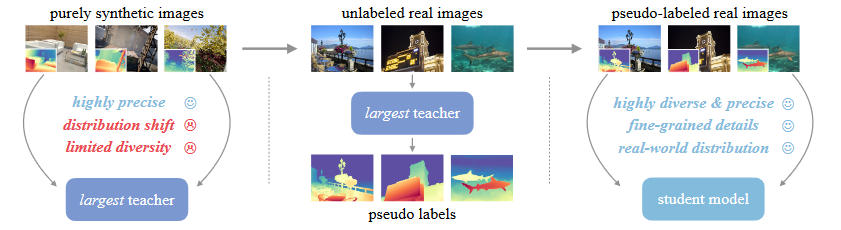
DEPTH PRO: SHARP MONOCULAR METRIC DEPTH IN LESS THAN A SECOND
思路:在不同的尺度提取patches,对patches应用ViT encoders,将patches 的预测结果融合成一个单独的高分辨率的稠密估计。
方法

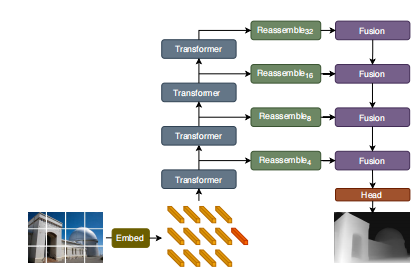
1.相对于可变分辨率的方法,将输入分辨率固定为了1536×1536,保证了足够大的感受野,防止了out-of-memory的问题。使用普通的ViT encoder,能够利用多种预训练ViT的主干网络。
2.将输入图像分成5×5个分辨率为384×384的重叠patch,下采样至786×786后分成3×3个重叠的patch。将patch链接后输入patch encoder,每一个patch得到分辨率为24×24的feature。在精细的尺度上,进一步提取中间特征。得到特征之后将特征patches融合成maps输入decoder。
Sharp 单目深度估计
训练目标
网络预测的输出为canonical inverse depth,然后通过视场角转换为metric depth
对于metric datasets,使用MAE Loss,同时对于真实世界的数据,丢弃掉误差前20%的像素点
对于non-metric datasets,先进行中值缩放,然后再计算inverse depth 的一二阶导数,定义多尺度导数损失:
平均绝对梯度误差:
平均绝对拉普拉斯误差:
均方梯度误差:
训练策略
在第一阶段,在有标签的训练数据集上进行训练,在metric的数据集和non-metric数据集的归一化数据上最小化MAE损失函数。为了使网络学习到sharp的边界信息,对合成数据集在梯度上使用尺度偏移不变损失函数。
在第二阶段,只在合成数据集上进行训练。使用MAE,MAGE,MALE,MSGE损失函数
Sharp边界的评估指标
对于相邻的像素点,可以通过其深度值之间的差异决定是否为遮挡的轮廓$c_{d} ( i, j )=\left[ \frac{d ( j )} {d ( i )} > ( 1+\frac{t} {1 0 0} ) \right]$,相应的准确率和召回率表示为:
若是通过segmentation,saliency或matting的方法获得了二值的mask,也可以定义对应的遮挡轮廓为$c_{b} ( i, j )=b ( i ) \wedge\neg b ( j )$ ,在计算召回率的时候可以此定义的遮挡轮廓来替换由深度图获得的遮挡轮廓,但是由于二值的标签通常标记的是整个对象,其遮挡轮廓可能与真实的对象轮廓不是对齐的。
焦距估计
focal length head和encoder都在深度估计训练之后再进行训练,这样可以避免深度和焦距训练之间的平衡问题,在训练的时候能够排除掉一些单一相机的数据,增加大规模的焦距监督。
 微信
微信 支付宝
支付宝