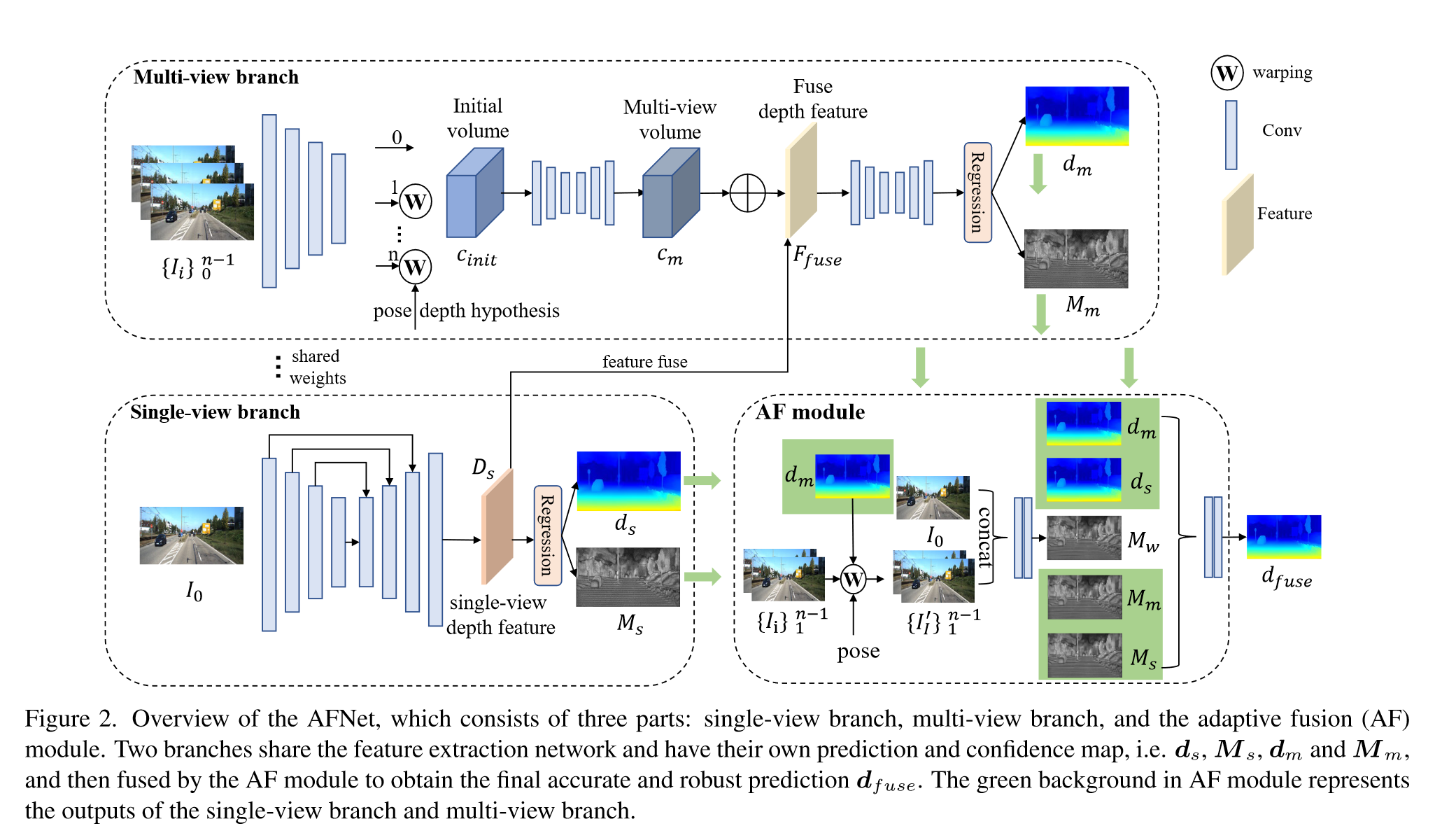
Adaptive Fusion of Single-View and Multi-View Depth for Autonomous Driving
Input: $n-1$ 个源图像 ${I_i}^{n-1}_{i=1}$、参考图像 $I_0$、相机内参和相机姿态 Output:depth $d$ Part:single-view depth module, multi-v iew depth module, adaptive fusion module and pose correction module Single-view and Multi-view Depth Module使用ConvNeXt-T作为backbone提取四个尺度上的特,征$F_{ i,l} (l = 1, 2, 3, 4)$,特征维度分别为$C=96,192,384,768$ Single-view branch采用多尺度的decoder聚合特征获得深度特征$D_s ∈ R^{H/4×W/4×257}$ 对$D_s$的前256个通道使用softmax得到depth probability volume $P_s ∈ R^{H/4×W/4×256}$,最后一个通道作为置信度图$M_s ∈...
2026-04-02
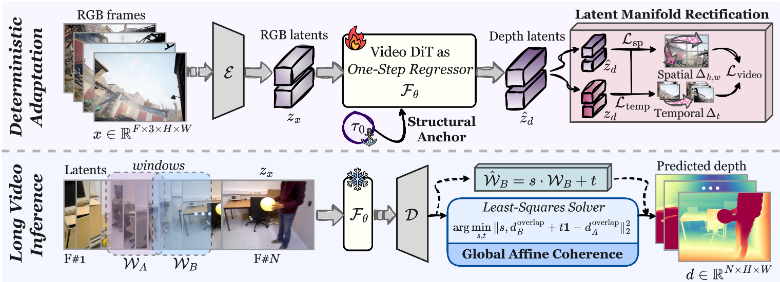
DVD: Deterministic Video Depth Estimation with Generative Priors
作者:Hongfei Zhang, Harold Haodong Chen, Chenfei Liao, Jing He, Zixin Zhang, Haodong Li, Yihao Liang, Kanghao Chen, Bin Ren, Xu Zheng, Shuai Yang, Kun Zhou, Yinchuan Li, Nicu Sebe, Ying-Cong Chen 单位:HKUST(GZ), HKUST, UCSD, Princeton University, MBZUAI, SZU, Knowin, UniTrento 会议:2026 Arxiv 链接:https://arxiv.org/abs/2603.12250 研究动机1.生成式方法具有强大的视频先验和零样本泛化能力,但容易出现随机采样带来的几何幻觉和尺度漂移 2.判别式方法虽然稳定高效,但又高度依赖大规模标注数据来消除语义歧义 3.打破这种...

2024-12-06
Depth Anywhere: Enhancing 360 Monocular Depth Estimation via Perspective Distillation and Unlabeled Data Augmentation
方法 数据清洗及合理数据掩码生成为了消除不合理像素对训练的影响,使用GroundingSAM将不合理的区域滤除。对于有效像素占比低于20%的图像也进行溢出。 教师模型对无标签图像使用立方体投影,然后用Depth Anything对投影后的patch进行预测,将360度模型的预测结果投影到立方体视图,再和Depth Anything的输出计算Loss。 随机旋转处理由于Depth Anything在立方体的每一个面上进行估计,缺乏对场景的综合理解,所以会出现伪影。 在等矩形坐标系下应用旋转矩阵: ( \hat{\theta}, \hat{\phi} )=\mathcal{R} \cdot( \theta, \phi). \tag{1}从等矩形到立方体投影,立方体每一个面的视场角等于90度,每一个面都能够看作一个焦距为$w/2$的透视相机,所有的面共用世界坐标系中的中心点。因此每一个相机的外参矩阵能够用一个旋转矩阵定义,则每个面上的像素表示为: p=K \cdot R_{i}^{T} \cdot q, \tag{2} q=\left[ \begin{matrix} q_{x}...
2024-12-06
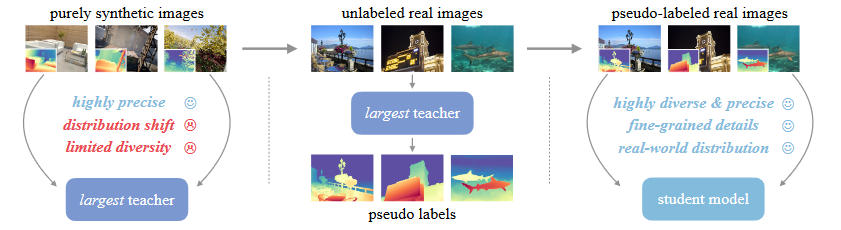
Depth Anything v2
三个关键方法:1)将所有有标签的真实图像更换为合成图像 2)增强了教师模型的capacity 3)通过大规模伪标签真实图像对学生模型进行训练 真实标签数据的缺点:1)标签噪声:传感器固有的缺点、透明等场景 2)忽略的细节:边缘、洞 导致错误的估计,过度平滑的估计 合成数据的局限性:1)合成图像与真实图像之间的分布偏移 真实图像包含更多随机性,合成图像场景的布置较为有序。 2)所覆盖的场景有限,难以与真实世界的场景相匹敌 大规模无标签真实图像的作用:1)缩小合成图像与真实场景之间的领域差异 2)增大所覆盖的场景范围 3)知识迁移 sparse的gt在评估的时候真的会影响指标的可靠性么? 能否直接训练或者使用一个强大的metric depth网络来生成metric的伪标签,从而使得学生模型能够具备metric depth预测能力?

2026-05-19
Lotus-2: Advancing Geometric Dense Prediction with Powerful Image Generative Model
作者:Jing He, Haodong Li, Mingzhi Sheng, Ying-Cong Chen 单位:HKUST(GZ), UC San Diego, HKUST 会议:2025 Arxiv 链接:https://arxiv.org/abs/2512.01030 研究动机 这篇文章讨论的是一个很尖锐的矛盾:单目几何密集预测本质上是病态问题,但现在最强的两类路线各有明显短板。 大规模判别式深度模型依赖海量监督数据,性能上限很大程度由训练集规模、真实性和标注质量决定,一旦遇到稀有场景或开放域图像,泛化就容易掉下来。 扩散/rectified-flow 这类生成模型确实在海量图文数据里学到了强 world prior,但它们原生的随机采样、多步生成和高保真图像目标,并不天然适合“同一张图稳定输出一张几何图”这种确定性任务。 如果直接把生成模型的随机生成范式搬过来,模型会出现结构方差、几何幻觉和推理开销过高的问题;但如果完全退回普通回归模型,又拿不到生成模型里蕴含的大规模几何先验。 所以 Lotus-2...

2024-12-08
NVDS+: Towards Efficient and Versatile Neural Stabilizer for Video Depth Estimation
整体网络结构与NVDS保持一致 稳定网络深度感知特征编码对于一个滑动窗口中的一组初始深度图 $F^{norm}_i={F_1,F_2,F_3,F_4}$ ,其归一化的方式为: F_{i}^{n o r m}=\frac{F_{i}-\operatorname* {m i n} \left( \mathbf{F} \right)} {\operatorname* {m a x} \left( \mathbf{F} \right)-\operatorname* {m i n} \left( \mathbf{F} \right)} \,, i \in\left\{1, 2, 3, 4 \right\}. \tag{1}将归一化后的深度图与RGB图像连接形成RGBD序列,通过transformer backbone编码成深度感知的特征图 交叉注意力模块目标帧的特征图中的像素作为query,keys和values是从参考帧中生成的。 采用了patch merging的方法,并将交叉注意力机制限制在局部窗口内,减小计算开销。 用 $T$...
评论