

学科资料(百度网盘链接)——其他资源
提示所有文件均来自于博主大学期间学习时收集的课件笔记等,每一个文件的制作与整理都倾注了老师及博主的心血,希望对大家的学习有所帮助,部分科目课件或笔记时间久远有所丢失请谅解。禁止将其中的任何文件用于商业用途,仅供学习使用! 数学建模学习资源https://pan.baidu.com/s/1E4e1PsBuliatexk7FAqcXA?pwd=yib3 提取码: yib3 PPT资源 https://pan.baidu.com/s/1hqH39fhUqnSn9o-wkgmAKA?pwd=jxwh 提取码: jxwh 书籍资源https://pan.baidu.com/s/1t9FdWZS5pKDnR-4EkwszGA?pwd=a945 提取码: a945
学科资料(百度网盘链接)——本科
提示所有文件均来自于博主大学期间学习时收集的课件笔记等,每一个文件的制作与整理都倾注了老师及博主的心血,希望对大家的学习有所帮助,部分科目课件或笔记时间久远有所丢失请谅解。禁止将其中的任何文件用于商业用途,仅供学习使用! 总链接:https://pan.baidu.com/s/1eEEip_rFuyLBo6lG2qb1CQ?pwd=fpd4提取码: fpd4 按年级分大一上https://pan.baidu.com/s/1ywqPA_lXboM4KTwS03_LkQ?pwd=katw 提取码: katw 大一下https://pan.baidu.com/s/1RPY9myvMeWgmV9tFao43EQ?pwd=mx4b 提取码: mx4b 大二上https://pan.baidu.com/s/1CRqcZtvoe3I0PqspIbDOpw?pwd=te9p 提取码: te9p 大二下https://pan.baidu.com/s/1w7NNdGyhqSHVyZgaMqAxSw?pwd=ygud 提取码: ygud...
![[计算机视觉:算法和应用]第二章:图像形成——2.1 几何图元与变换](/img/cvaacover.png)
[计算机视觉:算法和应用]第二章:图像形成——2.1 几何图元与变换
原书PDF链接:Computer Vision: Algorithms and Applications, 2nd ed. 2.1 几何图元与变换 在这一节将介绍这本书中所用到的基础的二维和三维图元,即点、线、面,也将描述三维特征是如何投影到二维特征。 有关这些话题更细致的描述可以在关于多视图几何的教科书中找到 《Multiple View Geometry in Computer Vision Second Edition》:https://assets.cambridge.org/97805215/40513/frontmatter/9780521540513_frontmatter.pdf 《The Geometry of Multiple...
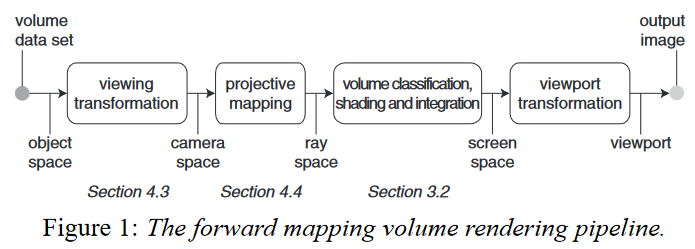
EWA Volume Splatting
elliptical Gaussian kernels 椭圆高斯核 Splatting algorithms interpret volume data as a set of particles that are absorbing and emitting light. 泼溅算法将体素数据解释为一组吸收和发射光的粒子。 Our method is based on a novel framework to compute the footprint function, which relies on the transformation of the volume data to so-called ray space. This transformation is equivalent to perspective projection. By using its local affine approximation at each voxel, we derive an analytic expression for the EWA footprint in...
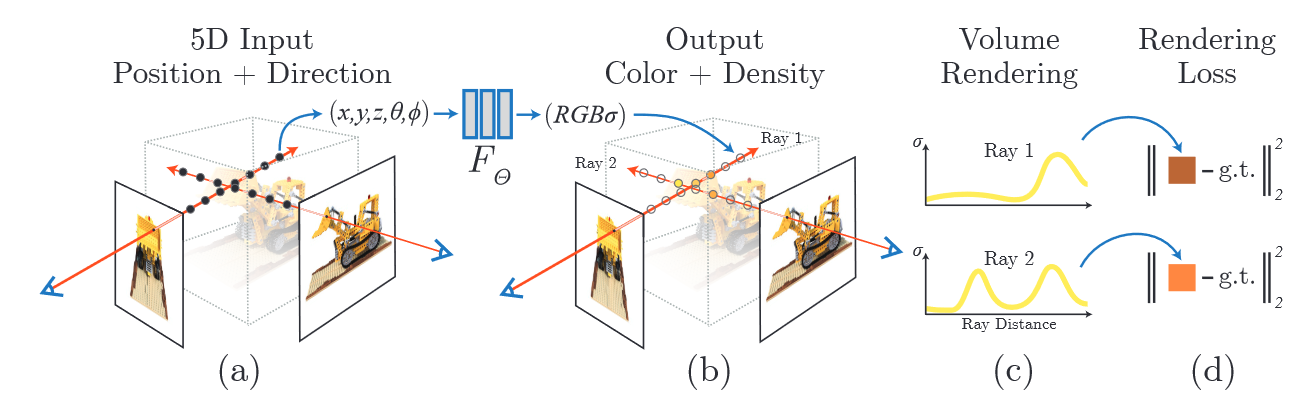
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Neural Radiance Field Scene Representation输入:连续的5D坐标(空间位置+视角方向) 3 \mathrm{D ~ l o c a t i o n ~} \mathbf{x}=( x, y, z ) \mathrm{2 D ~ v i e w i n g ~ d i r e c t i o n ~} ( \theta, \phi)输出:空间位置上的体密度和辐射强度 \mathrm{emitted color}~{\bf c}=( r, g, b ) \mathrm{v o l u m e \ d e n s i t y} \ \sigma密度控制了穿过某一位置的光线在那个位置累积了多少辐射 方法简单总结: 1)将相机光轴穿过场景生成采样的三维点集 2)用三维点和对应的二维视角方向输入神经网络生成颜色和密度集 F_{\Theta} : ( {\bf x}, {\bf d} ) \to( {\bf c},...

Mip-Splatting: Alias-free 3D Gaussian Splatting
3DGS在改变采样率或者改变焦距和相机距离时,会存在严重的膨胀效应和高频伪影 采样理论(奈奎斯特-香农采样理论)对连续信号的采样频率至少是最大频率的两倍,所以在采样之前要对信号施加滤波。 3DGS中的Dilation操作为了防止投影的2DGS小于一个像素,所以投影的2DGS进行了膨胀操作: {\mathcal G}_{k}^{2 D} ( \mathbf x )=e^{-{\frac{1} {2}} ( \mathbf x-\mathbf p_{k} )^{T}} ( \mathbf\Sigma_{k}^{2 D}+s \, \mathbf I )^{-1} \, ( \mathbf x-\mathbf p_{k} ) \tag{5}Sensitivity to Sampling Rate 对于Zoom-out,原本的object在像素中的占比缩小了,所以为了要膨胀到一个像素的大小,施加的二维膨胀相较于原来更大 对于Zoom-out,原本的object在像素中的占比变大,所以膨胀到一个像素大小所需的二维膨胀就更小 it leads to erosion effects...
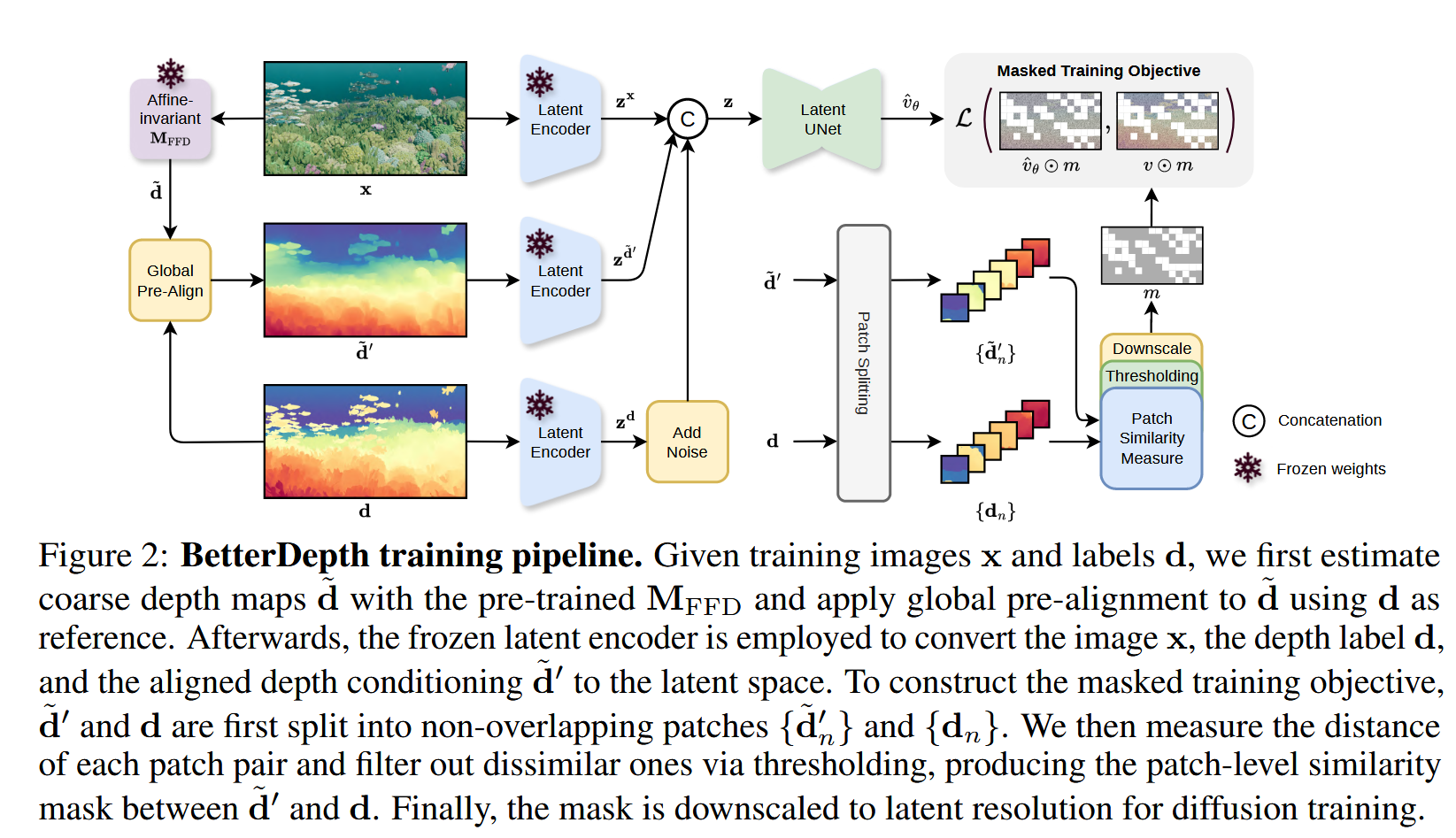
BetterDepth: Plug-and-Play Diffusion Refiner for Zero-Shot Monocular Depth Estimation
Problem Formulationfeed-forward model: {\cal L}_{\mathrm{M D E}} ( {\bf d}_{i}, {\bf M}_{\mathrm{F F D}} ( {\bf x}_{i} ) ), \tag{1}Diffusion model: {\cal L}_{\mathrm{D M}} \left( \epsilon, {\bf M}_{\mathrm{D M}} \left( {\bf x}_{i}, \mathrm{A d d N o i s e} ( {\bf d}_{i}, \epsilon, t ) \right) \right), \tag{2}Framework Global Pre-Alignment给定预训练仿射不变深度模型$\bf{M}_{FFD}$ 和数据对$\bf{(x, d)} ∈ \bf{D}_{syn}$...

DIFFERENTIABLE 3D GAUSSIAN SPLATTING
3D高斯的优势:非结构化、可微、利用快速α混合进行渲染、无需法线 世界坐标系下,高斯由三维协方差矩阵和点(均值)μ表示: G ( x ) \,=e^{-\frac{1} {2} ( x )^{T} \Sigma^{-1} ( x )} \tag{4}给定视角变换矩阵W,相机坐标系下的协方差矩阵为: \Sigma^{\prime}=J W \Sigma W^{T} J^{T} \tag{5}其中J是投影变换的仿射近似雅可比矩阵 协方差矩阵只有在半正定的时候才具有物理意义,而如果直接对协方差矩阵使用梯度下降优化,很难保证矩阵的合理性。 由于协方差矩阵是用来描述椭球的形状,因此可以用缩放矩阵S和旋转矩阵R来获得一个对应的协方差矩阵: \Sigma=R S S^{T} R^{T}\tag{6}OPTIMIZATION WITH ADAPTIVE DENSITY CONTROL OF 3D GAUSSIANSOptimization优化的参数:位置p,α,协方差矩阵,球谐函数系数 \mathcal{L}=( 1-\lambda)...
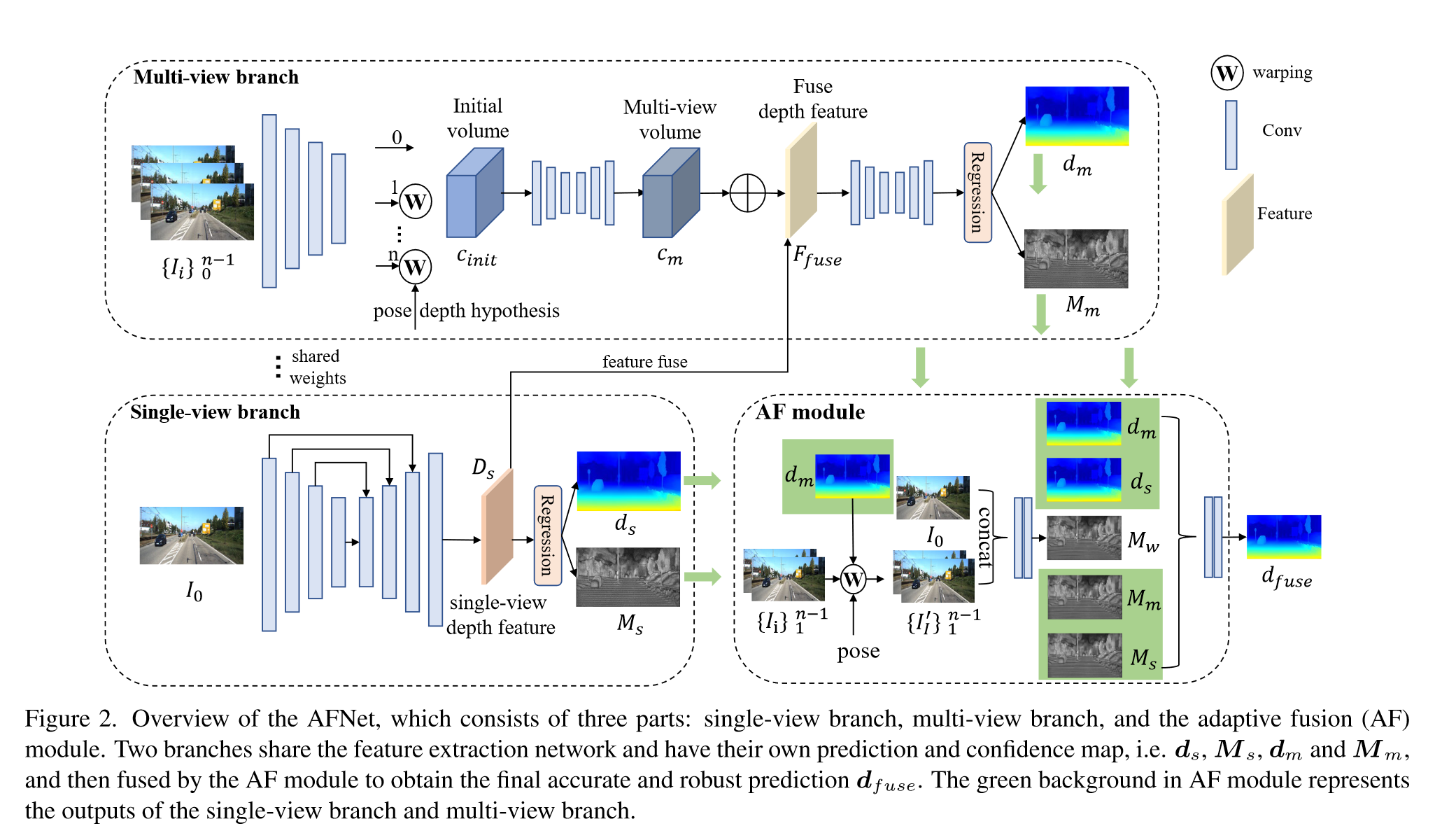
Adaptive Fusion of Single-View and Multi-View Depth for Autonomous Driving
Input: $n-1$ 个源图像 ${I_i}^{n-1}_{i=1}$、参考图像 $I_0$、相机内参和相机姿态 Output:depth $d$ Part:single-view depth module, multi-v iew depth module, adaptive fusion module and pose correction module Single-view and Multi-view Depth Module使用ConvNeXt-T作为backbone提取四个尺度上的特,征$F_{ i,l} (l = 1, 2, 3, 4)$,特征维度分别为$C=96,192,384,768$ Single-view branch采用多尺度的decoder聚合特征获得深度特征$D_s ∈ R^{H/4×W/4×257}$ 对$D_s$的前256个通道使用softmax得到depth probability volume $P_s ∈ R^{H/4×W/4×256}$,最后一个通道作为置信度图$M_s ∈...
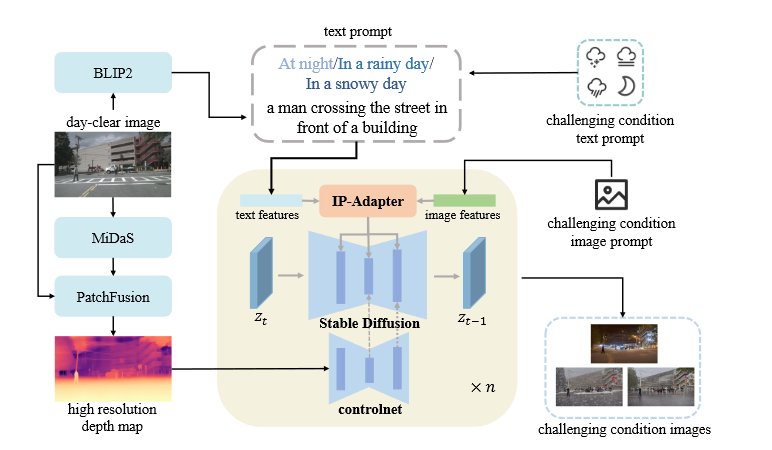
SSD:Stealing Stable Diffusion Prior for Robust Monocular Depth Estimation
背景现有的MDE方法在标准的环境下(例如晴天)表现的很好,但是在一些具有挑战性的条件下效果会变得很差,这主要是由于一些关键的假设失效了,例如光度一致性假设,同时也没有可靠的ground truth包含这些场景。 现有的一些鲁棒的解决方案 基于模型的方法 这一方法通过修改网络结构来增强模型处理各种条件的能力 缺点:网络模型过于复杂,不能够适应各种环境 基于数据的方法 利用域自适应或其他模态的数据来增强图像信号 缺点:缺乏高质量的数据,需要后处理 方法Generative Diffusion Model-based Translation生成在深度方面与白天清晰图像非常相似的训练样本 I_{g}=S D ( I P ( T_{p}, I_{p} ), C N ( D_{h} ), z ) BILP2:获取场景描述符,保留图像内容信息 ControlNet d2i:保持近似深度一致性 MiDas:获取初始深度图 PatchFusion:获得高分辨率的深度图 text prompt=BILP2 场景描述符+challenging condition...
最新文章




