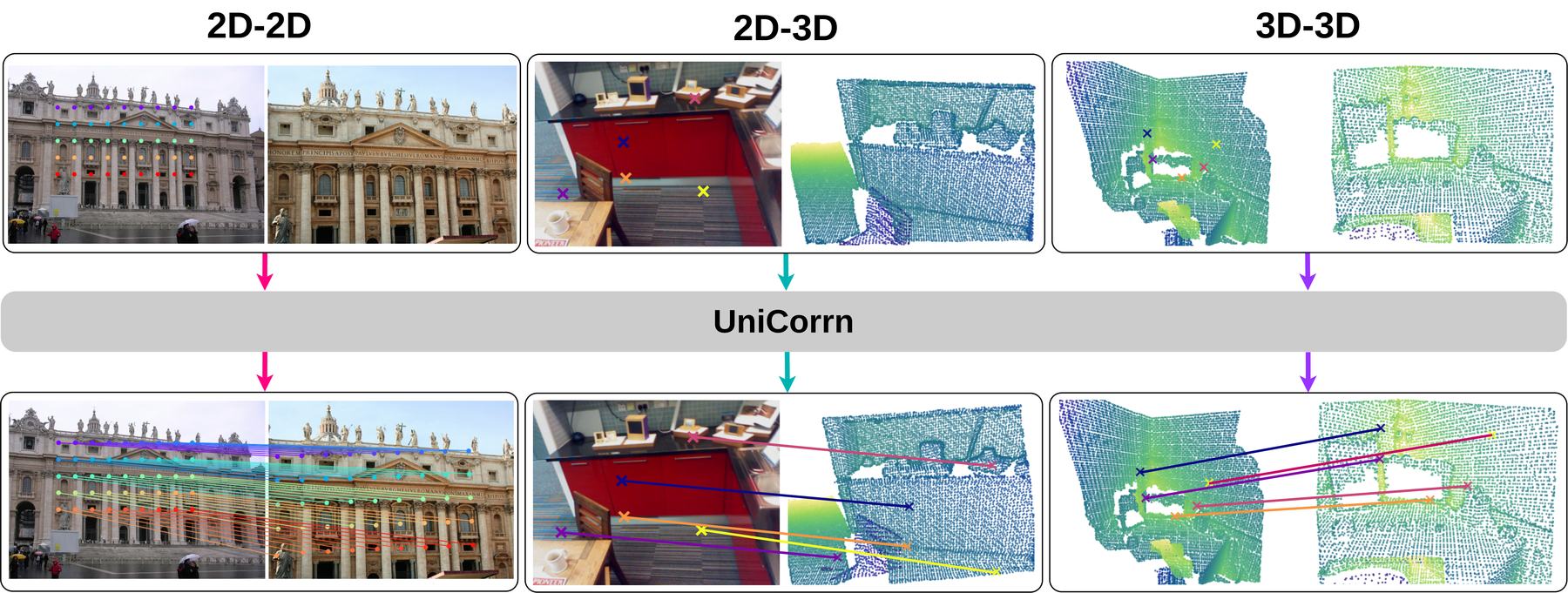
VGGT-Ω
作者:Jianyuan Wang, Minghao Chen, Shangzhan Zhang, Nikita Karaev, Johannes Schönberger, Patrick Labatut, Piotr Bojanowski, David Novotny, Andrea Vedaldi, Christian Rupprecht
单位:Visual Geometry Group, University of Oxford; Meta AI
会议:CVPR 2026 Oral / 2026 Arxiv
链接:https://arxiv.org/abs/2605.15195, Project Page
研究动机
VGGT-Ω 这篇文章关心的不是“能不能再把 VGGT 做强一点”,而是一个更底层的问题:前馈式三维重建模型是否也像语言模型、2D 视觉基础模型一样,具有可预期的 scaling law。原始 VGGT 已经证明了 feed-forward reconstruction 可以在很多场景中接近甚至超过传统 SfM/优化式方法,但它仍然有几个限制:
- 全局 attention 让多帧之间可以交换信息,但 token 数随帧数增长,训练和长序列推理都会变贵。
- DPT 式多头 dense decoder 很吃显存,尤其是高分辨率卷积特征的 activation。
- 只靠公开重建数据很难覆盖动态视频和真实互联网视频的复杂分布。
- 如果想让三维重建模型成为 3D/4D 基础表征,模型不应只输出深度和相机,还应该产生能被 VLA、语言对齐等任务复用的 scene-level token。

论文的核心问题可以概括为:
能不能把 VGGT 这类前馈式重建模型系统性地放大到更多数据、更大模型、更长视频,同时保持训练效率,并让学到的三维表征能服务于重建之外的空间理解任务?
Fig.1 给出的答案很直接:模型从 1B 扩到 10B、数据从 2K 扩到 2M sequences 时,3D point error 持续下降。这是本文最重要的信号,因为它把三维重建从“工程管线调参”推进到了“可规模化基础模型”的叙事里。
核心方法
VGGT-Ω 仍然是一个前馈 Transformer:输入 N 张图像,输出每张图的相机参数和深度图。相机参数包含旋转四元数、平移和 field of view;主点默认在图像中心。与原始 VGGT 的关键差异是,它不再直接预测 point map 和 tracking feature,而是只保留 depth head 与 camera head,同时把 point/matching 作为训练时的辅助 loss。

1. Register attention:把跨帧通信压缩到 scene tokens
VGGT 使用 alternating attention:一类是 frame-wise attention,在每帧内部做 self-attention;另一类是 global attention,让所有帧的所有 token 互相通信。Global attention 是多帧几何信息形成的地方,但也是最贵的地方。
VGGT-Ω 在每帧中加入 1 个 camera token 和 16 个 register,也称 scene tokens。它把 25% 的 global attention layer 替换为 register attention:跨帧时只让各帧的 registers 互相 attend,图像 patch token 不直接参与跨帧全局 attention。更新后的 registers 再通过后续 frame-wise attention 把全局场景信息分发回局部图像 token。

这个设计背后的观察是:原始 VGGT 的 global attention 矩阵本身很稀疏,说明真正需要跨帧交换的信息可能只集中在少量 token 上。论文实验显示,只替换 25% global attention 基本不损失精度,point error 从纯 global attention 的 0.071 到 0.073,但训练时 backbone FLOPs 下降约 23%,显存下降约 16%。如果全部替换成 register attention,FLOPs 可以降到原来的 6%,但精度退回到接近原始 VGGT 的水平,所以本文选择了更稳的折中。
2. 单 dense head,多任务 loss
原始 VGGT 会显式预测 depth、point map、track 等多个 dense head。VGGT-Ω 的判断是:多任务监督确实有用,但多 dense head 不一定必要。它只保留一个 depth head,同时用 camera loss、depth loss、point loss 和 matching loss 共同训练:
Point map 并不是模型直接输出,而是由预测的 depth 和 camera 反投影得到,再和 GT point map 对齐。Matching loss 则作用在最后一层 attention token 上,把对应同一 3D 位置的 token 拉近,把负样本推远。这个做法保留了多任务学习带来的几何约束,但避免了多个 dense prediction head 的显存负担。
3. 轻量 dense decoder:MLP + pixel shuffle,但保留低分辨率卷积
高分辨率 DPT 卷积块的参数量不一定大,但训练时 activation 很贵。VGGT-Ω 把 1/4 分辨率以上的重型卷积层替换成单个 MLP 加 pixel shuffle。MLP 输出 $2u^2$ 个通道,pixel shuffle 还原到更高空间分辨率,两个输出通道分别对应 depth 与 confidence。
论文也试过完全去掉卷积,用纯 MLP 做 dense decoding。定量上可以工作,但深度图会出现块状 artifact,尤其是天空、远山这类深度无界的户外区域。因此最终保留了低分辨率的浅层卷积,用很小的计算代价换取更平滑的几何输出。
4. 动态场景:只预测 depth 和 camera,而不显式预测 motion
动态重建的难点是相机运动和物体运动容易纠缠。一些方法用 point map 或 ray map 表示动态几何,但这会引入额外 dense output,也可能把像素外观变化和相机信息混在一起。VGGT-Ω 选择更克制的输出:只预测 depth map 和 camera 参数,不直接预测 motion mask 或 dynamic point map。
这听起来更少,但好处是模型必须从大规模数据中学习动态先验,而不是在输出形式里强行引入复杂结构。后面的 motion-aware 可视化也表明,即使没有显式运动监督,模型中间层 token 仍然能自动分离运动主体。
5. Teacher-student 自监督:用无标注视频扩展分布
VGGT-Ω 的自监督不是从零开始,而是从 supervised checkpoint 初始化 teacher 和 student。两者看同一组视频帧,但接受不同增强,包括颜色扰动、模糊、90 度旋转、patch masking 和帧顺序重排。恢复到同一顺序后,student 需要匹配 teacher 的多层 token、camera 和 depth 预测;teacher 通过 EMA 更新。为了防止 collapse,自监督阶段冻结 camera/depth heads。
这部分很像 DINO 系列在 2D 视觉中的 teacher-student 思路,但论文也很坦诚:自监督主要改善泛化,benchmark 上提升有限。它不是本文最“漂亮”的结果,却是非常重要的经验,因为三维自监督在动态场景下仍然不稳定。
数据集
训练数据分两部分。
第一部分是约 3M sequences 的公开和内部标注数据,覆盖 Aria、Co3Dv2、uCo3D、DL3DV、Dynamic Replica、HOT3D、Hypersim、MegaDepth、ScanNet 系列、TartanAirV2、Virtual KITTI、Waymo、WildRGBD 等。作者明确排除了 VGGT 使用过的 Kubric 和 PointOdyssey,因为它们的背景几何是假背景,会产生无效深度。
第二部分是约 40M 条内部互联网风格视频。VLM 先过滤掉不适合多视图重建的视频,例如多段剪辑拼接、严重水印、运动模糊或 parallax 不足的视频。通过初筛的视频可用于自监督;其中一小部分进入伪标注管线。标注管线包含:
- VLM 预过滤并判断动态/静态属性。
- Grounding DINO 检测人、车等可能运动物体,并在匹配与验证阶段排除这些区域。
- SIFT、SuperPoint+SuperGlue、ALIKED+LightGlue、VGGSfM Tracker 组成匹配和 tracking ensemble。
- 用 VGGT 初始化困难场景的相机,再用 COLMAP 做 bundle adjustment。
- 用 field of view、畸变比例、注册率、多视图深度一致性等规则过滤失败样本。
- 人工标注 500 个静态和 500 个动态 sequence,训练 XGBoost、Random Forest、CatBoost ensemble 做最终几何质量过滤。
最终得到约 600K 静态场景和 200K 动态场景的高质量 camera/depth 标注。作者反复强调目标不是最大化 yield,而是宁可丢掉模糊样本,也不要把噪声伪标签灌进大模型训练。
算力
论文给出的训练设置很具体:
- 模型规模包含 200M、500M、1B、10B 四档,alternating-attention blocks 分别为 12/12/24/16,hidden size 分别为 384/768/1024/4096。
- Backbone 从 DINOv3 初始化,训练时不冻结。
- 总训练 240K iterations:160K supervised,50K self-supervised,最后 30K supervised。
- 每个 batch 随机采样 1 到 24 帧,图像面积约为 512 × 512,并使用颜色扰动、灰度化、随机 patch masking 等增强。
- 训练使用 128 张 96GB H100 GPU,bfloat16 mixed precision,gradient checkpointing 和 FSDP。
- 推理速度/显存测试使用单张 80GB A100,PyTorch scaled_dot_product_attention 与 flash attention v2 backend。
一个值得记住的数字是:VGGT-Ω 训练时只使用原始 VGGT 约 30% 的 GPU memory,这使得它可以使用 15× 更多监督数据,并进一步吃进 18M 无标注视频。
补充材料里还给出了一些很工程化的稳定训练细节。Camera、depth、point、matching 四个 loss 的权重分别是 5.0 / 1.0 / 0.5 / 0.1;训练时把 GT 统一归一化到第一帧相机坐标下的 unit space,但不在线归一化模型预测;attention 内部使用 QKNorm,并把 gradient-norm clipping 设为 1.0。每个 iteration 随机采样 1-24 帧,视频类数据优先从局部时间窗口采样,而不是只按共视关系采样。这个选择会制造一些语义相关但视觉重叠很少的训练子序列,作者认为它能提升泛化能力。
自监督阶段还有两个容易被忽略的设置:teacher 通过 EMA 更新,decay 为 0.999;camera/depth head 会被冻结,避免 student-teacher 在几何输出上互相拖向 collapse。也就是说,本文的自监督更像是在扩展 backbone 表征的分布覆盖,而不是重新学习几何解码器。
实验结果
1. 定量结果:静态和动态都明显提升
论文在三个静态数据集和三个动态数据集上评估:静态包括 7 Scenes、NRGBD、ETH3D;动态包括 DyCheck、Sintel、TUM-Dynamic。每个 scene/sequence 随机采样 10 帧。

Fig.4 展示了交通、网球、自然景观、水下珊瑚等场景。关键点不是图漂亮,而是模型能同时处理静态结构和非相机运动。对于一个不显式输出 motion mask 的模型,这说明动态先验确实被吸收到表示里。

Table 1 是相机位姿估计。VGGT-Ω 在所有静态/动态 benchmark 上都优于 MonST3R、MapAnything、MegaSaM、VGGT、PI3、DA3 等基线。最醒目的结果是 Sintel:AUC@3° 从 MegaSaM 的 22.5 提升到 40.0,相对提升 77%;AUC@30° 从 58.3 提升到 79.1。

Table 2 是深度估计。VGGT-Ω-10B 在 Sintel 上把 $\delta{1.25}$ 从 DA3 的 86.1 提升到 93.5,AbsRel 从 0.118 降到 0.081。在 TUM-Dynamic 上也达到 98.3 的 $\delta{1.25}$ 和 0.035 的 AbsRel。更大的 10B 模型几乎总是优于 1B,说明 scaling 对 camera 和 depth 都有效。
2. 定性结果:动态、稀疏、航拍、重复纹理都更稳定

Fig.5 对比 MegaSaM。MegaSaM 依赖优化,在稀疏室内、航拍、大 roll 角或纹理不足场景里容易出现几何漂移、平面错位或结构断裂。VGGT-Ω 的点云整体更连贯,尤其是航拍场景里没有那么明显的 repeated pattern 和全局形变。

Fig.6 对比 Depth Anything 3。DA3 在雪地缆车这种重复纹理场景里几乎估不出正确相机运动,在无人机绕塔场景中还会出现 ghosting 和重复塔结构。VGGT-Ω 更像一个“场景级重建模型”,而不是逐帧深度模型,因此对 camera trajectory 的约束更强。
3. 速度和显存:长视频推理友好

推理上,VGGT-Ω 和修正缓存策略后的 VGGT 都能在单张 80GB A100 上处理约 1250 帧,DA3 在约 750 帧附近 OOM。VGGT-Ω 的速度优势主要来自两个点:DINOv3 patch size 为 16,比 DINOv2/VGGT 的 14 减少约 25% 图像 token;默认替换 25% global attention 为 register attention,带来约 20%-25% 的速度提升。若全部使用 register attention,1000 帧 runtime 可从 240.2s 降到 11.7s,但精度明显下降。
4. Scene tokens 的下游价值:VLA 与语言对齐

Table 3 把 VGGT-Ω 的 frozen scene tokens 接到 OpenVLA-OFT 输入中,在 LIBERO benchmark 上平均成功率从 97.1 提升到 98.5。增幅不大但方向清晰:registers 不只是为了省 attention,它们真的承载了对机器人任务有用的空间信息。

Fig.8 做语言对齐:VLM 为视频序列生成描述,VGGT-Ω 端只允许一个 learnable language token 读取 registers,而不能直接看 image patch tokens。对齐后,在 100 个手工整理的互联网视频检索 benchmark 上,使用 VLM embedding 时 top-1 为 76.8%、top-3 为 97.0%;换成 text-only LLM embedding 且不再训练时,仍有 47.5% top-1 和 77.8% top-3。这说明 registers 包含可对齐到自然语言的 scene-level 信息。

Fig.9 则展示了一个很有趣的 emergent property:对中间层 image tokens 做 PCA 降维和 k-means 聚类,不用 optical flow、不用标签、不用 probe,某个 cluster 仍然可以跟踪跳舞的人。早层的运动分割最干净,中间层仍保留运动信号,深层则更偏全局和语义。这是本文关于“重建作为空间理解 proxy task”的一个强证据。
5. 设计讨论与未来路线
论文后半部分和补充材料最有价值的地方,是作者没有只报一个更强的 10B 模型,而是把很多“为什么这样设计”的经验摊开了。这些内容让 VGGT-Ω 更像一篇关于未来 3D foundation model 形态的论文。
第一个判断是:保持 base model 简单,比把当前 benchmark 分数榨到极限更重要。作者承认,他们可以加入原始 VGGT 那种 iterative camera refinement,也可以把原始 RGB 注入 dense head;这些技巧在多数据集上还能带来 4%-6% AUC@3° 和约 2% δ1.25 的额外提升。但他们最终没有把这些都塞进主模型,因为目标是训练一个干净、可复用的 aggregator。补充材料里甚至写到:只要 backbone 训练好了,一个新的预测 head 通常 5-10K iterations 就能训起来。这个选择说明 VGGT-Ω 的核心产物不是 depth head 本身,而是可被很多 3D/4D 任务复用的空间表征。
第二个判断是:register attention 不是越多越好。全量 register attention 可以把 FLOPs 降到原始 global attention 的 6%,但性能会退回到接近原始 VGGT 的水平。作者最后只替换 25% global attention,本质上是在说:scene tokens 可以压缩跨帧信息,但 patch token 之间的直接全局通信仍然保留了细粒度几何对齐能力。这个结论对未来端侧模型也很有启发:如果目标是手机、AR 眼镜或机器人实时部署,全 register attention 可能值得牺牲一部分精度;如果目标是通用基础模型,25% 替换更像当前的稳态折中。
第三个判断是:辅助输入适合微调,不一定适合预训练。理论上,时间顺序、相机参数、已有深度、尺度因子都能帮助重建;但作者发现,在预训练阶段随机加入或 mask 这些先验反而常常有害。相反,如果只在下游微调时提供这些条件,收益更稳定。这给后续模型一个很清楚的方向:pretraining 阶段尽量学习不依赖特定接口的通用空间表征,finetuning 阶段再把任务条件显式接进来。
第四个判断是:自监督 3D 还远没有被解决。作者试过很多替代协议,包括 new view synthesis、类似 RayZer / E-RayZer 的方法、生成 token 而不是像素、NeRF / Gaussian Splatting 表示、mask image tokens、跨帧区分物体、加入时间顺序等,最后只有 teacher-student 在他们的实现里稳定有帮助。更关键的是,这套自监督主要提升 OOD 泛化,对常规 benchmark 提升有限,而且仍然需要 supervised checkpoint 起步。作者原本预期 reconstruction 天然包含 2D 自监督里的 invariance,但动态场景让这个直觉变得不稳。这里其实点出了一个未来趋势:3D 自监督可能不能只靠“重建自己”,而要并入更大的 multi-modal / omni-style 训练系统。
第五个判断是:MLP-only dense decoder 是未来方向,但现在还差一个几何数值建模问题。补充讨论里说,纯 MLP head 往往定量指标不错,而且更快、更省显存、梯度也更稳定;问题是人眼会看到明显 patch / block artifact,尤其是户外远距离物体和天空附近。作者推测原因在于图像生成的输出数值空间相对有界,而 depth 这类几何量本质上无界。最后保留低分辨率浅层卷积,是一个务实折中:用很小计算量补掉 MLP-only 的空间不连续。未来如果有人能把无界几何量编码成更适合 token decoding 的形式,dense head 可能会进一步从卷积结构里解放出来。
补充材料里的 data quality 讨论也很重要,因为它直接解释了三维重建 scaling 和 2D/LLM scaling 的差异。2D 预训练最怕的是语义噪声,3D 预训练更怕“看起来合理但几何错误”的伪标签。作者列了几类典型问题:深度传感器会把椅背打到背景墙上;合成数据里的栏杆、细杆等 thin structures 会被错误地贴到后面的墙或天空;Kubric、PointOdyssey、BEDLAM 这类合成数据可能存在 fake background;COLMAP / MegaSaM / ViPE 伪标签可能出现 doming effect;MegaDepth 这类街景/旅游照片会把行人边界错误融合进静态建筑;不同数据集对窗外景物到底标成玻璃表面还是远处真实物体也不一致。更麻烦的是,这些错误不一定会体现在常规 benchmark 上,却会在新样本上被模型“记住”并复现出来。
因此,VGGT-Ω 暗示的未来路线不是单纯“更多视频 + 更大模型”,而是三件事同时推进:
- 更强的数据过滤和伪标注诊断,尤其要能识别局部 reprojection error 很低但全局几何已经弯掉的样本。
- 把 feed-forward reconstruction 当成 SfM / BA / NeRF / Gaussian Splatting 的强初始化,而不是完全替代优化式几何。
- 让 3D/4D reconstruction 成为大模型预训练里的一个原生任务:短期可以把 depth、camera 和 registers 作为外部空间工具;长期则可能把 camera 参数当成可自回归预测的 text-like token,把 depth / geometry 当成 image-like generation target,和语言、视频、动作、世界模型一起训练。
这也是论文最后最有野心的观点:下一代 reconstruction model,甚至更广义的 perception system,可能不是一个只服务三维重建的专用网络,而是 unified model 的一部分。数据会是最大瓶颈,多任务一致性会缓解单一感知任务的欠约束,生成式视觉模型更容易 scaling 的趋势也可能反过来推动 perception。
优势与不足
优势
- 这篇文章不是单纯堆参数,而是同时解决了架构、数据、训练和表示复用四个层面的 scale bottleneck。
- Register attention 的设计很干净:它既是效率手段,也是表示学习手段。省下的计算不是来自粗暴删 token,而是把跨帧信息压缩到 scene tokens。
- “只输出 depth/camera,多任务只作为 loss”这个选择很有启发。它把推理接口做简单,同时保留 point/matching 监督带来的几何约束。
- 数据管线强调质量优先,尤其是动态区域 masking、多视图一致性和 supervised geometric filtering,比较符合大规模伪标注训练的现实。
- 论文没有只停留在 benchmark,而是用 VLA、语言对齐、motion clustering 证明 registers 有下游表征价值。
- 作者对负结果和工程折中写得很充分:self-supervised training、MLP-only dense head、辅助输入、全 register attention 都不是简单失败,而是给后续研究留下了清晰边界。
不足
- 成本极高。128 张 96GB H100 和 10B 模型规模意味着这条路线目前不是普通实验室可完整复现的。
- 关键数据包含内部互联网视频和内部数据,论文报告了流程和规模,但外部研究者很难验证数据分布、过滤策略与最终性能之间的因果关系。
- 自监督部分更像有效经验而不是成熟范式。作者也承认 teacher-student 方法主要改善泛化,benchmark 收益有限,且仍依赖 supervised pretrained checkpoint。
- 对动态场景的能力仍然依赖训练分布。论文没有显式输出 motion,因此遇到极端非刚体、遮挡复杂、运动主体占比很高的场景时,失败模式可能不容易诊断。
- MLP-only dense head 的 artifact、天空/无效区域深度粘连、噪声数据记忆等问题说明几何输出仍然不像 2D 表征那样“自然可解码”。
- 补充材料承认强 motion blur、几秒内从
10°跳到160°的剧烈 FoV 变化、高畸变相机、含大量显示器的办公室场景,以及人脸/商标遮挡区域,都可能让预测变得不稳定。这些不是小瑕疵,而是动态互联网视频进入训练分布后必须长期处理的现实问题。

Fig.10 的附录数据问题很值得看:ScanNet++、Hypersim 以及 doming effect 都会产生不理想监督。这里暴露出一个现实问题:三维重建模型的 scaling 不是只靠更多视频,几何标签质量可能比样本数更硬。
记忆点
- Feed-forward reconstruction 也出现了清晰的 scaling 信号:更大模型和更多数据都能稳定降低 point error。
- Registers 可以同时是效率瓶颈的解决方案和 scene-level 表征的承载体。
- 多任务监督不等于多任务输出。把 point/matching 放在训练 loss 里,把推理输出收缩为 depth/camera,是一个很好的系统设计。
- 动态重建未必需要显式 motion output;足够强的数据先验可以让 motion-aware representation 从重建目标中自然浮现。
- 三维基础模型的真正瓶颈可能是高质量几何数据和可规模化自监督,而不只是网络结构。
- 对下游任务而言,重建模型的 registers 可能会成为一种“结构化空间 token”,连接 3D perception、VLA 和语言模型。
- VGGT-Ω 最值得延伸的观点是:未来 3D/4D perception 可能不会孤立存在,而会作为 unified / omni model 的一个训练任务,与语言、视频、动作和生成式世界模型一起吸收监督信号。
 微信
微信 支付宝
支付宝