DreamFusion: Text-to-3D using 2D Diffusion
作者:Ben Poole, Ajay Jain, Jonathan T. Barron, Ben Mildenhall
单位:Google Research, UC Berkeley
会议:ICLR 2023 notable top 5%,2022 Arxiv
链接:arXiv, Project, OpenReview
研究动机

DreamFusion 解决的是一个很直接但当时非常困难的问题:能不能只输入一句自然语言,就生成一个可以从任意角度观察、重新打光、导出到 3D 环境中的物体或场景?
这个问题的核心矛盾在于,2D 文本到图像扩散模型已经能从海量图文数据中学到强大的视觉先验,但 3D 生成没有同等规模的文本-3D 标注数据。直接训练 3D 扩散模型需要大量 3D asset、多视角数据和高效的 3D 去噪结构,这些条件在论文写作时都不成熟。
因此论文换了一个角度:不重新训练一个 3D 生成模型,而是把已经训练好的 2D 文生图扩散模型当作一个可微的“审美与语义先验”,反复渲染一个随机初始化的 3D 表示,再用扩散模型告诉这个渲染图应该往哪个方向改。这样,3D 结构本身由 NeRF 表示承载,语言和视觉合理性由 2D Imagen 提供。
这篇文章的重要性不只在于生成效果,而在于它提出了一个后来被大量 text-to-3D / text-to-4D / avatar generation 工作复用的技术范式:
用 2D 扩散模型的 score 作为优化信号,在任意可微参数空间中搜索一个能被扩散先验认可的样本。
这个范式后来常被简称为 SDS,也就是 Score Distillation Sampling。
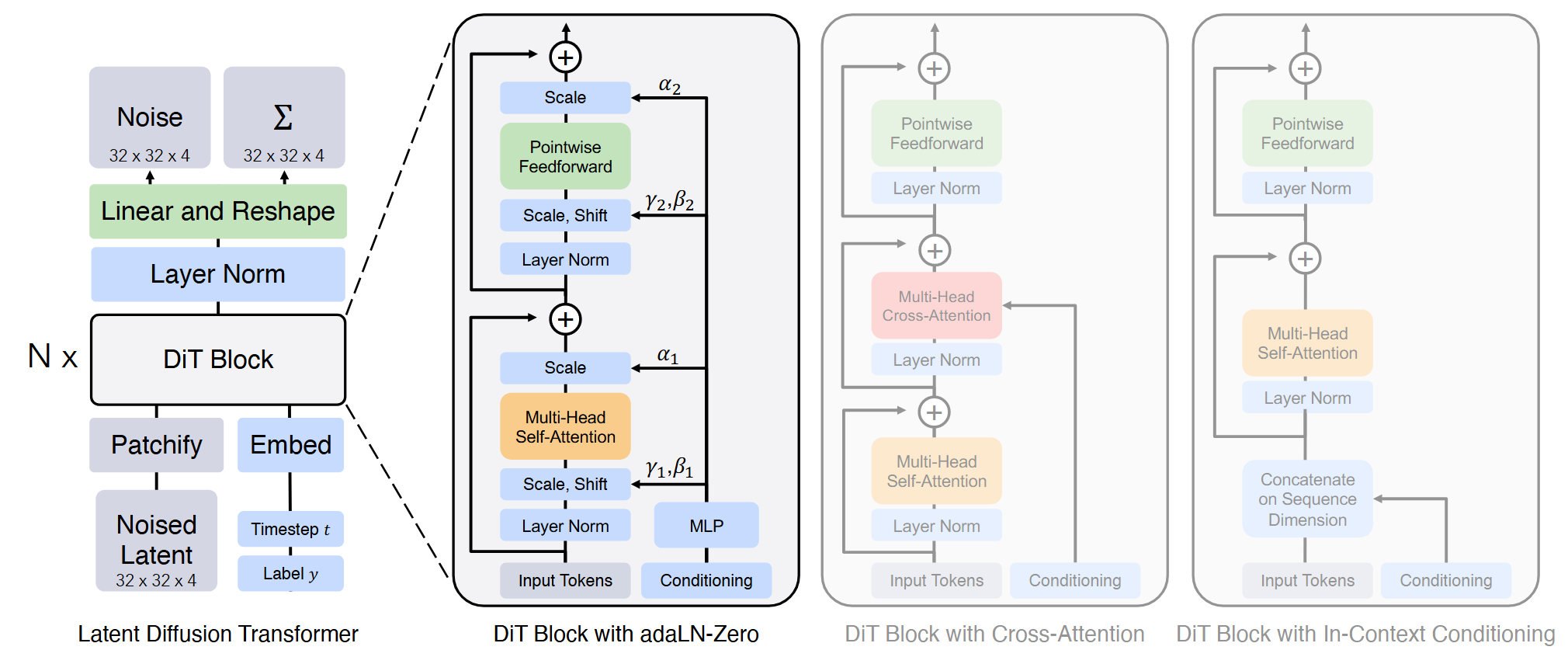
核心方法

1. 从像素采样转向参数空间优化
普通扩散采样是在像素空间中从噪声逐步去噪,目标是得到一张图像。DreamFusion 的关键转折是:如果有一个可微生成器 $x=g(\theta)$,那么不一定要直接采样图像 $x$,也可以优化参数 $\theta$,让 $g(\theta)$ 生成的图像落到扩散模型认为高概率的位置。
扩散前向加噪可以写成:
其中 $x$ 是当前渲染图,$z_t$ 是加噪后的图像,$t$ 是噪声时间步,$\alpha_t$ 和 $\sigma_t$ 控制信号与噪声比例。冻结的文本到图像扩散模型会预测噪声:
其中 $y$ 是文本条件。直觉上,如果当前渲染图与文本不匹配,扩散模型预测出的噪声方向会和真实注入噪声 $\epsilon$ 存在偏差;这个偏差就可以作为“把图像推向文本匹配区域”的梯度信号。
DreamFusion 使用的 SDS 梯度可以概括为:
这里 $w(t)$ 是时间步权重,$\frac{\partial x}{\partial \theta}$ 来自可微渲染器。论文强调一个实用处理:更新参数时不反传扩散 U-Net 的完整 Jacobian,而是把扩散模型当作提供方向的冻结先验。这让方法更像 DeepDream:不是训练 Imagen,而是利用 Imagen 的梯度形状去“雕刻”另一个参数化对象。
2. DreamFusion 管线:Imagen 提供先验,NeRF 承载 3D

DreamFusion 对每个文本 prompt 从头优化一个随机初始化的 NeRF-like 模型。这个 NeRF MLP 输出两类量:体密度 $\tau$ 和反照率 $\rho$。体渲染得到彩色图、深度、法线和纹理去除后的 shading 结果。
每次迭代包含四步:
- 随机采样相机位姿和光照位置;
- 从该视角渲染当前 NeRF,分支包括 albedo、shaded render 和 textureless render;
- 对渲染图加噪,送入冻结的 64x64 Imagen base model,计算 SDS 梯度;
- 将梯度通过可微渲染过程回传到 NeRF 参数。
这个设计的关键不是简单地“让一张图像像 prompt”,而是让同一个 3D 参数化对象在很多随机视角下都能被 2D 扩散模型接受。多视角随机渲染提供了几何一致性的压力,SDS 提供了语义和外观方向。
3. 为什么需要 view-dependent prompt 和几何正则
纯 SDS 很容易找到投机解。比如,模型可以把目标外观画在一张近似平面上,使某个视角看起来合理,但从侧面看就失去 3D 结构。论文为了避免这种局部最优,引入了几类辅助设计:
- 大范围相机采样。 每轮随机采样方位角、仰角、距离和焦距,让模型不能只服务于一个固定视角。
- 视角相关文本条件。 当相机从前、侧、后或高处看物体时,在 prompt 中追加对应视角描述,减少扩散模型对“典型正面图”的偏置。
- 光照和 textureless render。 如果只优化彩色 albedo,模型可能用纹理伪装几何;加入 Lambertian shading 和无纹理渲染后,密度场的法线与表面形状会受到更强约束。
- orientation / opacity 正则。 orientation loss 鼓励法线朝向合理,opacity 正则避免密度场把空间填满。
这也是 DreamFusion 比早期 CLIP-guided text-to-3D 方法更有价值的地方:它不是只换了一个更强的语义损失,而是围绕 3D 优化的病态性设计了一整套采样、渲染和正则策略。
4. 文本迭代与可编辑性

论文展示了通过逐步修改 prompt 来细化 3D 场景的过程。这个图传达的不是“模型有交互界面”,而是 DreamFusion 的优化目标天然支持 prompt-level control:每个 prompt 会重新优化一个 3D 表示,用户可以通过语言改变对象类别、材质、动作或环境属性。
不过这也暴露了一个代价:它不是一次前馈生成,而是每个文本都要做较长时间的 per-prompt optimization。因此 DreamFusion 更像高质量 3D 资产生成的离线优化流程,而不是实时交互式生成器。
数据集
DreamFusion 本身不使用 3D 训练数据,也不使用多视角监督数据。论文的核心设定是:只依赖一个已经训练好的 2D text-to-image diffusion prior,再对每个 prompt 从随机初始化的 NeRF 开始优化。
实验评估主要使用 Dream Fields 中的 object-centric COCO validation subset,共 153 个文本 prompt。评价指标是 CLIP R-Precision:给定渲染图,检测 CLIP 能否从候选 captions 中检索回正确文本。论文同时在彩色渲染和 textureless geometry 渲染上测 R-Precision,因为彩色图的分数可能被“贴纹理”欺骗,而 textureless 渲染更能暴露几何质量。
需要注意的是,论文使用的 Imagen 预训练数据并不等同于 DreamFusion 自己的数据集。DreamFusion 继承了 Imagen 的图文先验,也继承了其中可能存在的数据偏差、内容偏差和安全风险。论文在 Ethics Statement 中明确指出,3D 生成模型可能放大 2D 生成模型已有的偏见和滥用问题。
算力
论文给出的主要训练/优化设置如下:
- 使用预训练的 64x64 Imagen base text-to-image model,不使用超分辨率级联;
- 每个 prompt 优化一个 NeRF-like 场景;
- 每次迭代每个设备渲染一个视角并调用一次 diffusion U-Net;
- 使用 TPUv4 machine with 4 chips;
- 优化 15000 iterations,约 1.5 小时;
- 渲染 NeRF 和评估 diffusion model 的时间大致各占一半;
- 优化器使用 Distributed Shampoo;
- classifier-free guidance 设置为 $\omega=100$,明显高于常见图像采样中的 guidance 范围。
所以 DreamFusion 的“无需 3D 数据”并不等于“便宜”。它把数据成本转移成了推理/优化成本:每个新对象都需要一次较重的 per-prompt 3D 优化。
实验结果

Table 1 的主要结论是:DreamFusion 在彩色渲染和 textureless geometry 两类指标上都显著优于早期 text-to-3D baseline。论文报告 DreamFusion 在 CLIP L/14 上的 color R-Precision 为 79.7,geometry R-Precision 为 58.5;相比之下,Dream Fields reimplementation 的 geometry 分数只有 1.4。
这个差距说明一件事:只让渲染图在语义上像文本还不够,必须显式处理几何质量。DreamFusion 的 textureless render、视角采样和 shading 约束,正是为了解决“彩色图看起来像,但几何是假的”这个问题。

定性对比进一步展示了这种差异。Dream Fields 和 CLIP-Mesh 可以生成与文本有一定关系的形状或贴图,但更容易出现粗糙、破碎、几何不稳定的问题。DreamFusion 的结果更接近完整物体,并能保留可观察的体积结构。
不过这里也要谨慎:CLIP R-Precision 并不是 3D 几何的真实标准答案。零样本文本到 3D 没有唯一 ground truth,论文只能用文本-渲染一致性作为代理指标。这个指标能说明“语义是否对得上”,但不能完全说明 mesh 可用性、拓扑质量、物理合理性或多视角细节质量。

消融实验是论文里最有信息量的部分之一。它说明 DreamFusion 的几何质量不是 SDS 单独带来的,而是多个工程选择叠加出来的:
- 只看 albedo 的 R-Precision 可能很高,但会掩盖几何问题;
- 加入更大范围视角采样后,模型更难用单一视角投机;
- view-dependent prompt 改善不同观察方向下的语义一致性;
- 光照和 textureless render 让模型必须解释表面形状,而不是只画贴图;
- 最终 textureless geometry 指标随这些模块逐步提升。
这组消融也指出了 DreamFusion 的一个核心经验:text-to-3D 的失败往往不是“语义不知道”,而是“2D 先验太容易被错误几何欺骗”。因此几何约束与渲染策略和扩散先验同等重要。
优势与不足
优势
把 2D 扩散模型迁移到 3D 的思路非常干净。 DreamFusion 不需要 3D 训练集,也不修改 Imagen,只通过 SDS 把 2D prior 变成参数空间的优化信号。
SDS 的复用价值很高。 只要对象能可微渲染或可微映射到图像空间,就可以尝试用扩散 score 优化参数。这使 SDS 后来成为 3D/4D/人体/场景生成中的通用工具。
论文没有只停留在 loss,而是解决了 3D 优化的局部最优问题。 随机视角、view-dependent prompt、textureless render、orientation loss 和 opacity regularization 共同构成了可用系统。
结果具备资产属性。 生成的 NeRF 可以从任意角度观察、重新打光,也可以通过 marching cubes 导出 mesh,这比单张图生成更接近 3D 内容生产需求。
不足
速度和成本高。 每个 prompt 需要约 15000 次迭代和 1.5 小时 TPUv4 优化,不适合实时或大规模低成本生成。
分辨率受 64x64 Imagen base 限制。 论文明确指出生成模型缺少细节;更高分辨率扩散模型和更大的 NeRF 可能改善细节,但会进一步增加计算成本。
SDS 本身有 mode-seeking 倾向。 论文指出 SDS 相比 ancestral sampling 更容易产生过饱和、过平滑和低多样性结果,不同随机种子之间差异有限。
3D lifting 本质上病态。 从 2D prior 推断 3D 世界存在多解,模型仍可能陷入把内容“画”在平面上的局部最优。DreamFusion 的正则只能缓解,不能彻底消除这一歧义。
评估仍然不充分。 CLIP R-Precision 能评估文本一致性,但不能完全评价真实 3D 可用性、拓扑、细节、物理尺度和编辑稳定性。
继承 Imagen 的偏差与安全风险。 由于 2D prior 来自 Imagen,DreamFusion 也会继承其训练数据和文本编码器中的偏见、限制与潜在滥用风险。
记忆点
SDS 的本质是把扩散模型从“采样器”变成“可微优化先验”。 它不直接生成 3D,而是告诉当前渲染图应该如何移动到文本条件下的高概率区域。
DreamFusion 的关键对象不是图像,而是参数 $\theta$。 图像只是每次迭代从 NeRF 渲染出来、用于询问 Imagen 的中间观测。
text-to-3D 的核心难点是几何投机。 只优化彩色图会得到看起来像、侧面崩的结果;textureless render 和 shading 约束是避免投机的重要技巧。
无 3D 数据不等于无先验。 DreamFusion 使用的是强 2D 图文先验,只是把 3D 标注需求换成了扩散 prior 与 per-prompt optimization。
DreamFusion 是一类范式的起点。 后续很多工作都在回答同一个问题:如何让 SDS 更稳定、更快、更高分辨率,并用更强的 3D 表示或多视图扩散先验减少 Janus、过平滑和几何歧义。
一句话总结:DreamFusion 最值得记住的不是“第一批效果不错的文生 3D 图”,而是它把冻结的 2D diffusion model 变成了 3D 参数优化的通用监督信号;它证明了 2D 生成先验可以跨模态迁移,但也清楚暴露了速度、细节、多样性和几何歧义这些后续研究必须继续解决的问题。
 微信
微信 支付宝
支付宝