Repurposing Geometric Foundation Models for Multi-view Diffusion
作者:Wooseok Jang, Seonghu Jeon, Jisang Han, Jinhyeok Choi, Minkyung Kwon, Seungryong Kim, Saining Xie, and Sainan Liu
单位:KAIST AI ,New York University ,Intel Labs
会议:2026 Arxiv
链接:https://cvlab-kaist.github.io/GLD
研究动机
1.早期的生成式方法虽然能够生成逼真的图像,但是往往在几何上不一致
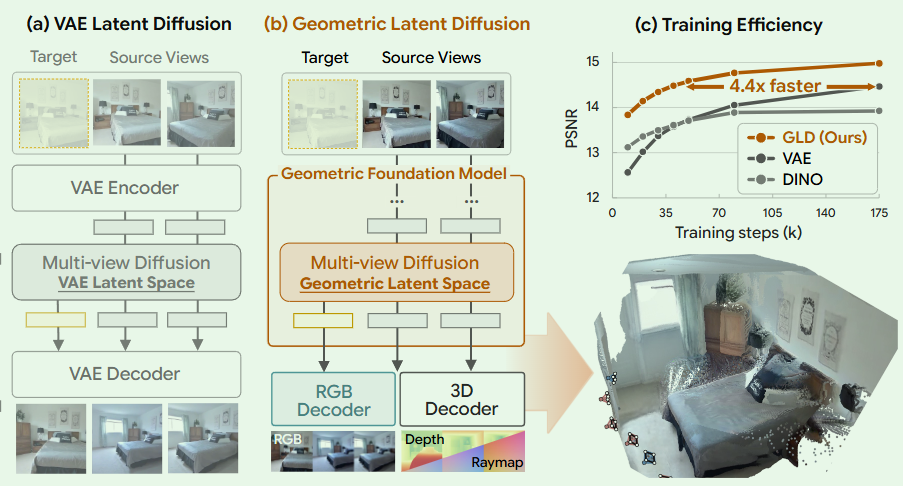
2.使用一个已经将几何结构编码进去的潜在空间,来进行新视角的生成
3.几何基础模型的特征空间可以作为新视角合成的有效潜在空间
核心方法

1.验证几何特征的重建能力
训练一个基于ViT的解码器,将DA3的特征用来重建RGB图像,通过随机mask单独特征,迫使解码器从部分输入进行重建

2.Multi-view Diffusion与Boundary Layer
深层特征可以由浅层特征推导出来,所以只需要在某一boundary的特征上进行合成即可。所以训练了四个彼此独立的扩散模型来评估最优的boundary是哪一个。
source图像的特征由冻结的DA3直接提取,并直接拼接上带噪声的潜在表示。最后直接生成source和target的联合特征,而不只生成target视角的特征。
对于给定的boundary,只对到该层为止的特征进行合成,更深的层直接由冻结的编码器得到。最终boundary选择为1。

3.级联特征生成
由于boundary设置为1,0和1层的特征是独立合成的,这会导致两层特征无法对齐。因此将第1层的潜在表示作为条件来合成第0层。
为了提高鲁棒性,在训练的时候对第一层的特征加噪
数据集
Train:RealEstate10K,DL3DV,Hypersim,TartanAir
Evaluation:Re10K,DL3DV,Mip-NeRF360
算力
8张B200
实验结果








优势与不足
优势
1.直接将几何基础模型的特征拿来做latent space,相较于用于图像生成的特征空间天然具有几何一致性优势
2.训练收敛速度提升了4.4倍
3.通过具体的工程设计降低了模型训练的成本
不足
1.相较于Stable Diffusion在海量数据上训练的模型,基础几何模型覆盖的场景不够广泛,可能导致几何语义的失效
2.性能依赖于几何基础模型,在极端场景下可能会失效
 微信
微信 支付宝
支付宝