
DepthMaster: Taming Diffusion Models for Monocular Depth Estimation
作者:Ziyang Song, Zerong Wang, Bo Li , Hao Zhang , Ruijie Zhu , Li Liu , Peng-Tao Jiang , Tianzhu Zhang
单位:University of Science and Technology of China, VIVO
会议:2025 Arxiv
链接:https://indu1ge.github.io/DepthMaster_page/
研究动机
- 现有的生成式深度估计模型,生成模型的中间特征会对纹理进行过度表达,导致错误的纹理预测
- 为了提高推理速度,采用单步去噪推理,但会丢失细节
核心方法

1.通过特征对齐模块,引入额外的视觉特征增强生成模型特征
2.通过傅立叶增强模块提高模型的细节表达能力
数据集
Train:
- Hypersim
- Virtual KITTI
Eval:
- NYUv2
- ScanNet
- KITTI
- ETH3D
- DIODE
算力
1张H800
实验结果





优势与不足
优势
- 率先采用了Feature Alignment的方式来增强生成模型的特征表达
- 通过频域增强的方式增强模型输出的细节,从而解决单步推理带来的平滑问题
- 两阶段学习兼顾了全局结构以及局部细节的表达能力
不足
- 模型性能依旧与data-driven的方法具有较大差距
- 相较于discriminative的方法推理速度还是比较慢,且无法采用更小型的模型进行硬件部署
记忆点
Multi-directional Gradient Loss
Square-root Disparity
在中间层进行对齐,使用KL Loss
 微信
微信 支付宝
支付宝
相关推荐
2024-12-06
D4D: An RGBD diffusion model to boost monocular depth estimation
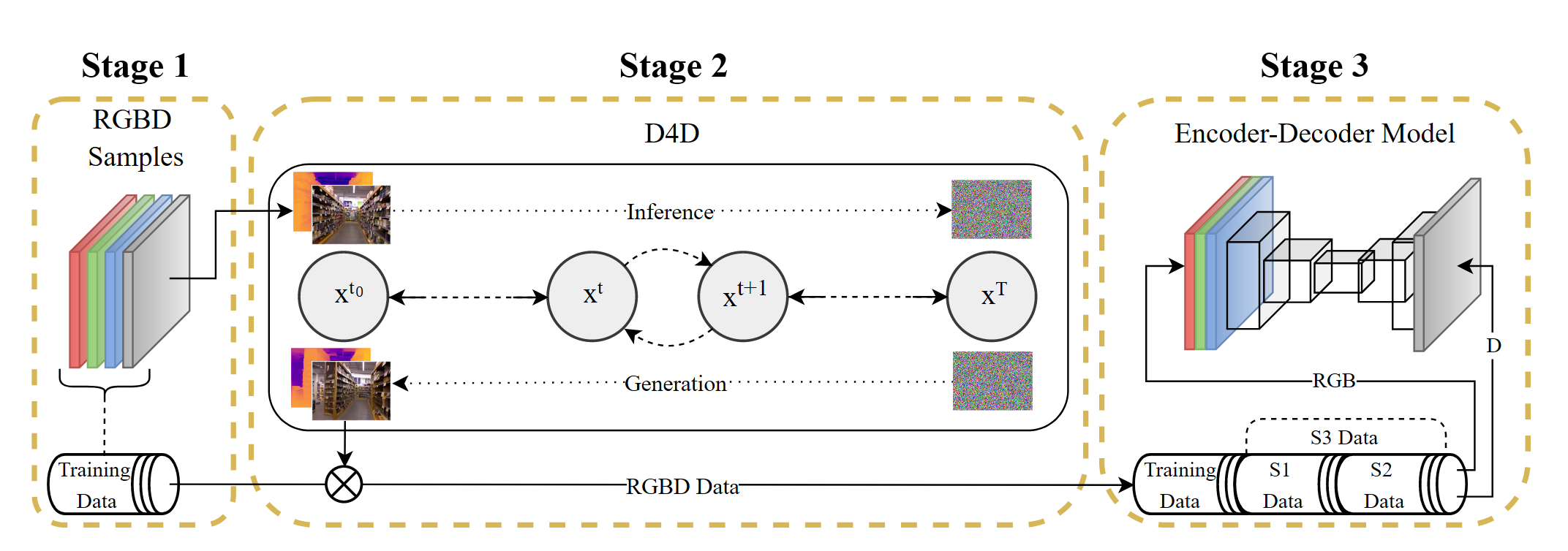
方法阶段一对NYU和KITTI中的RGBD样本进行预处理,进行归一化以及rescale,分辨率跟第三阶段所采用的model有关 阶段二第二阶段对输入的RGBD进行前向和后向操作训练网络,同时通过S1和S2两种不同的训练配置,得到不同的生成数据,其中$S1$使用$L1$ loss,$β$策略采用线性策略,$S2$使用$L2$ loss,$β$采用余弦策略 S 1 : L 1=\frac{1} {| \mathcal{P} |} \sum_{p \in\mathcal{P}} | | x_{p}-y_{p} | |_{1}, \; \; \beta=l i n e a r \tag{3} S 2 : L 2=\frac{1} {| \mathcal{P} |} \sum_{p \in\mathcal{P}} | | x_{p}-y_{p} | |_{2}^{2}, \; \; \beta=c o s i n e \tag{4}最终得到的$S3$就是$S1$和$S2$的并集 S 3=( s 1 \cup s 2 ) \; w h e r e \begin{cases} S 1...
2024-12-06
DEPTH ANY VIDEO WITH SCALABLE SYNTHETIC DATA
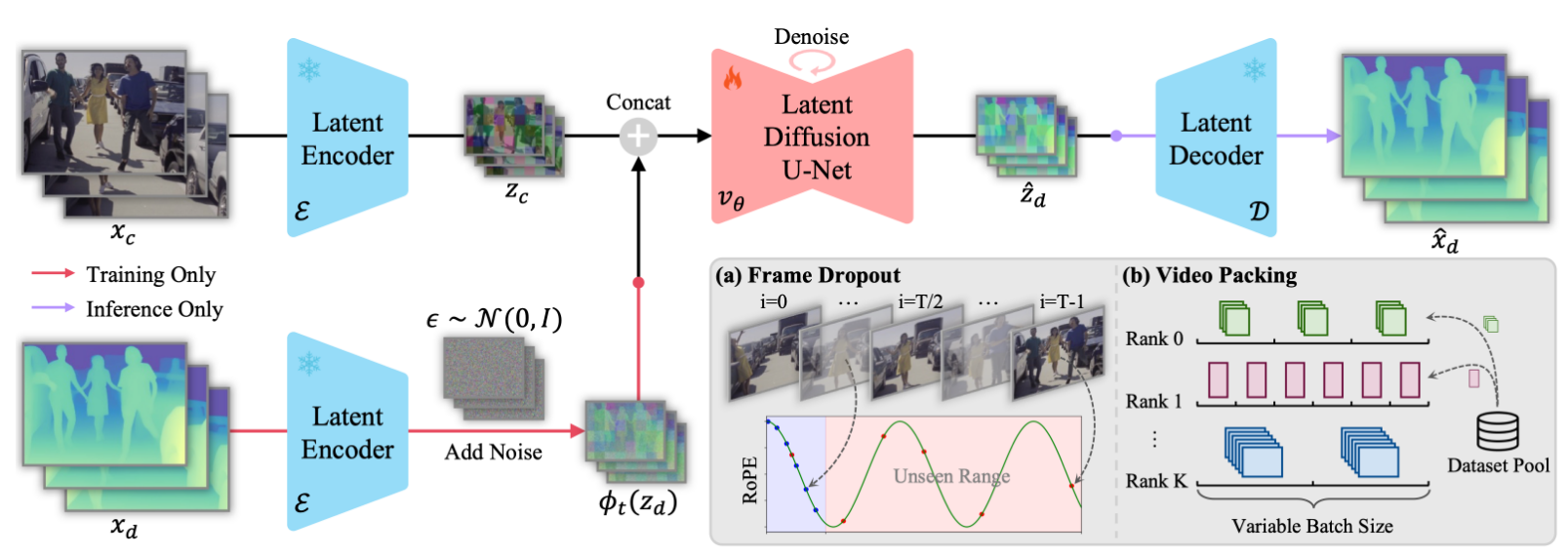
构建合成视频数据集在不同的虚拟环境中,利用synthetic engines获取深度信息,构建了一个包含40000个视频切片的数据集,涵盖室内外场景。 在部分的图像和深度图之间可能存在不对齐的现象,首先采用 scene cut 方法,根据显著颜色变化检测场景的转变,然后用深度模型去滤除掉那些指标低的视频序列。 直接过滤指标低的视频序列可能会对导致过滤到一些网络没有见过的数据,因此,进一步使用 CLIP 来计算真实深度和预测深度之间的语义相似性。 最终方法是对每个视频序列均匀采样10帧,如果语义和深度的指标都低于预先定义的阈值,就滤除该片段 生成视频深度模型模型设计 训练和推理的过程与其他基于diffusion 的model保持一致。采用和Marigold一样的归一化方法。 \tilde{x}_{d}=\left( \frac{x_{d}-d_{2}} {d_{9 8}-d_{2}}-0. 5 \right) \times2, \tag{1}由于在时间维度上进行压缩会导致运动模糊伪影,所以只在空间维度上进行压缩。 将latent video和latent...
2024-12-06
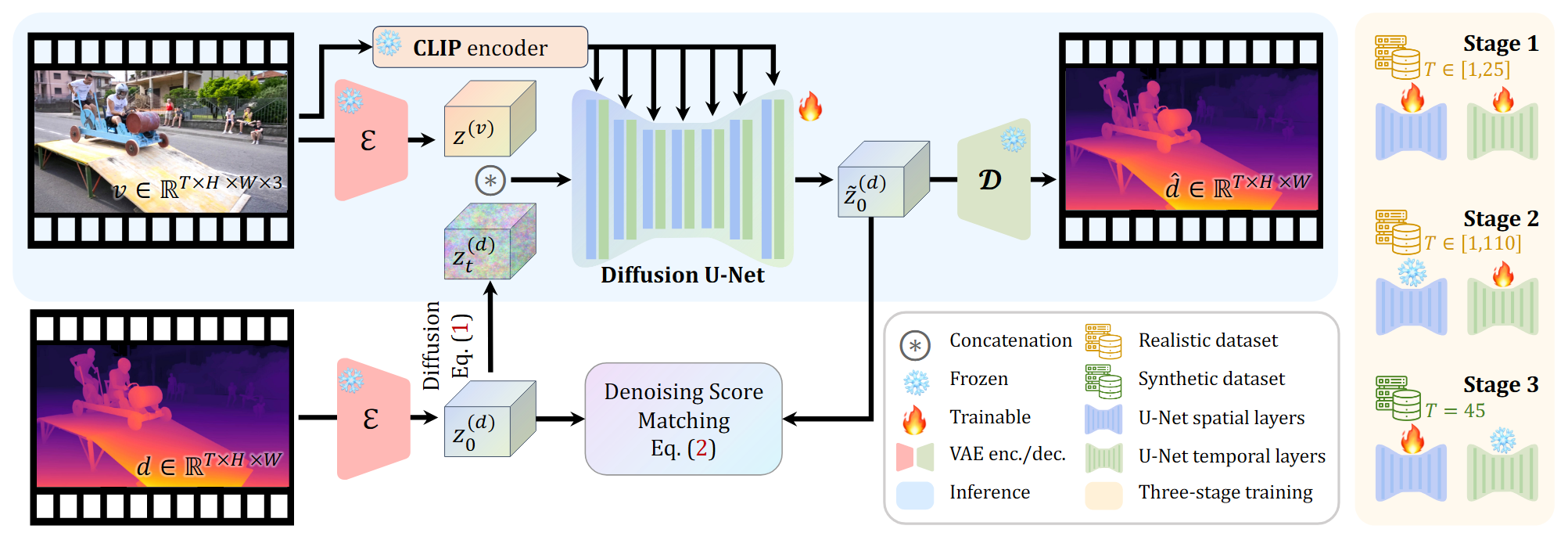
DepthCrafter
方法 将视频深度估计定义为一个条件扩散生成问题,对条件分布 $p({d}|v)$ 进行建模 采用成对的真实与合成数据集对网络进行三阶段的训练 对长序列进行分段估计并无缝拼接 Stable video diffusion model \mathbf{x}_t = \mathbf{x}_0+\sigma_t^2\epsilon,\quad \epsilon\sim \mathcal{N}(0, \mathbf{I})\tag{1} \mathbb{E}_{\mathbf{x}_t \sim p(\mathbf{x};\sigma_t),\sigma_t \sim p(\sigma)} \left[ \lambda_{\sigma_t} \left\|D_{\theta}(\mathbf{x}_t; \sigma_t; c) - \mathbf{x}_0 \right\|^2_2 \right] \quad \tag{2} D_\theta (\mathbf{x}_t; \sigma_t; \mathbf{c})...
2025-02-27
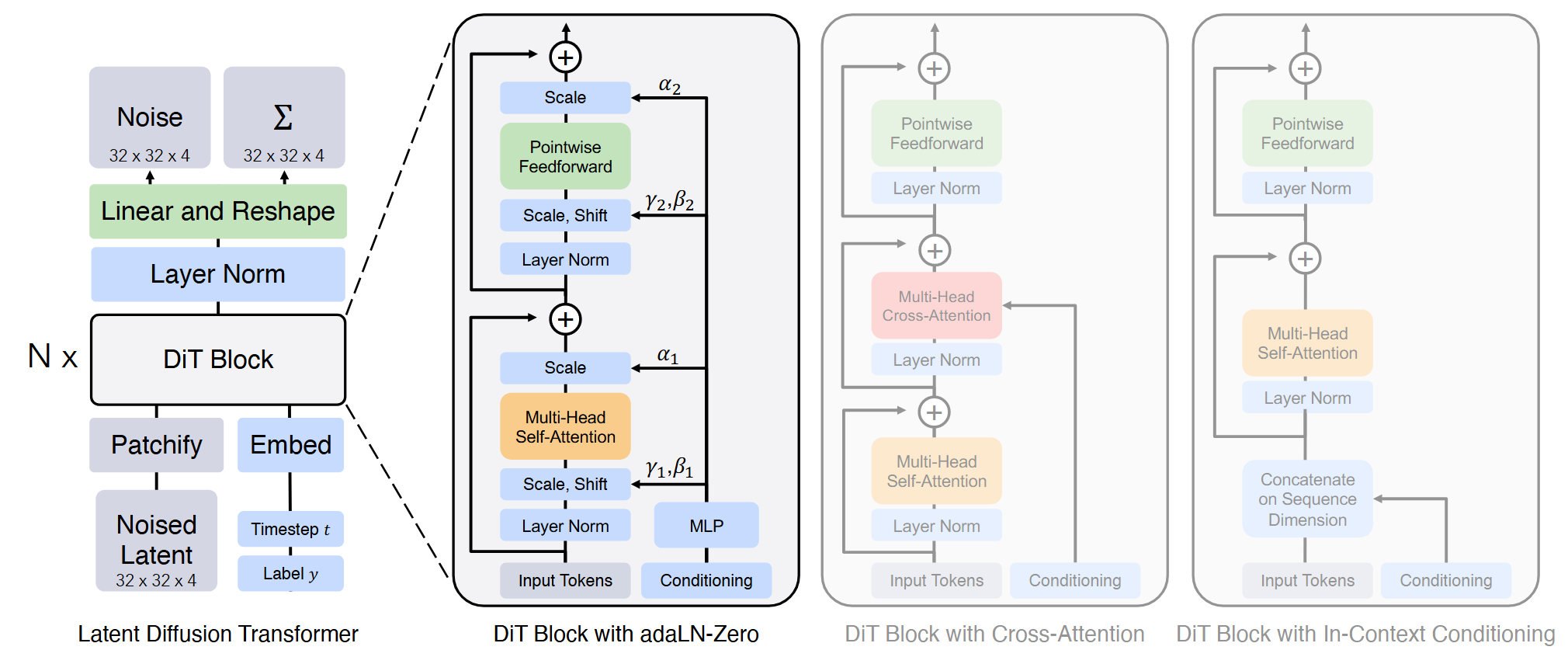
Scalable Diffusion Models with Transformers
摘要基于transformer结构构建了一类新的扩散模型,DiT。即使增加transformer的深度/宽度或者增加输入tokens的数量,依旧能够保持更低的FID。最大的DiT-XL/2模型在ImageNet 512×512和256×256基准上性能优于所有先前的扩散模型,在后者上实现了2.27的FID。 方法预备知识1.扩散模型前向加噪过程:对真实数据逐步添加噪声: x_{0}: q(x_t|x_0)={\cal N} ( x_{t} ; \sqrt{\bar{\alpha}_{t}} x_{0}, ( 1-\bar{\alpha}_{t} ) {\bf I} ) x_{t}=\sqrt{\bar{\alpha}_{t}} x_{0}+\sqrt{1-\bar{\alpha}_{t}} \epsilon_{t}, \quad where\quad\epsilon_{t} \sim{\mathcal{N}} ( 0, \mathbf{I} )对扩散模型进行训练,学习正向加噪过程的反向过程: p_{\theta}\left(x_{t-1} \mid...
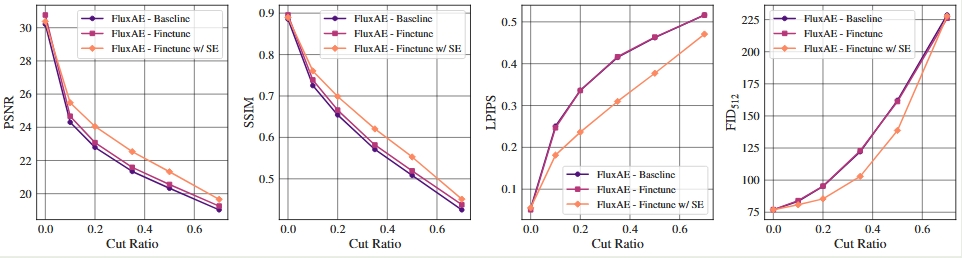
2025-02-28
Improving the Diffusability of Autoencoders
摘要鲜有人研究autoencoder和diffusion model之间的相互作用 autoencoder潜在空间中的高频分量会影响diffusion生成过程与质量 提出scale equivariance的正则化策略,在decoder中对潜在空间与RGB空间进行频率对齐 只需要改变较少的代码,20K步autoencoder的微调,就能够提高生成质量 简介Diffusability描述了通过扩散过程对分布进行建模的难易程度:高Diffusability表示分布易于拟合,而低Diffusability则使过程更加复杂 扩散模型鼓励误差累积推迟到频谱的高频部分,但是如果autoencoder的潜在低频部分与RGB空间中的对应部分的对应关系丢失了,就会影响重建的准确性。 现有的autoencoders中的潜在空间中存在突出的高频分量,与RGB信号中的频谱分布存在明显偏离,会影响重建的RGB结果,造成明显的视觉伪影。 标准的KL正则化不足以处理频谱缺陷,甚至可能放大问题。 方法背景:Blockwise 2D DCT给定以为二维信号块...

2025-07-13
Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models
摘要具有Transformer架构的潜在扩散模型在生成高保真图像方面表现出色。然而近期的研究揭示了这种两阶段设计中的优化困境:虽然增加视觉 tokenizers 中每一个 token 的特征维度能够改善重建质量,但是需要更大的扩散模型和更多的训练迭代来实现可比的生成性能。 现有的系统得到的是次优的解决方案,由于 tokenizers 中信息的损失会产生视觉伪影,由于高昂的计算成本而无法完全收敛。 上述困境来源于学习无约束高维潜在空间的固有困难。 提出在训练视觉 tokenizers 的时候将潜在空间和预训练的视觉基础模型相对齐。提出VA-VAE(视觉基础模型对齐的变分自编码器),使DiT在高维潜在空间获得更快地收敛。 构建了增强的DiT基线,改善了训练策略和结构设计,称为LightingDiT。 贡献提出的视觉基础模型对齐损失解决了潜在扩散模型中的优化困境,使DiT在高维...
最新文章



