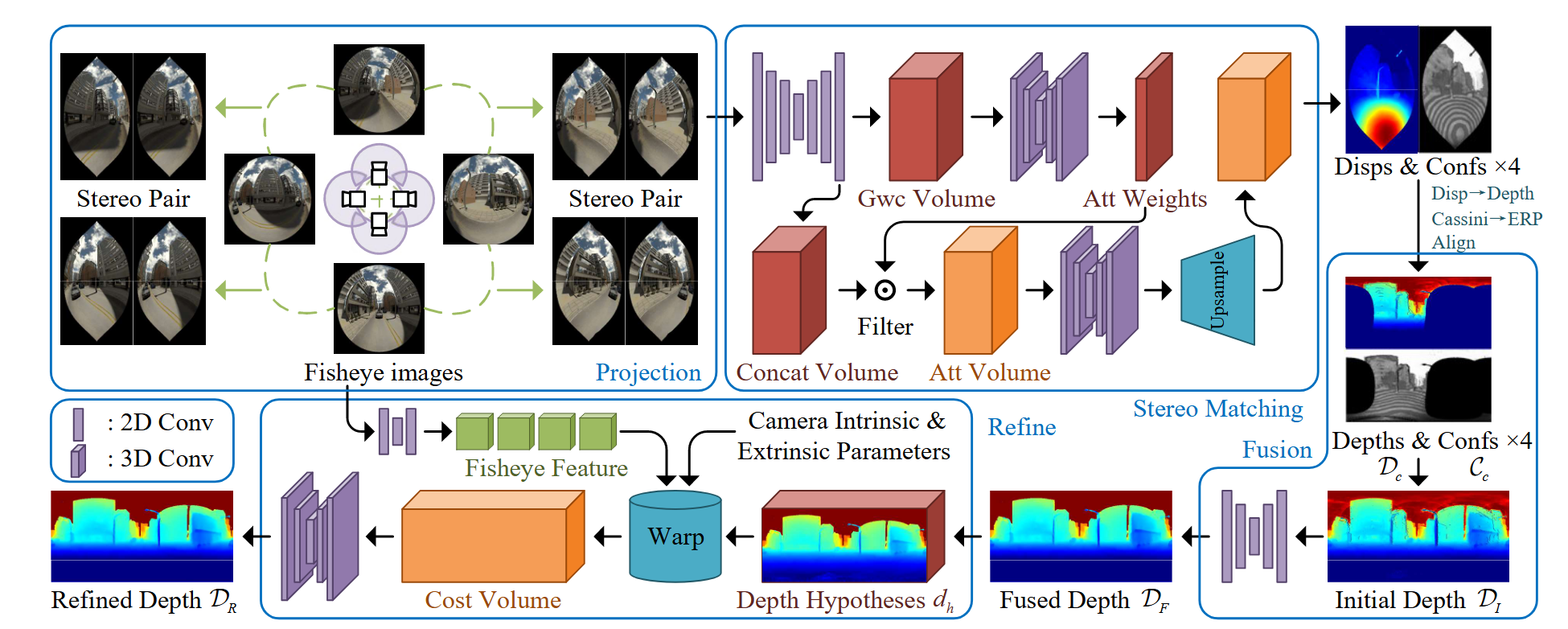
WildRayZer: Self-supervised Large View Synthesis in Dynamic Environments
作者:Xuweiyi Chen, Wentao Zhou, Zezhou Cheng
单位:University of Virginia
会议:2026 CVPR
链接:https://wild-rayzer.cs.virginia.edu/
研究动机
现有自监督新视角合成方法均基于三维场景静态假设
核心方法

1.构造动态数据集
通过挖掘网络手持影像构建动态数据集D-RE10K
2.融合DINOV3特征的伪运动标签构建

3.mask动态物体进行render
数据集
- Dynamic RealEstate-10K
- D-RE10K-iPhone
- RealEstate10K
算力
4张H100
实验结果




优势与不足
优势
- 完全自监督
- 拓展了自监督NVS在动态场景中的应用
不足
- 所预测的运动mask质量仍有待提高,对于特殊的纹理,如人影等仍然work得不好,部分分割与欠分割
- 并不算是真正的动态场景重建,并不能够将动态的物体重建出来
记忆点
- Unposed
- 用COCO数据集的物体标签直接复制粘贴到图像中,以增强模型对随机物体的鲁棒性
- DINOV3特征能够加快收敛,预测结果更加Sharp
 微信
微信 支付宝
支付宝
相关推荐
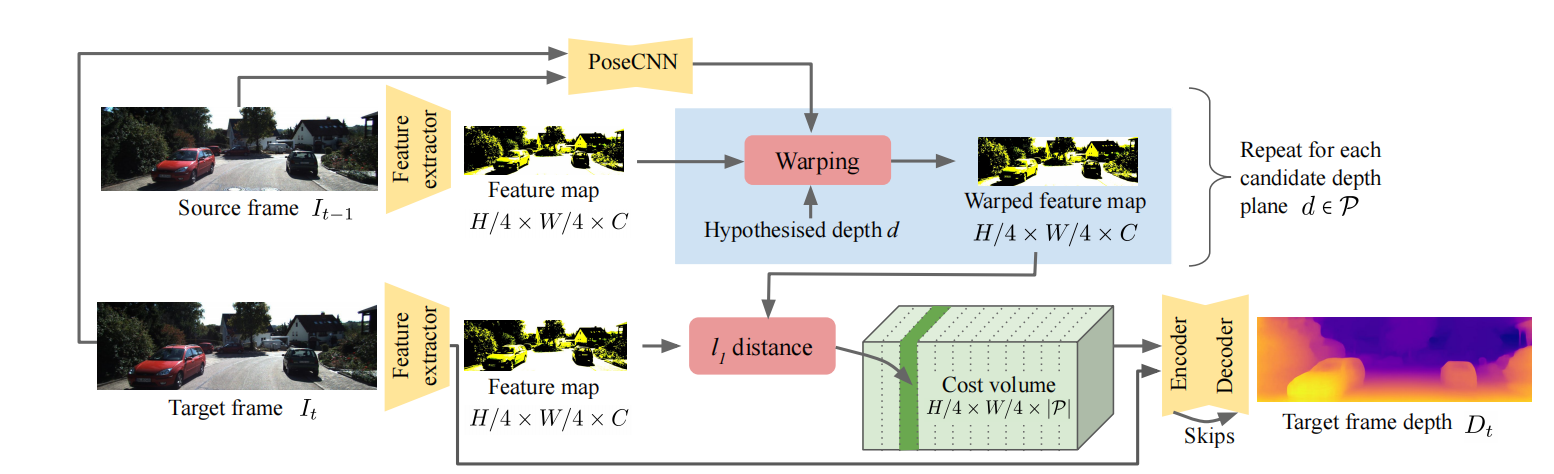
2024-12-28
The Temporal Opportunist: Self-Supervised Multi-Frame Monocular Depth
ABSTRACT提出目前存在的问题对于许多应用来说,视频帧的序列信息在测试阶段也可以获得,但大多数单目网络没有使用这个额外的信号,忽略了重要的信息;这些方法要么在测试阶段使用计算量大的细化技术,要么采用非循环网络,间接使用那些本就可获得的几何信息。 本文方法和创新点提出了ManyDepth,一种自适应的稠密深度估计方法,能够在测试阶段利用序列信息。 提出了一个端到端的cost volume,基于只用自监督训练的方法 采用了一个新的一致性损失,当cost volume不可靠时忽略它 实验效果提升在KITTI和Cityscape上的实验表明我们的方法比所有已发布的自监督baseline都要好,包括那些在测试阶段使用单帧或多帧的方法。 INTRODUCTION问题:在测试阶段,实际情况下可以得到不止一帧,而现有的单目方法没有使用这些额外的帧 将子监督训练直接应用于多视角平面扫描立体结构会产生较差的结果 本文提出(创新点)① 在训练和测试阶段都使用这些额外的帧来对多帧的深度估计系统进行自监督 ②...
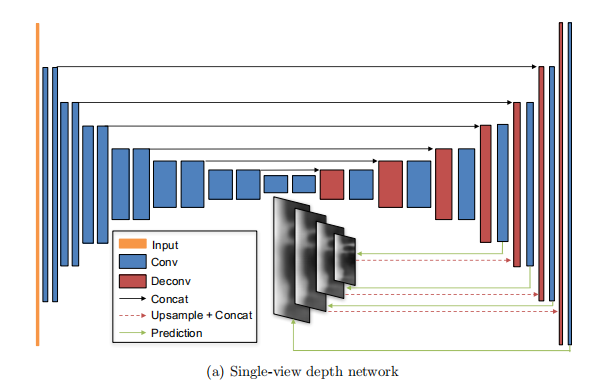
2024-12-28
Unsupervised Learning of Depth and Ego-Motion from Video
ABSTRACT本文方法和创新点提出了一个无监督学习框架用于单目深度和相机运动估计任务 使用了单视角深度网络和多视角位姿网络,利用计算的深度和位姿将附近的视角扭曲到目标视角上,定义了一个损失 实验效果提升在单目深度估计上的性能与有监督的方法相当 在相当的输入的情况下,位姿估计的新能要优于已建立的SLAM系统 INTRODUCTION问题:多年的研究还不能够使得对真实世界场景的建模能力与人类水平相当 几何视角合成系统只有当它对场景几何及相机位姿的中间预测和物理ground-truth一致时,其表现才能一致良好。 本文提出(创新点)① 训练了一个模型,观察图像序列,并通过预测可能的相机运动和场景结构来解释其观察。 ② 采用了一种端到端的方法,能够从输入像素直接预测自运动(用六自由度的变换矩阵参数化表示),得到场景结构(用一个参考视角下的逐像素的深度图表示) RELATED WORKStructure from...
最新文章