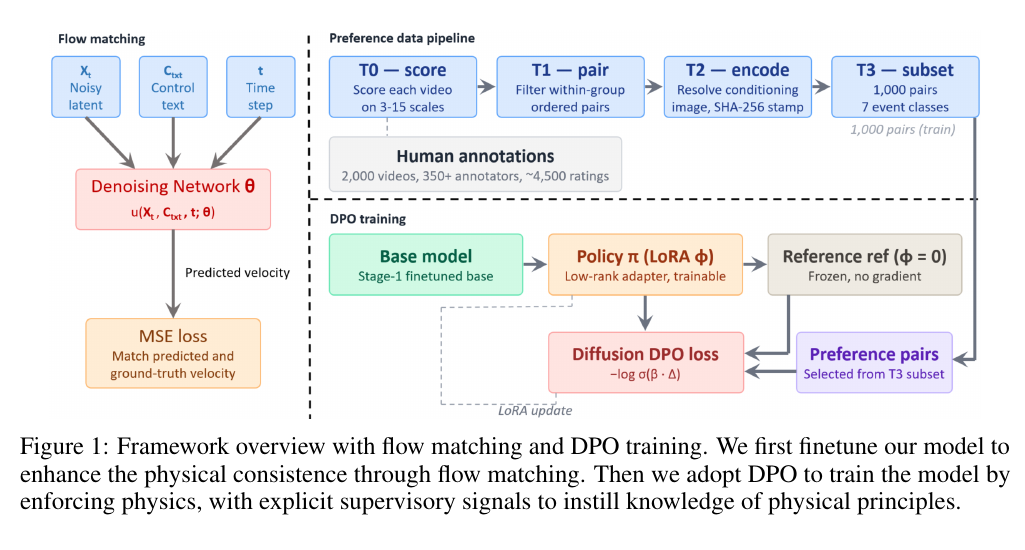
SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer
作者:Haoyi Zhu, Haozhe Liu, Yuyang Zhao, Tian Ye, Junsong Chen, Jincheng Yu, Tong He, Song Han, Enze Xie
单位:NVIDIA
会议:2026 Arxiv
链接:https://arxiv.org/abs/2605.15178
研究动机

世界模型正在从“短视频生成”走向“可交互仿真”。在 camera-controlled world modeling 里,输入第一帧、文本描述和 6-DoF 相机轨迹,模型需要生成 60 秒、720p、且严格跟随轨迹的视频。这比普通 I2V 更难,因为它既要保持场景身份,又要在长时间内维持几何一致性。
现有开源世界模型要么依赖更大的模型、更多数据和多卡推理,要么通过短视频 teacher 蒸馏来降低成本。但短视频 teacher 本身缺少分钟级场景持久性和重访记忆,难以给长时序控制提供足够监督。
论文的核心问题是:能否原生训练一个分钟级、720p、相机可控的世界模型,同时把训练数据、训练算力和推理硬件都压到更可访问的范围内?
SANA-WM 的回答是把“效率”作为第一约束来设计模型:2.6B 参数、约 213K 公公开视频片段、64 张 H100 训练约 15 天,推理时 60 秒视频可以在单卡上生成,蒸馏和 NVFP4 量化版本甚至可以在单张 RTX 5090 上完成 60 秒 720p 视频去噪。
核心方法

- 渐进式训练路线
SANA-WM 不是一开始就直接训练 60 秒视频,而是按四个阶段逐步扩展:
第一阶段把视频 tokenizer 换成 LTX2-VAE,以更高压缩率降低 720p 长视频的 token 成本;第二阶段把 SANA-Video backbone 改造成 Hybrid GDN-Softmax 架构;第三阶段扩展到 1 分钟视频并加入相机控制;第四阶段再做 chunk-causal 微调和 few-step distillation,让模型可以顺序 rollout,并把采样步数降到 4 步。
- Hybrid Linear DiT:用 GDN 扛长上下文,用 softmax 兜关键记忆
纯 softmax attention 在 60 秒视频上 KV cache 和显存都会快速膨胀;纯线性注意力虽然省,但分钟级状态会不断累积旧信息,缺少显式遗忘和选择机制,容易漂移。SANA-WM 折中采用 15 个 frame-wise Gated DeltaNet block 加 5 个 softmax attention block,softmax 层放在第 3、7、11、15、19 层,用少量精确注意力补足长程召回。
这里的直觉比较清晰:GDN 像一个低成本的时序状态机,负责大部分帧间演化;周期性 softmax attention 像锚点,帮助模型重新对齐长时程结构,避免场景记忆完全靠递推状态硬扛。
- Dual-Branch Camera Control:粗粒度轨迹 + 细粒度射线
相机控制最容易被高压缩 VAE 抹掉。SANA-WM 用两条分支解决:
latent-rate 的 UCPE 分支负责全局 6-DoF 轨迹结构,把每个 latent token 放到对应的相机局部坐标里;raw-frame 的 Plucker mixing 分支在每个 VAE temporal stride 内补回逐帧相机运动,把 8 个原始帧的 Plucker raymap 打包成 48 通道张量注入模型。前者控制“大方向”,后者补“stride 内细动作”。
- 第二阶段 Refiner:把 stage-1 的长视频再修一遍
SANA-WM 的第一阶段负责生成可控长视频,第二阶段 refiner 负责提升细节和结构稳定性。论文不是直接拿短视频 LTX-2.3 refiner 用在 60 秒序列上,而是用 LoRA 在长 SANA-WM 输出上适配一个 long-video refiner,再合并到 few-step distilled refiner 中。这样它保留了低步数推理的速度,同时更适合分钟级视频的伪影修复。

- 数据标注管线:从公开视频恢复 metric-scale pose
训练相机可控世界模型的关键不是只有视频,而是视频必须有可靠的 metric-scale 6-DoF 相机轨迹。论文以 VIPE 为基础,替换和增强深度/BA 部分:用 Pi3X 提供长序列一致的结构,用 MoGe-2 做 metric-scale anchor,并支持逐帧内参优化。对于 DL3DV 这类静态 3D 数据,还通过 3DGS 渲染 60 秒轨迹,再用 DiFix3D 修复渲染伪影。
数据集

训练数据经过过滤后一共 212,975 个 clip,来源包括 SpatialVID-HQ、DL3DV、OmniWorld、Sekai 和 MiraData。里面既有真实视频,也有 3DGS 渲染出的合成 60 秒轨迹。过滤时不仅看 aesthetic、motion、scene cut,还额外检查 FOV、焦距一致性、pose smoothness 和 scale variation。
评测集是作者构建的 60 秒 world-model benchmark:80 张由 Nano Banana Pro 生成的 1280x720 首帧图像,覆盖 game、indoor、outdoor-city、outdoor-nature 四类场景,每张图配 Simple 和 Hard 两套 revisit trajectory。

Simple 轨迹偏平滑导航,例如 S-Curve、Room、Lookaround、Side Detour;Hard 轨迹包含 loop、crossing、long return、yaw/pitch 大幅变化等压力测试,更能暴露长视频里的场景漂移和重访失败。
算力
模型规模:SANA-WM stage-1 为 2.6B 参数,refiner 来自 17B LTX-2 系列模型的 LoRA 适配。
训练算力:最终模型在约 213K metric-pose clips 上训练,1 分钟阶段使用 961-frame clips;整体 DiT/backbone 训练约 15 天,使用 64 张 H100。
推理硬件:bidirectional 和 chunk-causal 版本可以单张 H100 推理;4-step distilled + attention sink + NVFP4 量化版本可以在单张 RTX 5090 上把 60 秒 720p clip 的去噪时间压到约 34 秒。
工程细节:长视频训练使用 Context-Parallel,把时间维 latent shard 到多张 GPU;GDN scan、gate、RMSNorm、ReLU、UCPE/RoPE preparation 等使用 Triton fused kernels,论文称带来约 1.5 到 2 倍效率收益。
实验结果

主结果表里,SANA-WM 的优势主要体现在相机控制和效率上。Simple split 上,SANA-WM + refiner 的 RotErr 为 4.50,CamMC 为 1.41;Hard split 上 RotErr 为 8.34,CamMC 为 1.44,均优于表中开源 baseline。VBench Overall 与 LingBot-World 接近,但 SANA-WM 是 720p 单卡推理,而部分 baseline 需要 8 卡或只能跑 480p。
效率也很突出:SANA-WM stage-1 峰值显存 51.1GB,吞吐 24.1 videos/hour;加 refiner 后峰值显存 74.7GB,吞吐 22.0 videos/hour,仍然在 80GB H100 预算内。

定性对比说明了为什么只看 VBench Overall 不够:在 Hard trajectory 下,baseline 容易发生场景模糊、布局改变或直接崩坏,而 SANA-WM 更能保持场景身份和 viewpoint-consistent 结构。绿色边框的 SANA-WM 在 15s 到 60s 的重访过程中更稳定。

渐进训练消融里,LTX2 VAE 基本不牺牲质量,但把显存从 8.90GiB 降到 5.40GiB,latency 从 1266.6ms 降到 371.7ms;加入 Hybrid attention 后,总分从 0.8390 提升到 0.8530,显存仍只有 5.68GiB。这说明 tokenizer 压缩和 backbone 改造分别解决了“算得动”和“质量不掉”的问题。

相机条件消融也很直接:单独 Plucker 提升有限,PRoPE 和 UCPE 能明显降低 pose error,而 UCPE + Plucker 的组合在 TransErr 和 CamMC 上最好,说明粗粒度 pose encoding 与 raw-frame ray mixing 是互补的。

GDN key scaling 是一个很工程但很关键的点。作者比较了不缩放、按 (1/\sqrt{D}) 缩放和按 (1/\sqrt{DS}) 缩放,只有最后一种训练稳定;前两者很快 NaN。这说明 frame-wise GDN 把一个 frame 内的空间 token 聚合进状态时,缩放必须同时考虑 channel 和 spatial token 数。

效率路径展示了完整部署链路:60-step H100 AR 生成约 21.8min;蒸馏到 4 steps 后约 48s;attention sink 后 H100 上约 34s;RTX 5090 上加 NVFP4 后可到约 42s 总时延,其中 DiT 去噪约 34s。右侧曲线显示 recurrent/linear 方案随视频时长增长更缓,而 all-softmax 到 60s 会 OOM。
优势与不足
优势
效率目标非常明确。 论文没有单纯追求更大模型,而是从 tokenizer、attention、camera control、distillation、quantization 到数据标注全链路优化,使分钟级 720p world model 进入单卡推理范围。
相机控制做得比较细。 UCPE 分支解决全局轨迹表达,Plucker mixing 补逐帧细运动,这比只把 camera pose 当作普通条件 token 更贴近几何控制问题本身。
数据管线价值很高。 从公开视频恢复 metric-scale pose 是 world model 训练的核心瓶颈之一。论文把 Pi3X、MoGe-2、VIPE、3DGS、DiFix3D 串成可过滤的标注管线,这部分对后续工作复用价值不低。
评测更贴近长时程问题。 Simple/Hard revisit trajectory 会专门考察场景重访、长时程漂移和相机跟随,而不是只看短视频视觉质量。
不足
仍然缺少显式 3D scene memory。 论文自己也承认模型 scale-limited,并且没有显式持久 3D 记忆;因此在动态场景、罕见视角或更长 rollout 中仍可能漂移。
refiner 成本并不小。 SANA-WM stage-1 是 2.6B,但高质量结果通常会加 17B refiner。虽然 LoRA 和 few-step 让它可用,但这说明视觉质量仍很依赖第二阶段大模型修复。
benchmark 首帧来自生成图像。 这让评测场景可控且均衡,但和真实机器人/自动驾驶传感器输入仍有差距。真实世界里的 rolling shutter、曝光变化、动态物体和轨迹噪声会更复杂。
控制接口仍偏相机轨迹。 对 embodied AI 来说,相机轨迹是重要但不完整的 action space。未来如果接入机器人动作、点跟踪或可交互对象状态,难度会进一步上升。
记忆点
分钟级视频生成的瓶颈不是单点模块,而是 token 压缩、长上下文建模、相机监督、评测轨迹和部署路径的系统性组合。
Hybrid GDN-Softmax 是一个值得记住的长视频结构:大部分层用 recurrent/linear 机制保证可扩展,少量 softmax 层提供精确长程召回。
相机控制不能只靠低频 pose token。高压缩 VAE 会吞掉 stride 内的细运动,raw-frame Plucker raymap 是一个很自然的补偿方式。
从公开视频恢复 metric-scale 6-DoF pose,可能会成为开放世界模型训练的关键基础设施。
SANA-WM 的核心启发是:想让世界模型真正可用,必须同时回答“生成得像不像”“动作跟不跟”“跑不跑得动”这三个问题。
 微信
微信 支付宝
支付宝