Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models
摘要
具有Transformer架构的潜在扩散模型在生成高保真图像方面表现出色。然而近期的研究揭示了这种两阶段设计中的优化困境:虽然增加视觉 tokenizers 中每一个 token 的特征维度能够改善重建质量,但是需要更大的扩散模型和更多的训练迭代来实现可比的生成性能。

现有的系统得到的是次优的解决方案,由于 tokenizers 中信息的损失会产生视觉伪影,由于高昂的计算成本而无法完全收敛。
上述困境来源于学习无约束高维潜在空间的固有困难。
提出在训练视觉 tokenizers 的时候将潜在空间和预训练的视觉基础模型相对齐。提出VA-VAE(视觉基础模型对齐的变分自编码器),使DiT在高维潜在空间获得更快地收敛。
构建了增强的DiT基线,改善了训练策略和结构设计,称为LightingDiT。
贡献
提出的视觉基础模型对齐损失解决了潜在扩散模型中的优化困境,使DiT在高维 tokenizers上的训练快2.5倍
整体系统在64个训练epochs内能够达到2.11的FID,相较于原来的DiT收敛速度提升了21倍
整体系统在ImageNet-256图像生成上达到了最佳的FID分数1.35
方法:将VAE与视觉基础模型对齐

VA-VAE,一个通过视觉基础模型对齐训练的视觉 tokenizer
网络结构基于LDM,使用了VQGAN模型结构,是连续的潜在空间,由KL损失约束
关键贡献在于视觉基础模型对齐损失, VF Loss的设计,包含两个部分:边际余弦相似损失和边际距离矩阵相似损失
边际余弦相似损失
在训练过程中,给定图像 $I$ 通过视觉tokenizer编码器和冻结的视觉基础模型处理,分别得到图像的潜在表示 $Z$ 和基础视觉表示 $F$ 。使用一个线性变换对 $Z$ 进行投影来匹配 $F$ 的维度。其中 $W\in\mathbb{R}^{d_f\times d_z}$,得到 $Z^{\prime}\in\mathbb{R}^{d_f}$
边际余弦相似损失 $\mathcal{L}_{mcos}$ 最小化在每个空间坐标 $(i,j)$ 上,由特征矩阵 $Z’$ 和 $F$ 得到的特征 $z’_{ij}$ 和 $f_{ij}$ 之间的相似性差距。对每一对计算余弦相似性 $\frac{z_{ij}^{\prime}\cdot f_{ij}}{|z_{ij}^{\prime}||f_{ij}|}$,再减去一个边缘量 $m_1$ 。ReLU函数确保只有相似性低于 $m_1$ 的特征对对损失有贡献,最终的损失是在 $h \times w$ 的特征网格上所有位置的平均。
边际距离矩阵相似损失
使特征对的相对分布距离矩阵尽可能相似,对齐特征矩阵 $z$ 和 $f$ 之间的内在分布
其中 $N=h \times w$ 表示每一个展平的特征图中元素的总体数量。对每一对 $(i,j)$ ,计算特征矩阵 $z$ 和 $f$ 的对应向量之间的余弦相似性的绝对值。同样减去一个边缘量 $m_2$松弛约束。ReLU函数确保只有相似性低于 $m_2$ 的特征对对损失有贡献。
自适应加权
原本的重建损失和KL损失都是累加损失,导致VF损失难以调整其权重达到稳定训练。因此采用了自适应的加权机制。在反向传播前,计算 $L_{vf}$ 和 $L_{rec}$ 在编码器最后一个卷积层的梯度。自适应的权重设置为这两个梯度的比例,确保 $L_{vf}$ 和 $L_{rec}$ 在模型的优化上有相同的影响。
采用自适应权重可以快速对齐VF损失在不同VAE训练流程里的尺度。
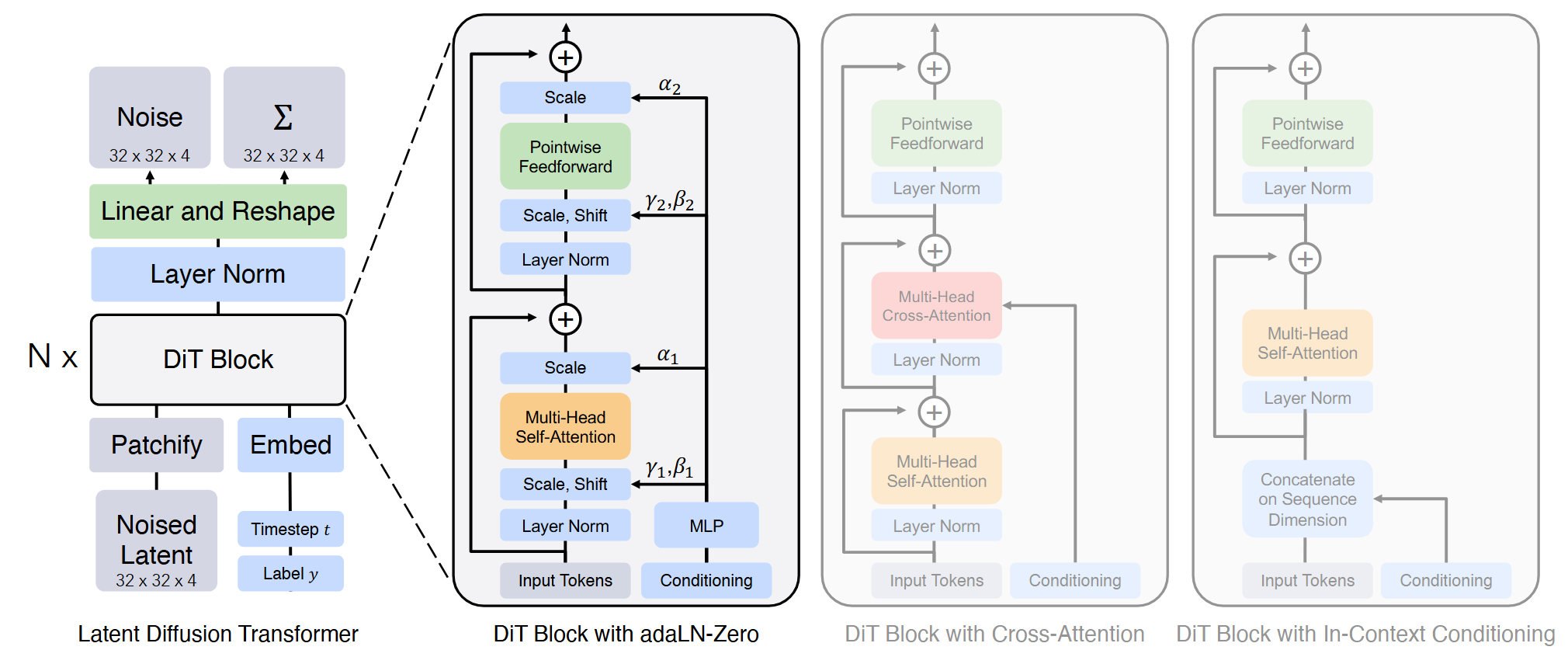
改进Diffusion Transformer
使用f8d4规格的SD-VAE作为视觉tokenizer,并使用DiT-XL/2作为实验模型。

采用了三种优化策略:
在计算层面,采用了torch.compile和bfloat16加速训练。增加batch size并减少AdamW的 $\beta_2$ 为0.95.
在扩散优化方面,纳入了Rectified Flow,对数正态分布采样和速度方向损失
在模型结构层面,使用了常见的Transformer优化方法,包括RMSNorm,SwiGLU和RoPE。


 微信
微信 支付宝
支付宝