DINOv2: Learning Robust Visual Features without Supervision
作者:Maxime Oquab, Timothee Darcet, Theo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski
单位:Meta AI Research, Inria, Universite Paris-Saclay, ENS-PSL
会议:TMLR 2024 / arXiv 2023
链接:https://arxiv.org/abs/2304.07193 | https://openreview.net/forum?id=a68SUt6zFt
研究动机
DINOv2 想解决的问题很直接:如果不依赖文本监督,能不能只靠海量图像学出一个足够通用、足够稳健、能够同时服务分类和像素级任务的视觉基础模型。CLIP 一类方法在图文对齐上很强,但作者认为文本监督会天然偏向语义标签,难以把局部几何、边界、材质等稠密信息学扎实。

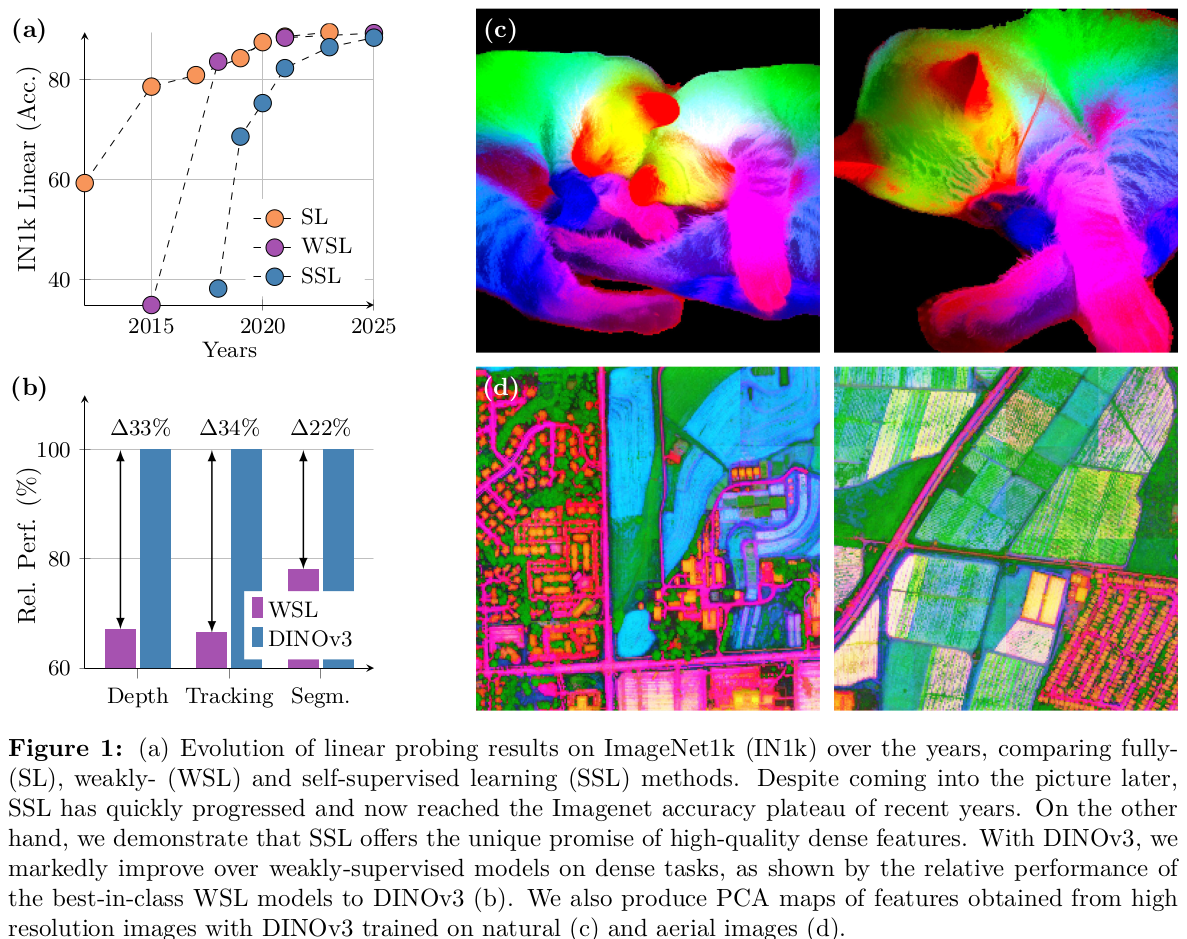
Figure 1 给出的 PCA 可视化很关键。DINOv2 的 patch 特征不仅能把主体和背景自然分开,还会把“部件”结构编码出来,这说明它学到的不是单纯的全局类别 embedding,而是更接近通用视觉表征。

Figure 2 进一步说明,随着模型规模变大,DINOv2 在 8 类任务上同步提升,而不是只在 ImageNet 线性分类上刷分。这也是整篇论文的主张:作者不是做一个单点最强的 SSL 分类器,而是做一个真正能迁移的视觉 backbone。
作者另一个判断也很重要:自监督并不是无脑扩数据就行,数据质量本身决定表征上限。DINOv2 之所以比前代更稳,一个核心前提是它在训练前先把数据集构建做成了“工程系统”。
问题本质:如何在没有文本监督的前提下,借助高质量大规模数据和稳定训练配方,学出一个既能做全局识别、又能做稠密理解的通用视觉特征。
核心方法

Figure 3 是整篇方法的总览。DINOv2 的路线可以概括成三层:
- 先构建高质量训练集 LVD-142M。
- 再用改造后的 DINO + iBOT 目标做大规模自监督预训练。
- 最后把最大的 ViT-g/14 教师蒸馏到 ViT-S/B/L,做成更易部署的一组模型。

Table 1 展示了作者如何从 iBOT 一步步改造成 DINOv2。关键改动包括:更大的 prototype 数、KoLeo 正则、SwiGLU FFN、patch size 14、teacher momentum 调整、更大的 batch,以及最关键的 untied heads。最后一步把 DINO head 和 iBOT head 解耦后,k-NN 和线性 probe 都到达最好结果,说明 image-level 与 patch-level 监督确实不该共用同一个头。

Table 2 说明了数据质量的重要性。用同样训练步数比较,LVD-142M 基本在除 ImageNet-1k 外的大多数迁移任务上都优于 INet-22k 和未筛选数据。作者的结论很明确:SSL 也吃 curated data,而且吃得很凶。

Figure 4 说明模型尺度和数据尺度是一起起作用的。大模型配合 LVD-142M 训练后,才真正把跨任务收益释放出来。

Table 3 是另外两个训练细节。KoLeo regularizer 明显提升 retrieval 等近邻型任务,MIM loss 则更利于分割、深度这类 patch-level 任务。换句话说,DINOv2 的目标函数本身就是“全局识别 + 稠密理解”双优化。

Figure 5 展示蒸馏收益。ViT-L/14 从 ViT-g/14 蒸馏后,在多个任务上不只优于同规格从头训练,有些指标甚至接近甚至反超教师。这使得 DINOv2 不只是一个 1.1B 参数的大模型故事,而是一套可落地的模型族。

Figure 6 说明高分辨率训练策略。作者没有从头全程用高分辨率硬训,而是在后期做 high-resolution adaptation。结果接近全程高分辨率训练,但成本低得多,这是非常典型的基础模型工程取舍。

Table 17 给出架构细节。最大教师是 ViT-g/14,1536 hidden dim、24 heads、40 blocks;蒸馏版 S/B/L 则保留 patch size 14 的统一设计。蒸馏模型用 MLP FFN,从头训练的大模型用 SwiGLU。
数据集
DINOv2 的数据集叫 LVD-142M,重点不只是 “142M”,而是构建方式。作者先从若干 curated source 中拿到种子集合,再到未标注大池子中做 embedding、去重、检索式扩增,最后得到更干净、更有覆盖度的视觉训练集。

Table 15 把 LVD-142M 的组成写得很清楚。它不是单一来源,而是分类、分割、深度、检索等多类视觉数据混合而成,其中 retrieval 扩增占了很大体量。这也解释了为什么 DINOv2 的特征在通用迁移上更平衡。
作者在正文中提到,这条数据构建流水线基于 Faiss GPU index,在 20 台 8xV100-32GB 机器上不到 2 天就能完成。这个数字说明它不是“不可复现的玄学数据清洗”,而是一个明确可执行的大规模检索工程。
算力
DINOv2 的训练不是轻量级实验。大模型预训练运行在 A100 上,代码层面针对大规模训练做了不少优化,包括 FSDP、内存更友好的 attention 实现、以及更快的多卡并行。

Table 16 是最值得抄作业的一张工程表。蒸馏版 S/B/L 的 batch size 为 2048,学习率 1e-3;从头训练的 ViT-L/14 与 ViT-g/14 batch size 为 3072,学习率 3.5e-4,drop path 0.4。所有模型都训练 625k iter,并配合 100k warmup。

Table 14 给出了 DINOv2-g 的复现实验碳排估算:A100-40GB,400W,22,016 GPU-hours,PUE 1.1,总耗电约 9.7 MWh,对应 3.7 tCO2eq。这个量级不算夸张到不可讨论,但已经足够说明它是典型的工业级基础模型训练。
实验结果
分类与基础迁移

Table 4 是主结果之一。DINOv2 ViT-g/14 在线性评估上做到 ImageNet-1k 86.5,ReaL 89.6,ImageNet-V2 78.4,同时 k-NN 也有 83.5。它和强势的 weakly supervised/CLIP 类方法已经在同一量级,但这里完全没有文本监督。

Table 5 很有说服力。作者专门做了 supervised finetuning sanity check,发现从 86.5 只涨到 88.5,或者从 86.7 涨到 88.9,增益有限。这意味着 DINOv2 的 frozen features 已经足够强,很多场景下不一定非要 end-to-end finetune。

Table 6 看 domain generalization。DINOv2-g 在 ImageNet-A、R、Sketch 上都很强,尤其 Im-A 75.9、Sketch 62.5,说明它对自然分布外干扰有不错鲁棒性。Im-C 不是它最强项,但作者也明确承认 corruption benchmark 不是其主要优化目标。

Table 7 把评估拓展到图像和视频分类。它在 iNat2018、iNat2021、K400、UCF101 上都很强,说明这种视觉特征不是只会做静态物体识别,也能迁移到简单视频表征。

Table 8 是细粒度分类,覆盖 food、cars、aircraft、VOC、flowers 等。ViT-g/14 的平均分最高,这说明 DINOv2 对局部部件和纹理的编码是扎实的。

Table 9 是 instance-level recognition / retrieval。这里 DINOv2 一样很强,说明 learned feature 不只是语义聚类好看,近邻结构本身也有很高质量。
稠密任务

Table 10 显示 frozen features 配上线性头或简单 multiscale 配方,就能在 ADE20K、CityScapes、Pascal VOC 上取得很强分割结果。尤其 ViT-g/14 的 +ms 设置已经逼近同时期更复杂的 fully finetuned pipeline。

Table 11 则看深度估计。无论在 NYUd、KITTI 还是 NYUd 到 SUN RGB-D 的跨域迁移上,DINOv2 都明显优于多数 SSL/WSL baseline。作者想说明的核心是:它没有专门学 depth supervision,但 patch feature 已经足以线性分离几何信息。

Figure 7 给出分割和深度的定性例子。和 OpenCLIP-G 相比,DINOv2-g 的边界更稳、深度图更平滑,伪影更少。

Figure 8 是 OOD 例子,包含素描、油画、动物等分布外输入。作者借此说明 DINOv2 的表征在脱离训练域后仍然保留结构性。
可解释性与公平性

Figure 9 是 PCA 的更多例子,进一步强化了“无监督前景分离 + 部件级对应”这一记忆点。

Figure 10 很漂亮,也很说明问题。跨图像、跨域、跨姿态做 patch matching 时,DINOv2 能把语义相似的局部对上,说明它内部表征已经带有明显的 correspondence 属性。

Table 12 评估地理公平性。虽然 DINOv2 比 SEERv2 更好,但作者明确指出高收入地区与低收入地区之间仍有 31.7% 的差距,偏置问题并没有因为“更大更强”自动消失。

Table 13 评估性别、肤色和年龄分组上的 label association。作者认为没有明显 harmful label 被系统性触发,但也观察到“Possibly-Human”类别经常被激活,尤其 beard 等类会影响男性样本。这部分结论是审慎的:结果相对乐观,但远谈不上偏置问题被解决。
优势与不足
优势
- 把数据工程、训练配方和模型蒸馏做成了一套完整系统,不是单点 trick。
- 不依赖文本监督,却同时把全局分类、检索、分割、深度这些任务都做强了,说明表征确实足够通用。
- frozen feature 就很能打,下游往往只需线性头或浅层解码器,部署成本明显低于大规模端到端微调。
- 通过 teacher-student 蒸馏,把 ViT-g 的能力比较有效地迁移到 ViT-S/B/L,工程可用性比“只发一个超大模型”更强。
不足
- 整个方案仍然高度依赖大规模 curated data pipeline,门槛不只在模型训练,也在数据检索和去重基础设施。
- 最大模型训练成本不低,22,016 GPU-hours 决定了它并不适合普通研究团队完整复现。
- 公平性与偏置问题仍然存在,作者自己也承认更全面的评估可能暴露更多缺陷。
- DINOv2 是强表征模型,不是生成模型,也不是端到端任务系统;真正落到业务上,仍要配任务头、解码器和下游训练。
记忆点
- DINOv2 的核心不只是“更大的 DINO”,而是 高质量数据集 LVD-142M + 稳定的 DINO/iBOT 混合目标 + 大教师蒸馏 三件事同时成立。
- 没有文本监督,DINOv2 依然能把 patch-level 几何和部件信息学出来,这是它能做稠密任务的根本原因。
- 高分辨率适配、untied heads、KoLeo regularization 这些工程细节不是配角,恰恰是它能稳定扩到 ViT-g/14 的关键。
- Figure 9 和 Figure 10 最值得记:一个说明它学到前景/部件结构,一个说明它已经具备跨域 correspondence 能力。
 微信
微信 支付宝
支付宝