
BetterDepth: Plug-and-Play Diffusion Refiner for Zero-Shot Monocular Depth Estimation
Problem Formulation
feed-forward model:
Diffusion model:
Framework

Global Pre-Alignment
给定预训练仿射不变深度模型$\bf{M}_{FFD}$ 和数据对$\bf{(x, d)} ∈ \bf{D}_{syn}$ ,先预测粗糙的深度图$\bf{\widetilde{d}}=\bf{M}_{FFD}(x)$,估计尺度$s$和偏移量$b$对$\bf{\widetilde{d}}$进行对齐:
VAE Encoder将$\bf{x, \widetilde{d}^{‘}, d}$转换到潜在空间,然后对$\bf{d}$加噪声得到$\bf{z}^{d}_t$和$\bf{z^x,z^{\widetilde{d}^{‘}}}$连接输入UNet训练。
Local Patch Masking
将$\bf{\widetilde{d}^{‘}, d}$分为多个patch,然后计算对应patch的欧氏距离比较patch之间的相似性:
mask:
Inference Strategies

精细的细节是diffusion model 带来的么,如果不是的话,diffusion 的部分是不是也可以更换为传统的回归模型
 微信
微信 支付宝
支付宝
相关推荐
2024-12-06
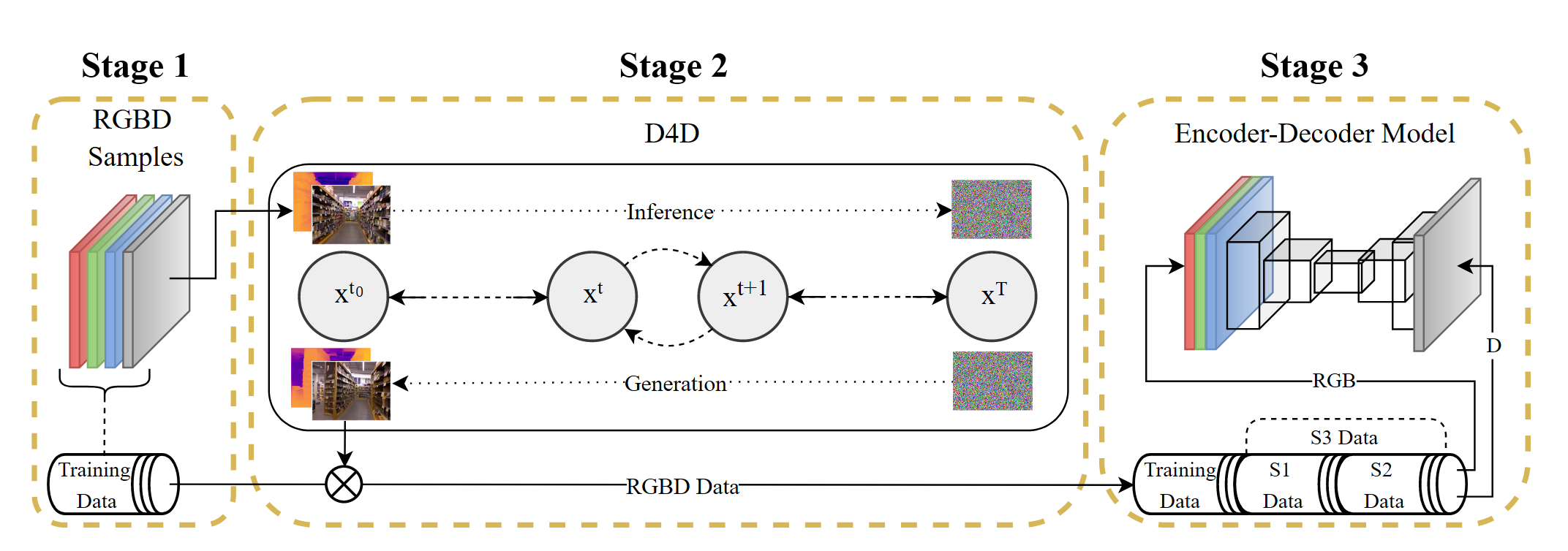
D4D: An RGBD diffusion model to boost monocular depth estimation
方法阶段一对NYU和KITTI中的RGBD样本进行预处理,进行归一化以及rescale,分辨率跟第三阶段所采用的model有关 阶段二第二阶段对输入的RGBD进行前向和后向操作训练网络,同时通过S1和S2两种不同的训练配置,得到不同的生成数据,其中$S1$使用$L1$ loss,$β$策略采用线性策略,$S2$使用$L2$ loss,$β$采用余弦策略 S 1 : L 1=\frac{1} {| \mathcal{P} |} \sum_{p \in\mathcal{P}} | | x_{p}-y_{p} | |_{1}, \; \; \beta=l i n e a r \tag{3} S 2 : L 2=\frac{1} {| \mathcal{P} |} \sum_{p \in\mathcal{P}} | | x_{p}-y_{p} | |_{2}^{2}, \; \; \beta=c o s i n e \tag{4}最终得到的$S3$就是$S1$和$S2$的并集 S 3=( s 1 \cup s 2 ) \; w h e r e \begin{cases} S 1...
2024-12-06
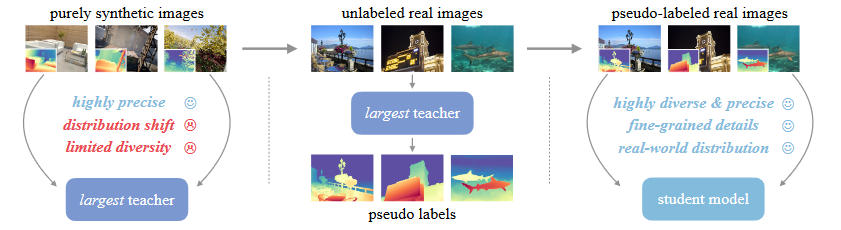
Depth Anything v2
三个关键方法:1)将所有有标签的真实图像更换为合成图像 2)增强了教师模型的capacity 3)通过大规模伪标签真实图像对学生模型进行训练 真实标签数据的缺点:1)标签噪声:传感器固有的缺点、透明等场景 2)忽略的细节:边缘、洞 导致错误的估计,过度平滑的估计 合成数据的局限性:1)合成图像与真实图像之间的分布偏移 真实图像包含更多随机性,合成图像场景的布置较为有序。 2)所覆盖的场景有限,难以与真实世界的场景相匹敌 大规模无标签真实图像的作用:1)缩小合成图像与真实场景之间的领域差异 2)增大所覆盖的场景范围 3)知识迁移 sparse的gt在评估的时候真的会影响指标的可靠性么? 能否直接训练或者使用一个强大的metric depth网络来生成metric的伪标签,从而使得学生模型能够具备metric depth预测能力?
2024-12-08
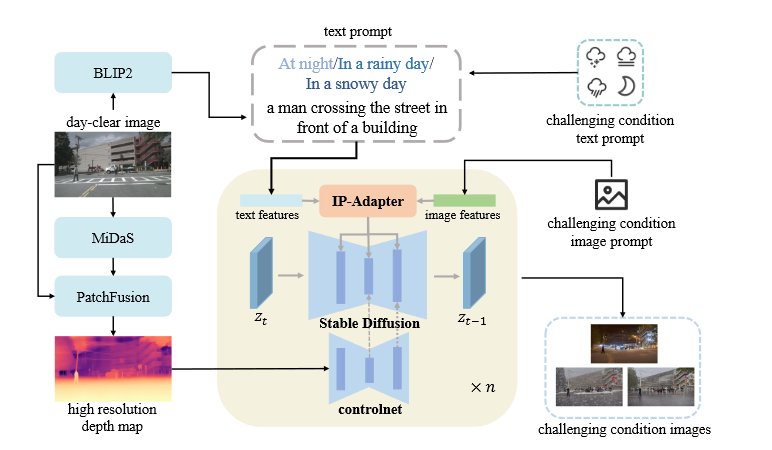
SSD:Stealing Stable Diffusion Prior for Robust Monocular Depth Estimation
背景现有的MDE方法在标准的环境下(例如晴天)表现的很好,但是在一些具有挑战性的条件下效果会变得很差,这主要是由于一些关键的假设失效了,例如光度一致性假设,同时也没有可靠的ground truth包含这些场景。 现有的一些鲁棒的解决方案 基于模型的方法 这一方法通过修改网络结构来增强模型处理各种条件的能力 缺点:网络模型过于复杂,不能够适应各种环境 基于数据的方法 利用域自适应或其他模态的数据来增强图像信号 缺点:缺乏高质量的数据,需要后处理 方法Generative Diffusion Model-based Translation生成在深度方面与白天清晰图像非常相似的训练样本 I_{g}=S D ( I P ( T_{p}, I_{p} ), C N ( D_{h} ), z ) BILP2:获取场景描述符,保留图像内容信息 ControlNet d2i:保持近似深度一致性 MiDas:获取初始深度图 PatchFusion:获得高分辨率的深度图 text prompt=BILP2 场景描述符+challenging condition...
2025-03-26
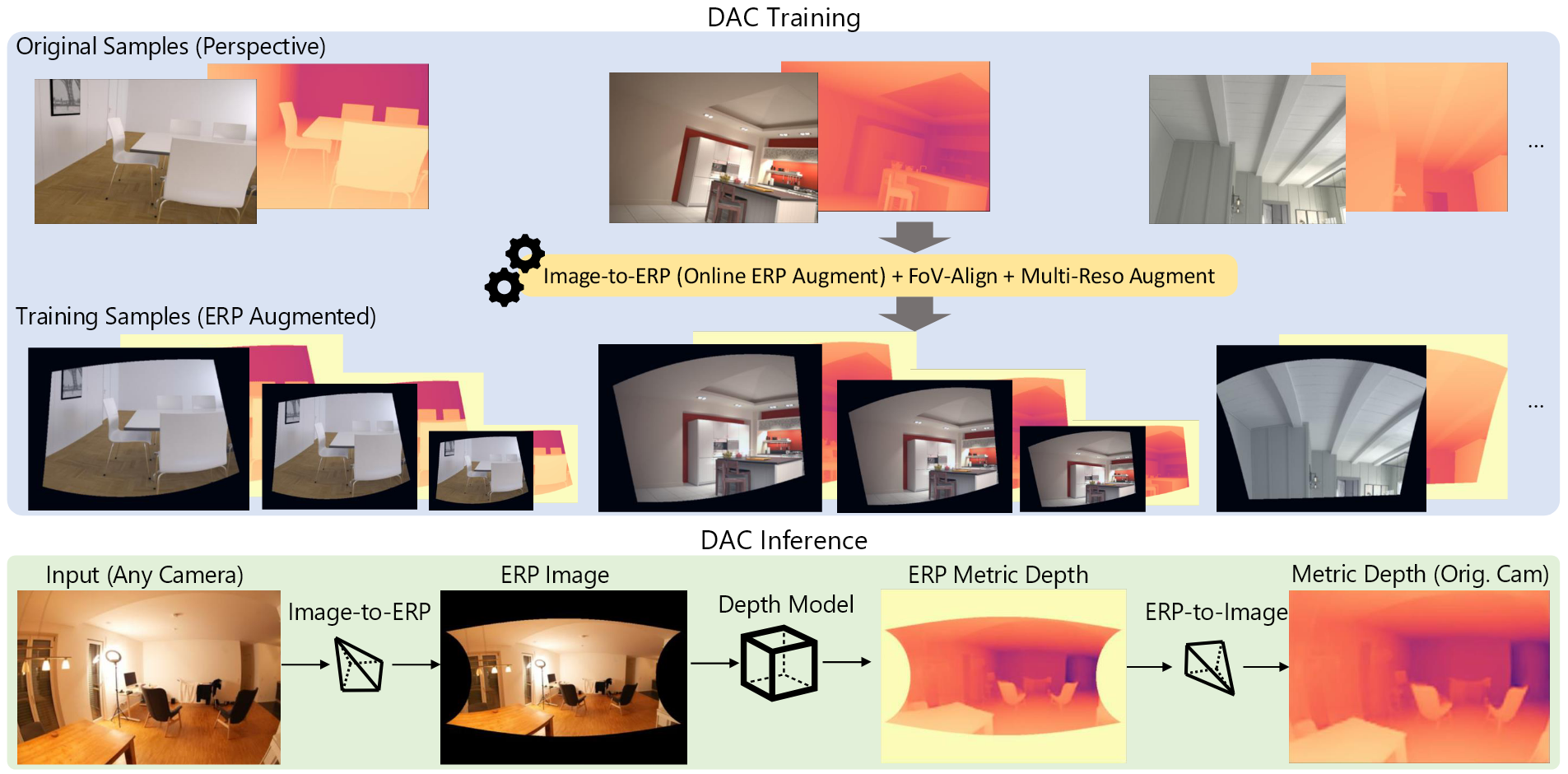
Depth Any Camera: Zero-Shot Metric Depth Estimation from Any Camera
摘要虽然当前的深度基础模型展现出了强大的泛化能力,但对于不同的相机类型要获得精确的绝对深度仍然是一个具有挑战性的问题,尤其是对于大视场角的相机,例如鱼眼和360度相机。 提出了一个零样本的的绝对深度估计框架Depth Any...
2024-12-06
DEPTH PRO: SHARP MONOCULAR METRIC DEPTH IN LESS THAN A SECOND
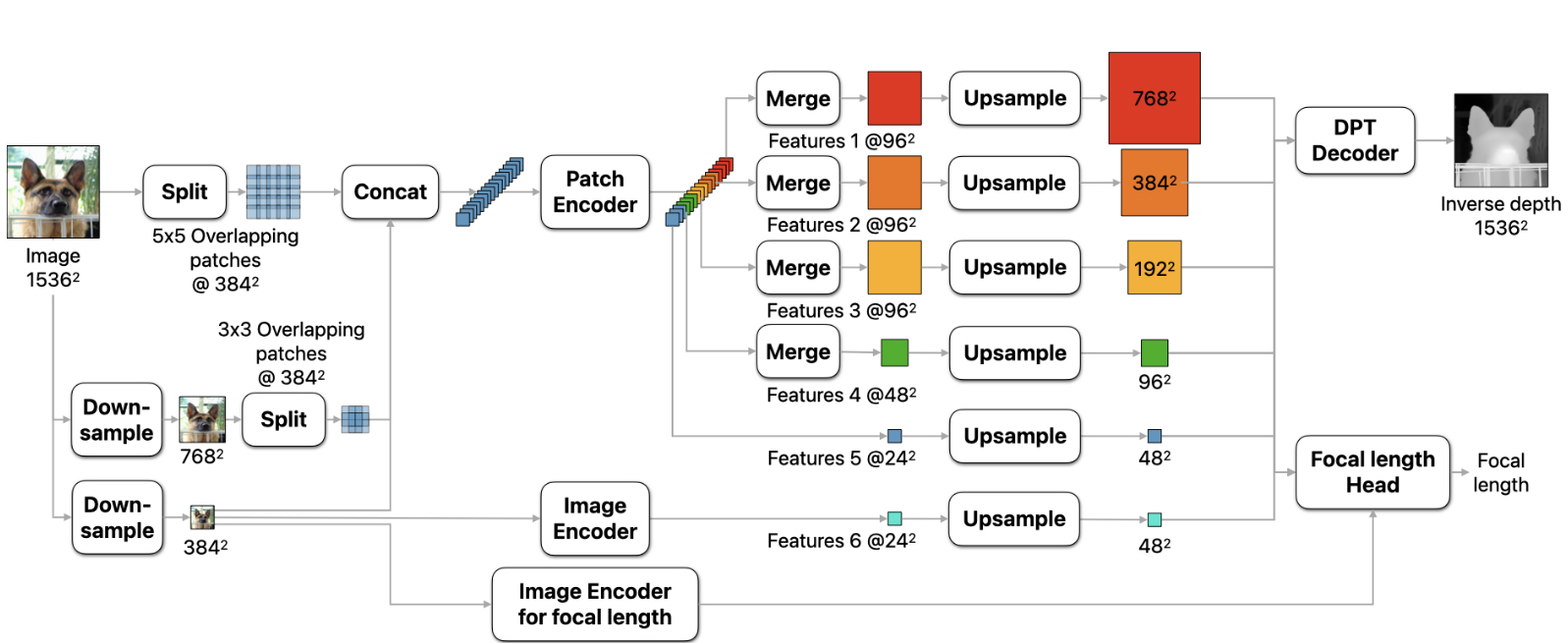
思路:在不同的尺度提取patches,对patches应用ViT encoders,将patches 的预测结果融合成一个单独的高分辨率的稠密估计。 方法 1.相对于可变分辨率的方法,将输入分辨率固定为了1536×1536,保证了足够大的感受野,防止了out-of-memory的问题。使用普通的ViT encoder,能够利用多种预训练ViT的主干网络。 2.将输入图像分成5×5个分辨率为384×384的重叠patch,下采样至786×786后分成3×3个重叠的patch。将patch链接后输入patch encoder,每一个patch得到分辨率为24×24的feature。在精细的尺度上,进一步提取中间特征。得到特征之后将特征patches融合成maps输入decoder。 Sharp 单目深度估计训练目标网络预测的输出为canonical inverse depth,然后通过视场角转换为metric depth D_m=\frac{f_{px}}{wC}对于metric datasets,使用MAE...
2024-12-08
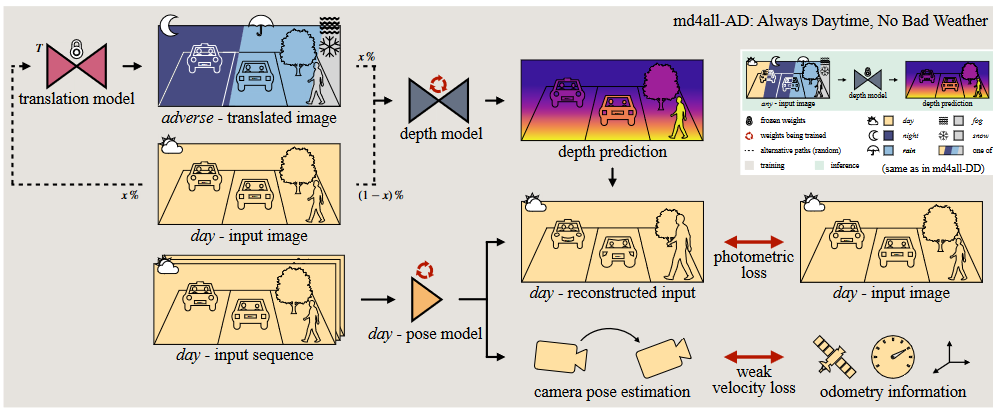
md4all:Robust Monocular Depth Estimation under Challenging Conditions
md4all-AD: Always Daytime, No Bad Weather输入图像经过depth model得到prediction,然后将源图像warp到目标视角中,利用monodepth2中的最小重投影误差L_p进行监督,忽略静态像素。 {\mathcal{L}}_{1} ( I_{t}, {\hat{I}}_{t} )=\left\| I_{t}-{\hat{I}}_{t} \right\|_{1} {\cal L}_{\mathrm{S S I M}}=1-\mathrm{S S I M} \left( I_{t}, \hat{I}_{t} \right) p e \left( I_{t}, \hat{I}_{t} \right)=\left( 1-\alpha\right) {\mathcal{L}}_{1} ( I_{t}, \hat{I}_{t} )+{\frac{\alpha} {2}} {\mathcal{L}}_{\mathrm{S S I M}} ( I_{t}, \hat{I}_{t} ) \mathcal{L}_{p} \left(...
最新文章




