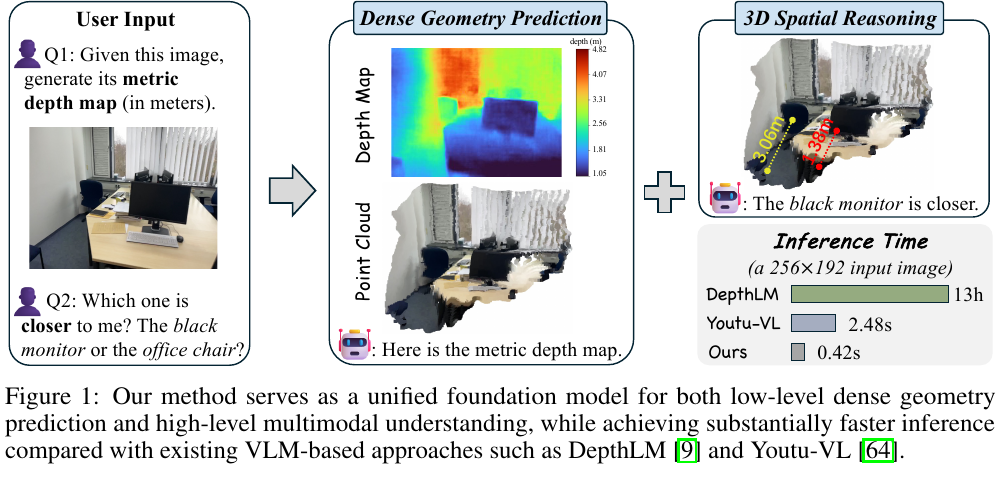
DepthAgent: Towards Better Universal Depth Estimation via Sample-wise Expert Selection
作者:Jie Zhu, Girish Chandar Ganesan, Xiaoming Liu
单位:Michigan State University, University of North Carolina at Chapel Hill
会议:2026 Arxiv
链接:https://arxiv.org/abs/2605.23281
研究动机

这篇文章的出发点很实际:现在单目 metric depth 模型已经很多,而且每个模型都很强,但真实部署时输入并不总是同一种相机。普通透视图、鱼眼图、ERP 全景图在成像几何上差别很大,一个模型即使在平均指标上很强,也不一定能稳定覆盖所有相机域。
已有“通用深度估计”通常试图训练一个统一模型,或者对多个模型做固定规则融合。但本文先指出一个更细的现象:不同 depth expert 的强弱不是随机的,而是和相机几何、场景类型、样本难度强相关。

Table 1 说明了这个现象。透视数据里,Perspective 系模型作为 best single 的比例达到 80.1%;Native ERP 数据里,ERP 系模型作为 best single 的比例达到 97.8%。但 oracle solution presence 又显示,很多样本并不是只需要一个模型,跨模型融合仍然有机会带来增益,尤其 Native ERP 上 fusion 相比 best single 的平均 $\Delta\delta_1$ 达到 0.044。
所以本文的问题不是“再训练一个更大的深度模型”,而是:
给定多个已经训练好的深度模型,能否针对每张输入图像,自动判断应该相信哪个 expert,是否需要融合,以及为这张图投入多少推理成本?
这个问题对实际系统很重要。机器人、AR、自动驾驶场景里,相机类型、视场角、畸变和场景分布都可能变化。如果只是固定调用一个模型,失败样本会集中在模型假设不匹配的地方;如果盲目融合所有模型,又会把错误预测也混进最终深度图。
核心方法
DepthAgent 的核心思想是把“深度估计”改写成一个 agentic tool-use 问题:已有深度模型不再是被端到端训练的 backbone,而是 frozen tools;VLM agent 负责看图、判断相机和场景、调用工具、比较工具结果,最后选择单个 expert 或融合多个 expert。

在正式设计 DepthAgent 之前,作者先做了 fusion analysis。Figure 2 左边显示,在多数数据集上,oracle multi-model solution 比 single-model solution 占比更高;右边显示 fusion gain 在不同数据集上并不均匀,Native ERP 的增益特别明显。这说明“融合”本身有价值,但前提是选对参与融合的 expert。

Figure 3 又进一步说明,fusion gain 主要出现在 hard samples 上。作者按 best-single $\delta_1$ 把样本分成 Q1 到 Q5,Q1 是最难样本,Q5 是最容易样本。三个相机域里,Q1 的平均增益都最大,之后逐渐下降。这一点很关键:DepthAgent 的价值不是在所有样本上平均加一点,而是在原本容易出错的输入上选择更可靠的专家组合。

整体流程如 Figure 4:
输入图像先进入 DepthAgent,agent 分析 scene type、camera intrinsic、projection type 和已有深度特征。
Agent 从 depth expert pool 中选择工具。工具池包含 perspective models 和 ERP models,论文使用的候选包括 UniDepth、Metric3D、Metric3Dv2、UniDAC、UniK3D,以及 mean / max / min / DepthFusion 等融合策略。
每次工具调用返回 depth map 和辅助 depth features,例如平均深度、深度变化等。Agent 根据这些结果决定继续调用其它 expert,还是输出最终 solution。
训练时不使用固定 oracle trajectory,而是使用 GRPO 做 reinforcement fine-tuning。因为 expert pool 可能变化,固定 SFT 轨迹会很僵硬;GRPO 更适合学习“在当前工具集合下如何选择”。
奖励函数由几部分组成:
- Format reward:约束 agent 输出格式有效。
- Tool success reward:约束工具调用能够正确执行。
- Scene awareness reward:鼓励 agent 在调用工具前识别室内/室外、perspective/pinhole 或 ERP/360 相机类型。
- Selection prior reward:如果选中的 expert family 和输入域匹配,就给一个轻量先验奖励。
- Efficiency-aware metric reward:同时考虑最终深度指标和调用模型数量,避免为了微小增益无限增加 tool calls。
效率奖励可以写成:
这个设计的直觉是:如果多调用一个 expert 能显著改善 metric,就允许它;如果 metric gain 很小,就惩罚额外计算。DepthAgent 因此不是“能调几个就调几个”,而是学习一个质量和成本之间的平衡。
数据集
训练数据覆盖三类相机/投影域:
- Indoor perspective 和 ERP variant:HM3D。
- Outdoor perspective:DDAD、A2D2。
- Panoramic:Matterport3D。
评估数据覆盖六个 benchmark:
- Perspective:KITTI、NYU-v2、IBims-1。
- Fisheye:ScanNet++。
- Panoramic / 360:Matterport3D、Pano3D-GV2。
指标使用 $\delta_i$、Absolute Relative Error 和 RMSE。ERP 模型会在 ERP-transformed ground truth 上评估,这一点比较重要,因为普通透视深度和 ERP 全景深度的误差几何并不完全相同。
算力
DepthAgent 基于 Qwen2.5-VL-3B,使用 GRPO 微调。论文明确给出的训练设置如下:
- 训练 300 steps。
- 最大交互轮数为 5。
- 训练使用 4 张 H100 GPU。
- effective batch size 为 4。
- 推理时使用 greedy decoding 保证可复现。
推理效率上,作者给了一个很有用的对比:在 H100 上,DepthAgent Fast mode 每个样本约 1.1s,全部运行 5 个 expert 约 0.76s,CoT mode 约 3.7s。也就是说,DepthAgent 不是比穷举所有 expert 更快,而是用少量额外 controller 成本换取更好的选择质量;Fast mode 则是在不展开长 CoT 的情况下保留同样的 solution selection。
实验结果

Table 2 是主结果。DepthAgent 在 perspective、fisheye、panoramic 三组数据上都超过单个 expert 和非 agentic fusion baseline。比较值得注意的是:
UniK3D 本身已经是很强的 universal-camera expert,但 DepthAgent 仍然在 perspective / fisheye / panoramic 的 A.Rel 和 RMSE 上进一步改善。
Mean / Max / Min 这类固定融合不稳定。它们有时能接近强 baseline,但会在某些域明显退化,说明“融合所有输出”不是可靠策略。
MLP router 表现不稳,尤其在 fisheye 上严重失败。这说明 sample-wise routing 不能只靠简单分类器,VLM 的图像/相机语义分析和多轮工具反馈确实贡献了信息。
DepthAgent 仍低于 upper-bound oracle,但相比 baseline 已经显著缩小差距。

Table 3 专门看 hard samples,也就是 best single model 表现最差的 10% 样本。这里 DepthAgent 的优势更明显:perspective 上 $\delta_1$ 从 UniK3D 的 0.794 提到 0.833,fisheye 从 0.799 提到 0.817,panoramic 从 0.560 提到 0.587。这个结果支持了前面 Figure 3 的判断:样本越难,静态模型越容易失配,动态选择 expert 的收益越大。

Table 4 验证 reward design。只保留部分奖励时,性能都会下降;完整的 $R{scene} + R{sel} + R{em}$ 得到最佳 $\delta_1=0.905$、A.Rel=0.097、RMSE=0.623。右侧超参数实验也说明,单纯增加 tool calls 并不等于更好,$\lambda$、$\tau$、$n{max}$ 会共同决定 agent 是偏向紧凑 solution,还是偏向更多 expert 组合。

Figure 5 给了两个更直观的观察。
左边是深度图对比。DepthAgent 不是每次都选择 top-1 expert,而是会在 top-1 / top-2 输出之间比较并生成最终 solution。在 Pano3D-GV2、IBims-1、ScanNet++ 这些不同相机域上,DepthAgent 的误差图整体更低。
右边是 solution frequency。Perspective 场景中,agent 经常选择 Metric3Dv2 + UniDepth 这类组合;Fisheye 和 Panoramic 场景则高度集中到 UniDAC + UniK3D,这和前面“ERP trained experts 更适合大视场/全景输入”的分析一致。更重要的是,policy 没有简单坍缩到平均最强的 UniK3D,而是根据相机域做了分化。
优势与不足
优势
问题定义很务实。很多论文会继续追求单模型 universal depth,但本文承认现有专家模型已经很强,真正的问题是部署时如何选择和组合它们。
先做现象分析,再设计 agent。Table 1、Figure 2、Figure 3 不是装饰性实验,而是直接推出了 camera-dependent expert preference 和 hard-sample fusion gain 两个设计依据。
Tool-use 形式很适合这个任务。Depth prediction 本身是 dense regression,VLM 不适合直接输出深度图,但适合作为 controller 分析图像和调用已有工具。
奖励设计考虑了效率。如果只追求 oracle metric,agent 可能倾向于多调用模型;$R_{em}$ 把质量增益和 tool cost 绑定起来,更接近实际部署需求。
对困难样本的提升有说服力。平均指标提升固然重要,但 hard samples 才更接近真实系统里最容易出事故的输入。
不足
系统复杂度比单模型高。DepthAgent 依赖一个 VLM controller 和多个 frozen depth experts,工程部署、显存调度和延迟管理都会更复杂。
上限受 expert pool 限制。它本质上是在现有 expert 输出空间里选择或融合,如果所有 expert 对某类输入都失败,agent 很难凭空修复几何错误。
训练 reward 仍然依赖可计算的参考指标和 oracle solution。真实无标注部署中,如何持续更新或校准这个 agent,还需要额外机制。
论文没有把代码和模型同时公开,摘要只写了 will be released upon publication;复现细节仍要等正式 release。
论文主要展示了 perspective / fisheye / panoramic 三类相机域,对动态视频深度、强反光/透明物体、夜间低照度等场景还没有展开。
记忆点
Universal depth 不一定只能靠一个 universal model,也可以是一个会选工具的 universal controller。
Depth expert 的偏好高度依赖相机几何:Perspective 模型和 ERP 模型并不是谁绝对更强,而是输入域决定了该信谁。
Fusion 的收益集中在 hard samples,因此动态选择不是锦上添花,而是在失败样本上补短板。
VLM 在这里不直接做 dense prediction,而是负责高层判断、工具调度和多轮决策,这比让 VLM 直接回归深度图更合理。
效率奖励里的核心思想很可复用:只有当 metric gain 足够大时,额外 tool call 才值得。
 微信
微信 支付宝
支付宝