RAEv2: Improved Baselines with Representation Autoencoders
作者:Jaskirat Singh, Boyang Zheng, Zongze Wu, Richard Zhang, Eli Shechtman, Saining Xie
单位:Adobe Research, ANU, New York University
会议:2026 Arxiv
链接:arXiv | Project Page
研究动机
近年来,潜在扩散模型(Latent Diffusion Models, LDM)已成为图像生成领域的主流。常规的 LDM 必须依赖于一个专门训练的变分自编码器(VAE)将高维像素空间映射至低维的潜在空间。然而,近期提出的“表征自编码器”(Representation Autoencoders, RAE)打破了这一常规,它直接利用现成的、自监督预训练视觉编码器(如 DINOv2、DINOv3 等)作为潜在空间,通过在其特征上训练扩散模型来省去独立的 VAE 训练。这对于统一计算机视觉的“理解(Understanding)”和“生成(Generation)”两大领域具有里程碑式的意义。
但是在实际落地时,初代的 RAE 暴露出了三个极其严重的痛点:
- 重建性能瓶颈:初代 RAE 采用简单的单层(最后一层)特征重建策略,导致图像重建的分辨率和保真度落后于专门 of LDM VAE(如 Flux VAE 或 SDXL-VAE),尤其是在没有大规模特定领域数据微调的情况下,重建出来的图像边缘模糊,细节丢失严重。
- 引导机制(Guidance)的昂贵成本:在扩散模型生成中,无分类器引导(Classifier-Free Guidance, CFG)对于提升图像质量至关重要。但由于表征空间的特殊性,初代 RAE 无法直接兼容 CFG,不得不依赖一种名为“自动引导”(AutoGuidance, AG)的折中方法。AG 强制要求额外训练一个较弱的辅助扩散模型,这在训练和推理两端都极大地增加了计算和工程的复杂度。
- 高频结构特征的忽视:原有架构仅抽取预训练编码器的最后一层特征作为全局特征表示,而没有挖掘深层网络在不同层级所累积的层次化多尺度空间特征。
为了系统性探索 RAE 的设计空间并解决 these 瓶颈,作者提出了 RAEv2。相较于前作,RAEv2 在生成质量与重建保真度之间取得了更优的帕累托前沿(Pareto Frontier),同时收敛速度提升了 10 倍以上,且不需要任何额外的辅助模型。

Figure 1 | 原始 RAE 与 RAEv2 的收敛速度与帕累托前沿对比。

Figure 2 | RAEv2 多维度指标领先示意图(涵盖重建质量 PSNR、生成 FID 与推理吞吐量)。
问题本质:如何在不增加额外训练成本、不引入庞大辅助模型的前提下,通过系统化改进潜在特征的提取方式与正则化机制,使 RAE 在重建、生成与引导三个维度上同时达到工业级实用水平?
核心方法
为了打破初代 RAE 的限制,RAEv2 围绕“表示提取”、“特征蒸馏的互补性”以及“引导机制的重构”三个核心洞察,提出了以下三个核心设计:
1. 广义表征编码器 (Generalized Representation Encoder)
传统的 RAE 将预训练视觉编码器的最后一层 (Final Layer) 特征作为 RAE 的潜在表示。然而,自监督视觉编码器不同层级对信息的编码侧重点不同:浅层更侧重于局部高频空间结构,深层更侧重于全局高频语义。只使用最后一层,相当于割裂了空间结构的完整性,导致低级图像细节重建能力严重受限。
为了弥补这一缺陷,作者提出了一种免训练(Training-free)的广义表征提取手段:多层特征求和 (Multi-Layer Summation, MLS)。即将编码器最后 $K$ 层的特征进行逐元素求和:
其中 $L$ 为编码器的总层数,$\mathbf{z}_l$ 为第 $l$ 层的输出特征。在高维欧氏空间中,简单的向量加法能够以极低的代价保留底层子空间的几何流形。这种求和策略没有增加任何潜在空间的维度(维度仍然保持为 $N \times d$ ),因此完全不会增加扩散模型在训练时的 token 负担。实验表明,MLS 的效果甚至优于将各层特征拼接后再做随机投影降维(MLR)的方法,展现出极高的优雅度与简洁性。

Figure 3 | 采用不同自监督 VAE 特征(如 DINOv2-B/L、DINOv3-B/L)时的定性重建对比。
2. RAE 与 REPA 的强互补性 (Complementary Working Mechanisms)
在生成式表征对齐中,REPA (Representation Alignment) 是一种在扩散模型的中间层对预训练特征进行知识蒸馏(Alignment)的技术。学术界此前普遍认为:如果 RAE 已经在输入端将预训练特征作为 Latent 载入,那么在扩散模型内部再使用 REPA 就是无谓的冗余,只会白白耗费网络容量。
但作者通过对 27 种不同预训练视觉编码器进行系统的经验分析,得出了完全相反的结论:RAE 和 REPA 的底层机制是高度互补的!

Figure 5 | RAE 与 REPA 协同工作的微观机制。
- RAE 主要为模型提供了一个富有语义背景的“初始潜在生成空间”(在定量指标上表现为与分类探针线性可分性 LP 高度相关)。
- REPA 则充当一种空间结构正则化器,通过计算扩散模型中间层特征与预训练目标特征的对齐损失,约束并纠正扩散过程中的“空间几何分布”(在定量指标上表现为与局部距离相似度 LDS 高度相关)。
两者结合后,图像的语义与空间结构得到了同步的优化,生成效果与 LP 和 LDS 的调和均值呈现出极强正相关。这也解释了为什么 DINOv3-L 这样同时具备强全局语义和细粒度局部空间定位的模型,在 RAEv2 中能爆发出最佳的生成性能。

Figure 6 | 经验消融结果表明,在生成过程中 LP 与 LDS 的调和均值与生成 FID 之间呈极强的负相关(即相关度越高,FID 越低)。
3. 基于 REPA 的“免费”无分类器引导 (Free Guidance via REPA)
传统的无分类器引导(CFG)需要对条件和无条件方向做双前向传播(2x NFE),开销巨大。而初代 RAE 采用的 AutoGuidance 甚至需要额外训练一个辅助模型,推理更加臃肿。
作者通过严谨的数学推导,揭示了一个绝妙的数学等价关系:在 RAE 空间中,REPA 投影头本质上扮演了早期 x-prediction 的角色。
因为 REPA 的对齐投影头 $h_\phi$ 是一个轻量级 MLP,且它在扩散过程中仅接触到去噪模型很早期的中间特征 $\mathbf{h}$,因此它对原始无条件或原始噪声数据的估计 $\hat{\mathbf{x}}_{\text{repa}} = h_\phi(\mathbf{h})$ 自然构成了一个“较弱的预测基线”。

Figure 4 | 传统无分类器引导(CFG)、自动引导(AG)以及本方案中基于 REPA 头弱预测差分的 Internal Guidance 流程对比。
既然我们拥有了主去噪模型的强估计 $\hat{\mathbf{x}}_{\text{full}}$(将其转换为 x-prediction 形式)和 REPA 投影头输出的弱估计 $\hat{\mathbf{x}}_{\text{repa}}$,我们就可以直接实施内部引导(Internal Guidance):
其中 $w$ 是引导权重。该策略直接废除了辅助模型的训练,同时由于 REPA 头在主模型的一次前向传播中同时被运行,整个推理过程省去了传统 CFG 需要的两次网络前向传播(Double NFEs),实现了完全“免费”的引导。

Table 1 | 不同引导机制在生成指标(gFID)和推理开销(NFEs)上的比较(基于 DINOv3-L, 80 epochs)。
数据集
- 训练与基准数据集:模型全部基于经典的 ImageNet-256 图像集进行训练与基准对比。
- 全新评测指标:
EP_FID@k:考虑到 RAEv2 相比原有方法收敛极其迅速,传统的极限 gFID 无法准确衡量模型的样本效率。作者提出了EP_FID@k指标,定义为模型在无任何引导(Guidance-free)的情况下,其 gFID 降至 $k$ 以下所需的训练 Epoch 数量。这能更科学地反映自监督模型的收敛速度。
算力
在算力消耗与训练时间上,RAEv2 迎来了跨越式突破:
- 采用 DINOv3-L 作为特征提取器,DiT-XL 作为生成主体骨干,Batch Size 设为 1024。
- 其收敛效率相比初代 RAE 快了 10 倍以上。
- 要使生成质量达到
EP_FID@2的门槛,初代 RAE 需要漫长的 177 个 Epoch,而 RAEv2 仅需 35 个 Epoch 即可实现。这在工业界的大模型预训练中意味着数以万计 GPU 小时的节省。
实验结果
1. 卓越的生成性能与收敛速度
在 ImageNet-256 上,RAEv2 表现出了无与伦比的收敛速度和指标领先:

Figure 8 | 在不同自监督骨干(DINOv2-B, DINOv3-B/L, EUPE-B, WebSSL-1B, SpatialPE-B)上,RAEv2 与初代 RAE 的收敛速度对比。

Figure 9 | 生成质量 (gFID) 与重建质量 (rFID) 的帕累托最优边界曲线。

Table 7 | 训练效率及多评估指标定量对比。
2. 消融实验与架构分析
A. 预训练视觉编码器消融 (Choice of Pretrained Vision Encoder)
作者系统地测试了 27 种自监督/文本弱监督编码器,并评估了它们在表征学习重建 and 生成中的表现。

Table 2 | 不同视觉编码器在 RAE 重建与生成质量上的消融对比。
B. 广义表征 MLS 与 MLR 策略对比 (Generalized RAE Formulation)

Table 3 | 多层特征融合机制(MLS vs MLR)在不同层数下对重建和生成的影响。
C. 引导机制消融 (Guidance Mechanism in RAEv2)

Table 4 | 各种引导策略在生成质量上的对比。
D. 参数 $K$ 的消融与表征保留分析 (Impact of $K$ and Representation Preservation)

Figure 7 | 参数 $K$ 对生成(有/无引导)和重建(rFID/PSNR)的多维度消融影响。
随着 $K$ 的增加,低层结构高频特征在 MLS 累加中被引入,重建 PSNR 和 rFID 单调提升。然而,当 $K > 7$ 时,无引导生成的 gFID 略微上升,这是由于过多底层浅层特征的融合对语义生成造成了噪声干扰,而内部引导(with guidance)能够完美校正并抵消这一问题。
同时,MLS 策略是否会破坏原始预训练编码器的特征可分性?作者对此进行了线性探针(Linear Probing)评估:

Table 5 | 在 ImageNet 上进行 30 epochs 的线性探针精度对比。证明 MLS 在不影响预训练视觉编码器下游分类语义表征性能的前提下,显著强化了空间图像重建能力。
E. 模型尺度缩放消融 (Variation in Model Scale)

Table 6 | 扩散模型生成骨干的参数规模扩展(DiT-B, -L, -XL)消融。
3. 图像重建质量分析 (Reconstruction Quality Analysis)
作者将经过自监督解码器训练后的重建结果进行了可视化。可以看到,相比于原始 FLUX VAE 或 SDXL-VAE,RAEv2 仅仅利用了预训练特征和少量自监督训练,便获得了极具张力的细节重建精度。

Figure 10 | 在使用额外数据对解码器进行训练时,RAEv2 在微观物体边缘、文字细节和几何拓扑上与各类常用 VAE 的重建保真度对比。
4. 多场景泛化:文生图 (Text-to-Image Generation)
为测试表征自编码器在条件生成任务上的泛化性,作者在 text-to-image (T2I) 任务上进行了拓展,将 DiT 主体修改为支持文本交叉注意力的结构。

Table 8 | 文生图(Text-to-Image)任务在 GenEval 与 DPG-Bench 上的定量对比。

Figure 11 | RAEv2 模型的文生图定性样本展示(分辨率 256x256,展示了极强的提示词遵从度与材质质感)。
5. 多场景泛化:世界模型 (World Models for Robot Navigation)
作者在动作条件的机器人导航视频预测数据集 RECON 上评测了 RAEv2 作为世界模型(World Models)的视觉空间编码器表现。

Table 9 | 在 RECON 机器人导航视频预测上,长达 16 秒的预测帧质量(FVD)定量对比。

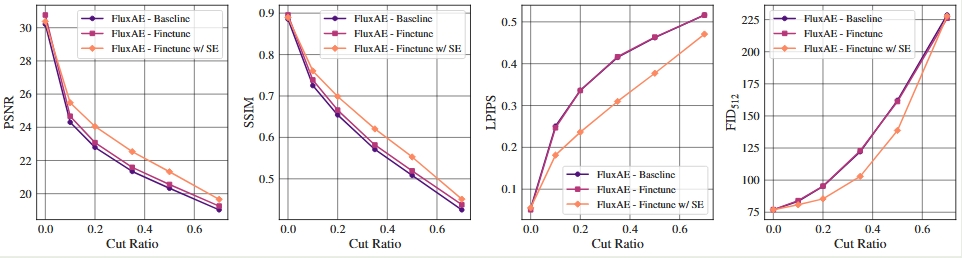
Figure 12 | 随着视频时序预测推演长度(Prediction Horizon T=1s 到 T=16s)增加,视频帧重建指标 FID/LPIPS 的变化曲线。

Figure 13 | 机器人动作引导下时序预测的定性对比(Ground Truth 与 RAE-NWM, RAEv2-NWM 的前推效果)。

Figure 14 | 在 RECON 世界模型视频数据集上的训练收敛速度对比(基于 FID 和 LPIPS 指标)。
优势与不足
优势
- 极简优雅的数学闭环:抛弃了前代 AG 机制的冗余辅助 network,巧妙地发现“REPA 投影头 = 早期预测”,从而将 CFG 的 2x 推理开销降为 1x,代码实现极简,系统健壮。
- 极速收敛的平民化科研:将生成任务的训练时长从 800 Epoch 砍到 35 ~ 80 Epoch。这种十倍级的提速使得算力受限的高校实验室和中小企业也能够参与到前沿视觉基础模型的探索中。
- 消除学术偏见:用无可辩驳的消融实验证明了 RAE(输入端)与 REPA(内部层)并不是互相排斥的,而是分别接管“全局语义分类”与“局部空间对齐”的黄金搭档。
不足
- 受限于预训练视觉特征的天花板:模型重建的能力完全被预训练编码器(如 DINOv3)的特征空间决定。如果面对极度偏离预训练分布的异型纹理或低级像素伪影,可能会出现一定的重建模糊或解析失真。
- 极限引导尺度(Guidance Scale)下的不确定性:虽然 Internal Guidance 在常用尺度下工作完美,但当引导权重 $w$ 放大至极端值时,是否会像传统 CFG 那样导致图像色彩饱和或结构破损,论文仍缺乏系统性的临界点极限分析。
记忆点
要快速记住 RAEv2 的划时代意义,只需掌握以下三点:
- 层级累加出奇迹:不要只拿预训练模型的最后一层特征当潜在表征,把最后 $K$ 层简单加起来,空间细节和重建质量就能发生质的飞跃。
- RAE 与 REPA 是强强联手:输入端用特征(RAE)负责拉高语义维度,内部用特征(REPA)负责矫正空间轮廓,分工协作效果最完美。
- “免费”的内部引导:把 REPA 头当成天然的早期 x-prediction 弱基线,跟强估计做差分即可用于 Guidance,无需训练辅助模型,且推理速度加倍。
RAEv2 的成功证明了,通过巧妙重组预训练理解模型,我们可以实现高质量的视觉生成,这也为通往“理解与生成大一统”的视觉基础模型扫平了道路。
 微信
微信 支付宝
支付宝