Amodal Depth Anything: Amodal Depth Estimation in the Wild
摘要
Amodel 深度估计旨在预测场景中遮挡区域的物体的深度。这个任务可以解答模型是否可以根据可见的视觉线索感知到遮挡区域的几何关系。
提出了开放环境下amodel深度估计的全新范式,引入了一个新的大规模数据集Amodel Depth In the Wild(ADIW)
提出了两个互补的框架,一个基于Depth Anything V2的确定性模型AmodelDAV2,一个集成了条件流匹配原理的生成模型AmodelDepthFM
简介
目前已有的方法在合成数据集上进行amodel的深度估计,但是合成数据获取成本高,与现实场景的复杂性与多样性存在差距。同时预测的绝对深度难以在数据有限的条件下泛化到未见过的场景上。
方法
amodel深度估计旨在给定输入观察图像$I_o$、对应的深度图$D_o$和目标amodel分割mask $M_a$ 时,估计遮挡区域的深度值。
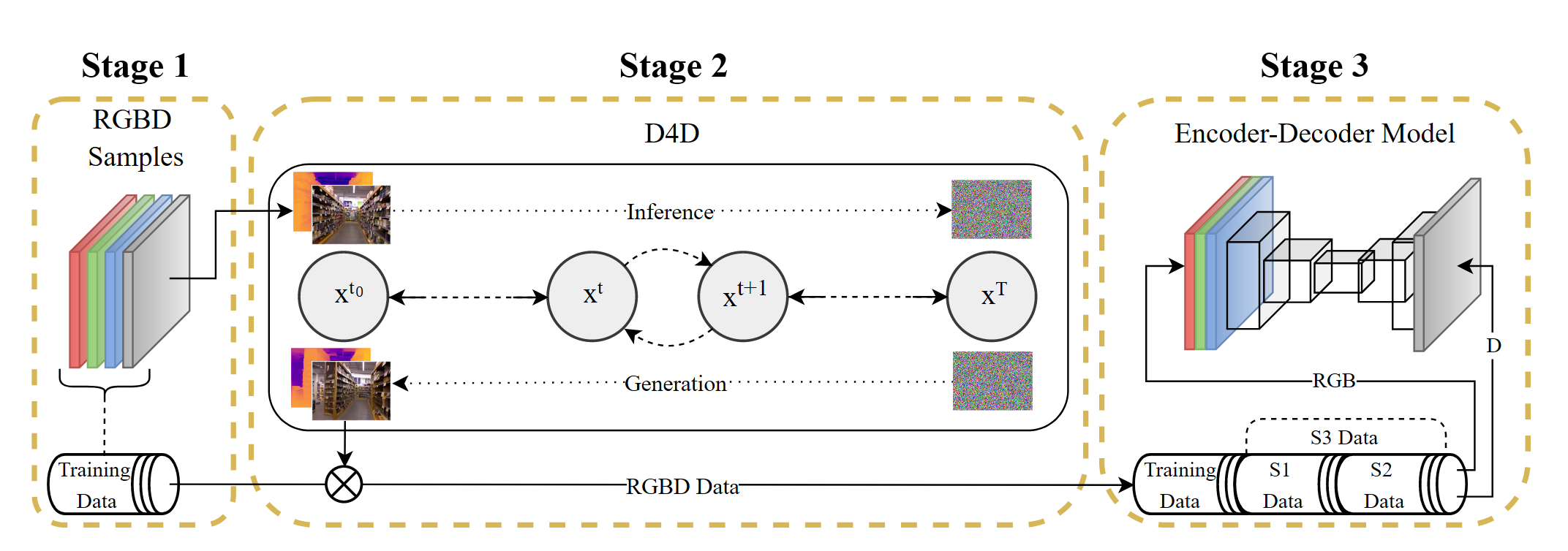
数据集构建

通过将对象放置在自然图像上来构建数据对。使用了图像分割数据集,相较于深度估计数据集规模更大。使用Segment Anything模型生成SA-1B数据集的分割mask。才有启发式算法来滤除不完整的对象。每一个背景图像$I_b$至少包含一个完整的对象。然后选取一个遮挡对象$I_f$(前景图像),将其叠加到$I_b$上,组成观察图像$I_o$。$I_o$和$I_b$都经过Depth Anything V2获得相对深度图$D_o$和$D_b$。为了确保一致的训练标签,采用尺度偏移对齐算法来对齐背景物体的深度值和两个深度图,尺度因子$s$和便宜因子$t$由下式计算:
其中$d^o_i$和$d^b_i$分别表示两个深度图背景部分的可视部分像素的深度值,$N$表示背景部分可见mask $M_{vis}$ 的合理像素的总数,对其的深度图$D_{aligned}$由下式计算:
Amodel DAV2

天界了一个引导卷积层平行于RGB卷积层,使得编码器能够接受深度图$D_o$和amodel mask $M_a$的课外引导通道。为了确保与预训练模型的相容性,引导卷积层的权重初始化为0,使得模型一开始忽略额外的引导信息。此外对DPT head的输入特征添加了层归一化来稳定训练改善收敛情况。
训练方法
使用标准的尺度不变损失作为目标函数
其中 $g_i = \log \tilde{d}_i - \log d_i$。在训练的时候是对整个遮挡区域的对象深度进行监督,不仅仅是遮挡部分,这样可以使得模型更好地理解整体的场景结构。
Amodel-DepthFM

目标函数:
在训练时,将高斯噪声$\mathcal{N}(x, \sigma_{min})$引入数据样本,因此,条件概率路径建模为$p_t(x|z) = \mathcal{N}(x|tx_1 + (1 - t)x_0, \sigma^2_{\min} \mathbf{I})$ 。在U-Net中,修改了输入卷积层的通道维度来接受引导信息。为了有效使用预训练模型,将首个卷积层的权重初始化为最初的八通道和0初始化的权重的组合。








 微信
微信 支付宝
支付宝