Lotus-2: Advancing Geometric Dense Prediction with Powerful Image Generative Model
作者:Jing He, Haodong Li, Mingzhi Sheng, Ying-Cong Chen
单位:HKUST(GZ), UC San Diego, HKUST
会议:2025 Arxiv
链接:https://arxiv.org/abs/2512.01030
研究动机

这篇文章讨论的是一个很尖锐的矛盾:单目几何密集预测本质上是病态问题,但现在最强的两类路线各有明显短板。
大规模判别式深度模型依赖海量监督数据,性能上限很大程度由训练集规模、真实性和标注质量决定,一旦遇到稀有场景或开放域图像,泛化就容易掉下来。
扩散/rectified-flow 这类生成模型确实在海量图文数据里学到了强 world prior,但它们原生的随机采样、多步生成和高保真图像目标,并不天然适合“同一张图稳定输出一张几何图”这种确定性任务。
如果直接把生成模型的随机生成范式搬过来,模型会出现结构方差、几何幻觉和推理开销过高的问题;但如果完全退回普通回归模型,又拿不到生成模型里蕴含的大规模几何先验。
所以 Lotus-2 真正想回答的问题是:
能不能把预训练图像生成模型里的几何与语义先验,改造成一个稳定、确定、细节又足够锐利的几何预测器,而不是把它继续当成随机图像生成器来用?
作者给出的答案是一个两阶段 deterministic framework:
- 第一阶段先做结构正确的 core predictor,确保全局几何稳定。
- 第二阶段再做 constrained detail sharpening,只负责补高频细节,不再破坏第一阶段已经建立好的结构。
核心方法

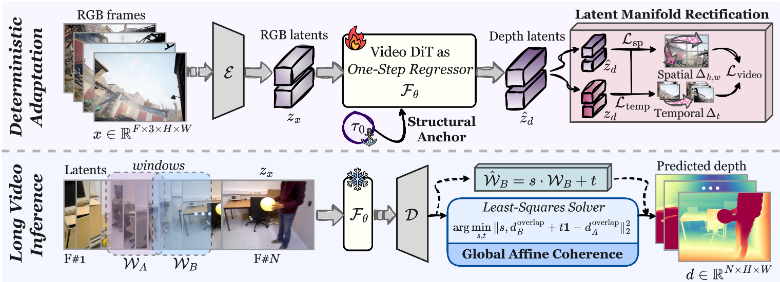
Lotus-2 的核心不是“再设计一个新的生成 backbone”,而是把预训练 FLUX 的 rectified-flow 形式系统地改造成适配几何预测的确定性协议。作者最终保留的 core predictor 有三个关键判断:
从随机 flow 改成 deterministic flow。输入不再是噪声到标注,而是图像 latent 到几何 latent 的确定性映射,这样同一张图不会因为随机初始化不同而跑出不同结构。
从 multi-step sampling 改成 single-step prediction。作者的消融表明,当监督数据只有 59K 时,多步训练既难优化又容易累积误差;直接退化成一步预测反而更稳定、更准。
从 residual prediction 改成 clean-data prediction。作者认为 residual 会让模型同时学习“重建图像外观”和“预测几何目标”,高频纹理、光照和颜色会泄漏到几何结果里;直接预测干净 annotation 更符合任务本身。
对应的核心预测形式可以概括成:
这里的关键不是公式复杂,而是把原来生成模型里的时间步、噪声轨迹和多步采样都裁掉,只保留“世界先验 + 单步几何回归”这一最有效的部分。

另一个很实用的细节是 LCM。FLUX 内部有 Pack-Unpack 操作,原本是为降低生成模型计算量服务的,但在几何任务里会带来局部网格状伪影。Lotus-2 没有粗暴删除 Pack-Unpack,而是在 Unpack 后面补一个轻量 local continuity module:
- 保留原始 backbone 的预训练特征空间,不破坏世界先验。
- 只用很小的局部卷积模块修复空间不连续。
- 既消除 grid artifact,又不明显牺牲效率。
这一步很像在说:生成模型的先验是有价值的,但其“为生成而生”的局部结构副作用要被显式修补,不能直接照搬。

只做一步 core predictor 还有一个明显问题:结构是对的,但细节会偏粗。于是作者把第二阶段单独设计成 detail sharpener。它不是重新从噪声生成一遍,而是在 core predictor 给出的粗预测流形内,学习从 coarse annotation 到 fine annotation 的受限 rectified flow:
这个设计背后的逻辑很清楚:
- 第一阶段负责“别错”,保证结构正确。
- 第二阶段负责“更细”,只补边界、纹理和局部高频细节。
- 因为 refinement 发生在受限流形里,所以它比直接多步生成更不容易产生几何幻觉。

最终推理流程也非常克制:
- 输入图像编码到 VAE latent。
- Core predictor 用单步回归给出结构正确但略粗的几何结果。
- Detail sharpener 再做最多 10 步的 deterministic refinement。
- 最后再解码回像素空间。
这篇文章最值得记住的点在于,它不是把“生成模型做几何”理解成更复杂的采样过程,而是把生成模型理解成一种可被萃取的 deterministic world prior。
数据集
Lotus-2 的一个亮点就是数据量极小,但训练目标非常明确。
- 训练只用约 59K synthetic samples。
- Hypersim 提供约 39K 室内样本,统一 resize 到
576 x 768。 - VKITTI 提供约 20K 街景样本,裁剪到
352 x 1216。 - Detail sharpener 的训练不是直接再读新标注,而是先让 core predictor 在 Hypersim 和 VKITTI 上生成 coarse prediction,再学习 coarse 到 fine 的 refinement。
评测集分成两类:
- 深度估计:NYUv2、KITTI、ETH3D、ScanNet、DIODE。
- 法向估计:NYUv2、ScanNet、iBims-1、Sintel。
这些测试集都没有出现在训练中,因此文章主打的是 zero-shot generalization,而不是 in-domain 拟合。
算力
论文把训练配置交代得比较清楚:
- 整个模型基于预训练 FLUX 微调,不使用文本条件。
- Core predictor 使用单步设置
T = 1,detail sharpener 使用T' = 10。 - 优化器是 Adam,学习率为
1e-4。 - 训练使用
8 x NVIDIA H100 80G,总 batch size 为64。 - 为了更便宜地适配大模型,作者使用 LoRA:深度任务 rank 为
128,法向任务 rank 为256。 - 深度预测在 disparity space 中建模,推理时 core predictor 只需一步,而 detail sharpener 最多再做 10 步 Euler refinement。
这套配置说明作者的重点不是把推理速度压到极限,而是找到一个“生成先验可用、训练数据很少、结果稳定可靠”的平衡点。
实验结果

Table I 是本文最硬的结果。Lotus-2 在 zero-shot affine-invariant monocular depth estimation 上拿到了新的 SoTA:
- 只用
59K样本,Avg. Rank 做到3.6,显著优于大量 74K 到数百万样本训练的模型。 - 在 KITTI 上达到
6.7 AbsRel / 94.5 δ1,在 ETH3D 上达到4.6 AbsRel / 98.1 δ1,都是全表最优或并列最优级别。 - 在 DIODE 上
22.1 AbsRel / 75.2 δ1,也说明它不只是在常见 indoor benchmark 上有效,对 mixed/complex scenes 仍有竞争力。
这张表真正说明的不是“Lotus-2 在每个指标都绝对第一”,而是:把生成模型改造成 deterministic prior 以后,可以用极少数据拿到非常强的深度泛化能力。

法向估计上,Lotus-2 没有像深度那样全面统治,但依然很强:
- Avg. Rank 为
2.9,属于 highly competitive,而不是勉强可用。 - 在 Sintel 上达到
30.3 mean / 27.6 within 11.25°,是表中最强结果之一。 - 在 iBims-1 上
70.4与 MoGe-2 并列最好,说明它对局部表面细节的建模确实有效。
也就是说,这套 deterministic adaptation 不只是学到“深度图纹理”,而是对几何密集预测整体都有帮助。

定性结果更能说明两阶段设计为什么成立。只用 core predictor 时,结果已经结构正确,但边界和高频纹理偏糊;直接做 Deterministic-DA 多步预测时,虽然更锐,但容易出现几何幻觉;加上 sharpener 以后,Lotus-2 的边界、栏杆、桌椅细节都更清晰,同时没有把整体几何拉歪。
这张图很重要,因为它证明第二阶段不是“让图更花”,而是在不破坏结构正确性的前提下,把细节补回来。

Table III 则把整套设计拆开验证了一遍:
- 从 Stochastic-DA 到 Deterministic-DA,首先证明“几何预测必须去随机化”。
- 再加 single-step formulation,说明少步数不是退步,而是在小数据条件下更好优化。
- 再加 clean-data prediction,证明它不仅更直接,还能避免外观纹理干扰。
- 再加 LCM,既去掉 grid artifact,又继续提升准确率。
- 最后一行 detail sharpener 则说明:锐化步骤基本保持了 core predictor 的结构精度,同时补回了高频细节。
这张表几乎就是全文论证链条的浓缩版。

作者还专门做了频谱分析。这个实验虽然不如 benchmark 直观,但很有说服力:
- Core predictor 的高频能量明显衰减,说明它确实“稳但粗”。
- Lotus-2 加上 sharpener 后,高频段功率恢复,说明第二阶段真的在补细节,而不是随意修改低频结构。
- Deterministic-DA 也保留高频,但它的问题是容易幻觉;Lotus-2 则是在受限流形里补高频,因此更稳。
所以论文的结论可以概括成一句话:第一阶段解决结构正确性,第二阶段解决高频保真度,而不是用同一个随机生成过程同时硬扛这两件事。
优势与不足
优势
观点很清楚:不是“让生成模型帮忙做几何”,而是“把生成模型里的 deterministic world prior 抽出来做几何”。
两阶段拆分合理。Core predictor 管结构,detail sharpener 管细节,任务边界清楚,所以优化逻辑也更稳定。
数据效率非常强。只用 59K synthetic samples 就能在深度估计上打到 SoTA,这比单纯扩大监督数据更有启发性。
LCM 这种小模块很工程化。它不试图推翻原 backbone,只修补 Pack-Unpack 带来的局部副作用,设计干净有效。
不足
文章的主结果最强的是 affine-invariant depth,法向估计虽然很强,但还不是绝对统治,这说明方法对不同几何任务的收益并不完全一致。
Detail sharpener 仍然需要额外多步 refinement,虽然比原始生成采样轻很多,但推理并没有回到极致的一步完成。
训练数据虽然少,但 backbone 本身依赖的是大型预训练生成模型 FLUX,因此“少数据”并不等于“低门槛复现”。
方法当前主要验证的是 depth 和 normal。若扩展到更复杂的几何任务,如 scene flow、surface reconstruction 或多视图几何,还需要进一步证明这套 deterministic adaptation 仍然成立。
记忆点
生成模型对几何任务最有价值的部分,不是随机采样能力,而是其中隐含的 deterministic world prior。
小数据条件下,多步 flow 不一定更强;Lotus-2 的结论恰恰是 single-step core predictor 更适合结构正确性。
Clean-data prediction 是一个非常关键的改动,它把“预测几何”从“预测残差 + 去外观干扰”里解耦出来了。
第二阶段 sharpener 的价值,不是把结果修得更花,而是在受限几何流形里恢复高频细节。
这篇文章提供了一条很值得复用的思路:先把 foundation model 改造成稳定回归器,再单独补高频细节,而不是一开始就追求端到端随机生成式的全能方案。
 微信
微信 支付宝
支付宝