TRELLIS2: Native and Compact Structured Latents for 3D Generation
作者: Jianfeng Xiang, Xiaoxue Chen, Sicheng Xu, Ruicheng Wang, Zelong Lv, Yu Deng, Hongyuan Zhu, Yue Dong, Hao Zhao, Nicholas Jing Yuan, Jiaolong Yang
单位: Tsinghua University, Microsoft Research, USTC, Microsoft AI
会议: 2025 Arxiv
TRELLIS.2 这篇文章的核心问题很直接:如果 3D 生成模型想同时拥有高分辨率几何、复杂拓扑、内部结构、开表面,以及真实 PBR 材质,latent 表示本身就不能再只是“把某个网格或连续场压一下”。作者提出 O-Voxel 作为原生 3D 资产表示,再用 SC-VAE 把 1024³ 级别资产压到约 9.6K 个 latent tokens,最后训练总规模约 4B 参数的 flow matching 生成模型,把 image-to-3D、PBR 纹理和高分辨率 test-time scaling 串成一个完整系统。

研究动机
上一代 3D 生成方法通常卡在两个地方。第一类方法偏向连续场或高斯表示,训练和渲染友好,但把结果真正转成可编辑、可生产使用的 mesh 和 PBR 材质时会遇到结构和贴图的落差。第二类方法直接面向 mesh 或稀疏体素,几何更接近资产格式,但要兼顾任意拓扑、非流形、开表面、内部结构和材质时,表示会变得笨重。
TRELLIS.2 的动机是把“生成模型喜欢的 latent”和“3D 资产真正需要的结构”合在一起。它不是先生成一个看起来不错的代理表示,再后处理成资产,而是从一开始就在一个原生、稀疏、可双向转换的 3D 表示里建模几何和材质。这样做的好处是:模型可以在生成阶段就理解结构和材质的对齐关系,而不是把 texture baking、mesh extraction、material synthesis 这些问题丢给后处理。
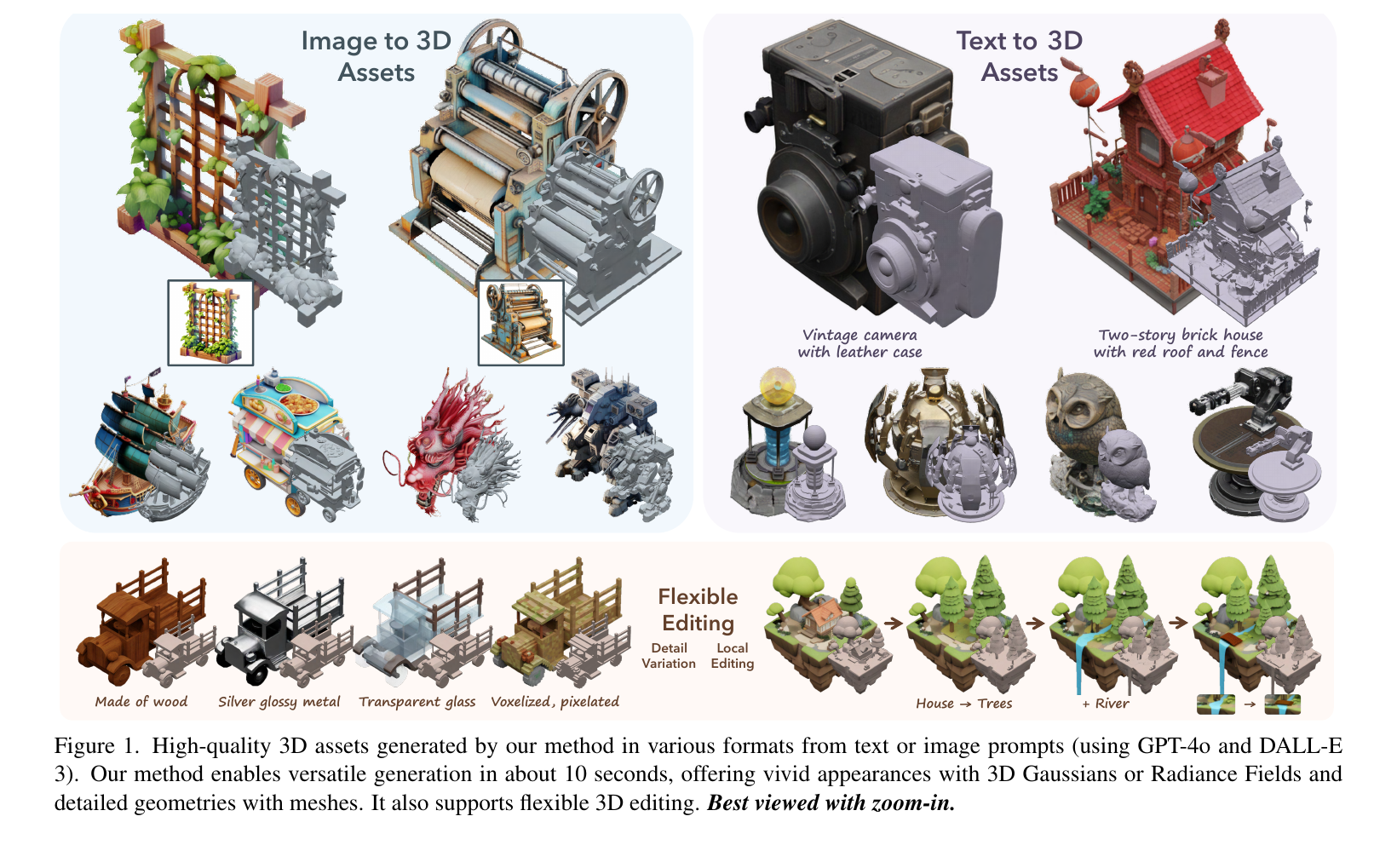
从结果图看,作者尤其强调三点:复杂几何细节、内部/非流形结构,以及 PBR 材质的物理一致性。也就是说,TRELLIS.2 想解决的不是“能不能从图生成一个 3D 物体”,而是“生成出来的东西能不能更像可用资产”。
核心方法
整套方法可以拆成三层:底层是 O-Voxel 表示,中间是 SC-VAE 压缩 latent,顶层是三阶段 flow matching 生成模型。

第一层:O-Voxel。 O-Voxel 是一种 field-free 的稀疏体素结构,用体素局部结构表达几何和材质。它把 shape 写成 Flexible Dual Grid,包括 dual vertices、交叉标记和 splitting weights,用来表达复杂表面;同时把 material 写成体积化表面属性,包括 Base Color、Metallic、Roughness 和 Alpha。这样,一个表示里既有几何,也有 PBR 材质。

O-Voxel 的关键不是“又一种 voxel”,而是它能在 raw 3D asset 和模型 latent 之间做即时双向转换:mesh 可以转进 O-Voxel,O-Voxel 又可以转回 mesh 和材质贴图。相比需要优化或渲染拟合的表示,这对大规模训练和资产落地都更友好。论文中特别强调它可以处理 open、non-manifold、fully enclosed surfaces 这类传统表示容易出问题的拓扑。
第二层:SC-VAE。 有了 O-Voxel 后,还需要把它压成生成模型能承受的 token 数量。SC-VAE 是一个全稀疏卷积的 U-shaped VAE,核心设计包括 sparse residual autoencoding、early-pruning upsampler 和优化后的残差块。它把 O-Voxel 做 16 倍空间下采样,把 fully textured 1024³ 资产压到约 9.6K latent tokens。

SC-VAE 的训练分两阶段。低分辨率阶段主要稳定几何重建,用 O-Voxel reconstruction loss 和 KL loss;高分辨率阶段加入渲染感知监督,包括 mask、depth、normal、material 相关信号,以及 SSIM/LPIPS 这类感知损失。这个设计背后的判断是:如果只在表示空间约束,细节和材质不一定符合视觉质量;如果只用渲染监督,又可能不够稳定。所以作者把“结构可逆”和“视觉可感知”两种约束叠在一起。
第三层:三阶段生成。 在压缩 latent 上,TRELLIS.2 使用 DiT 风格的 flow matching 模型,并把生成分为三个阶段:sparse structure generation、geometry generation 和 material generation。前两阶段生成稀疏结构和几何骨架,第三阶段在原生 3D latent 空间里生成 PBR 材质。这样材质不是贴在几何之后的附属物,而是和几何 latent 对齐生成。
这个三阶段拆法很重要。稀疏结构决定哪里有东西,几何决定局部形状,材质决定外观属性。把它们强行放进一个一步生成模型里,训练难度和 token 负担都会上升;拆开后,每个模型的任务更清楚,也更容易做高分辨率扩展。
数据集
训练数据主要来自 TRELLIS-500K 设置,并过滤掉没有 PBR 材质的资产,形成来自 Objaverse-XL、ABO 和 HSSD 的 curated collection。为了增强材质多样性和真实感,生成模型还使用了扩展到约 800K assets 的集合,并引入 TexVerse。对于 image-conditioned 训练,作者在 Blender 中为每个资产渲染 16 个视角,随机化 FoV 和光照。
评测部分分成几类。重建任务使用 Toys4K benchmark,以及一个作者整理的 Sketchfab 测试集,后者包含近两年发布的 90 个复杂 PBR 材质和细节形状资产,并且训练时不可见。生成质量比较和用户研究使用 100 个 AI-generated image prompts,以减少训练测试重合。用户研究约 40 名参与者,在相同输入条件下比较不同方法的生成结果。
这个数据设计和论文主张是对应的:如果目标只是看外轮廓,普通 Objaverse 风格评测就够了;但 TRELLIS.2 要证明的是内部结构、复杂材质和 PBR 一致性,所以它需要额外看 Sketchfab 复杂资产、材质重建和用户偏好。
算力
论文给出的模型规模相当明确:生成框架包含三个 DiT 模块,每个约 1.3B 参数,总规模约 4B。训练时使用 AdamW、classifier-free guidance,并采用 progressive training,从 512³ 输出逐步扩展到 1024³ 输出。论文正文中写到每个 DiT 在 32 张 H100 GPU 上训练,batch size 为 256;SC-VAE 训练使用 16 张 H100 GPU,batch size 为 128。运行统计则在 NVIDIA A100 上报告。
推理侧,项目 README 给出的门槛是至少 24GB 显存的 NVIDIA GPU,官方验证过 A100 和 H100。论文中强调了高分辨率推理效率:在 H100 上,512³ 大约 3 秒,1024³ 大约 17 秒,1536³ 大约 60 秒;Fig.1 中 1536³ 示例约为 35 秒 shape generation 加 25 秒 texture generation。
从工程角度看,这不是轻量模型,但它的卖点也不是低资源消费,而是在 3D 资产级别把“表示压缩”和“生成质量”同时拉高。9.6K tokens 对 1024³ fully textured asset 来说已经很紧凑,这也是后续能训练 4B 级 flow 模型的前提。
实验结果
3D 资产重建。 Table 1 比较了不同结构化 latent 在重建任务中的效率和质量。TRELLIS.2 在 512³ 设置下只用约 2.2K tokens,在 1024³ 设置下约 9.6K tokens,并保持 16 倍下采样。和 Dora、TRELLIS、Direct3D-S2、SparseFlex 相比,它在 Toys4K 和 Sketchfab 上的 MD、F1、Normal PSNR、LPIPS 等指标整体更好,同时 decoder 时间也很低。尤其 1024³ 版本在 Sketchfab 的 Normal PSNR 达到 35.26,说明复杂真实资产上也能保住表面质量。

生成质量。 Fig.5 展示了 TRELLIS.2 的代表性生成结果,重点不是单个物体“像不像”,而是它能生成细枝、机械齿轮、封闭驾驶舱、透明/反射材质等传统 3D 生成容易失真的结构。论文的叙述里,几何和材质的对齐是核心卖点:复杂几何不是贴图伪装出来的,PBR 外观也不是简单颜色贴图。

Fig.6 和 Hunyuan3D 2.1、Step1X-3D、TRELLIS、Direct3D-S2、Hi3DGen 做视觉比较。图中主图是 normal,小图包括 final render、base color、metallic 和 roughness。这个比较很有信息量:一些基线能生成看起来合理的正面结果,但 PBR 分解或几何细节不够稳定;TRELLIS.2 的优势在于 normal、最终渲染和材质通道之间更一致。

Image-to-3D 定量结果。 Table 2 显示 TRELLIS.2 在 image-conditioned 生成上拿到最高的对齐和偏好分数:CLIP 0.894、CLIP-N 0.758、ULIP-2 0.477、Uni3D 0.436,用户偏好 Pref 为 66.5%,Pref-N 为 69.0%。这组指标说明它不仅图像对齐更好,3D 几何相似性和主观质量也更强。

PBR 纹理生成。 Fig.7 把第三阶段 material generation 单独拿出来评估:给定 shape 和参考图,模型生成 3D PBR 纹理。对比 Hunyuan3D 2.1 和 TEXGen,TRELLIS.2 的纹理更少出现多视角不一致、ghosting 或 UV 歧义带来的模糊。原因在于它不是在 2D 多视图里拼贴纹理,而是在原生 3D latent 中做材质生成。

消融实验。 Table 3 说明 SC-VAE 的设计不是装饰。f16c32 版本在 token 数、解码速度和重建质量之间取得较好平衡;去掉 residual autoencoding 或 optimized ResBlock 后,MD、F1、PSNR、LPIPS 都会明显变差。更强压缩的 f32c128 token 数更低,但几何和视觉质量下降,说明 3D latent 不能只追求 token 少。

Test-time scaling。 Fig.8 展示了推理时提高分辨率和计算量后,生成细节继续变好。这一点对 3D 资产生成很关键,因为很多应用需要的不是固定 512³ 输出,而是能根据场景预算扩展到 1024³ 或 1536³。TRELLIS.2 的 compact latent 让这种扩展更现实。

优势与不足
TRELLIS.2 最大的优势是把 3D 表示、压缩 latent 和生成模型统一到了资产级目标上。O-Voxel 让复杂拓扑和 PBR 材质进入同一个原生表示;SC-VAE 把高分辨率资产压到可训练的 token 数;三阶段 flow 模型则把结构、几何、材质分层生成。三者叠起来,才形成了论文里展示的高保真资产生成。
第二个优势是工程闭环比较完整。论文不只给 teaser,也给了重建速度、token 数、PBR 材质通道、用户偏好和 test-time scaling。项目页和代码仓库也明确把它定位为 4B image-to-3D 模型,并给出 512³ 到 1536³ 的模型能力范围。
不足也很清楚。首先,训练资源和数据清洗成本很高,32 张 H100 训练 DiT、16 张 H100 训练 SC-VAE,这不是普通实验室可以轻松复现的规模。其次,方法依赖高质量 PBR 资产和渲染视图,数据分布会影响材质生成的边界。再次,论文主要展示 image-to-3D 和 shape-conditioned texture generation,对多物体场景、动画资产、可控拓扑编辑等更复杂生产流程还没有展开。
还有一个值得观察的问题是:O-Voxel 虽然能即时转回 mesh 和材质,但下游 DCC 工具链是否能直接无痛使用,还取决于导出的拓扑质量、UV/材质组织和编辑友好性。论文证明了“生成”和“重建”很强,但真正进入生产管线时,资产清理、LOD、材质命名和可编辑性仍然会是下一层考验。
记忆点
如果只记一句话:TRELLIS.2 的核心不是单纯把模型做大,而是先设计一个更适合 3D 资产的原生 latent 表示,再把大模型放到这个表示上训练。
三个关键词最重要:
- O-Voxel: 用 field-free sparse voxel 同时表达几何和 PBR 材质,支持复杂拓扑、开表面、非流形和内部结构。
- SC-VAE: 用稀疏卷积 VAE 把 1024³ fully textured asset 压到约 9.6K tokens,为 4B 级 flow 模型提供可承受的 latent 空间。
- Native 3D material generation: 材质不是 2D 多视图拼贴,而是在 3D latent 中和几何对齐生成,因此 PBR 通道一致性更强。
我觉得这篇文章最值得关注的地方,是它把 3D 生成从“视觉结果好看”往“资产表示合理”推进了一步。对 image-to-3D 来说,这可能比单纯刷 CLIP 分数更重要,因为真正的 3D 内容生产最终还是要落到可导出、可渲染、可编辑、可复用的资产上。
 微信
微信 支付宝
支付宝