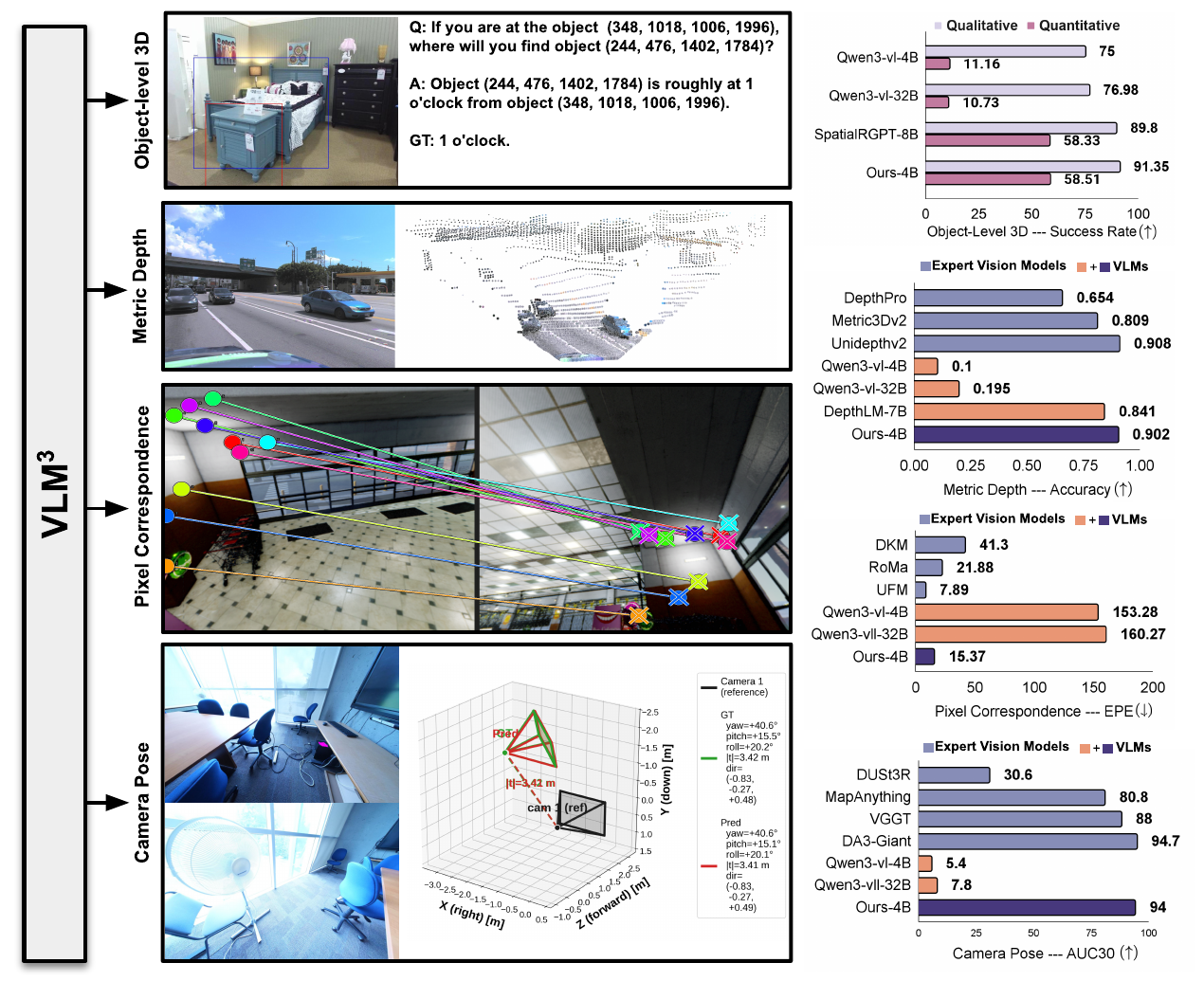
Depth Anything v2
三个关键方法:
1)将所有有标签的真实图像更换为合成图像
2)增强了教师模型的capacity
3)通过大规模伪标签真实图像对学生模型进行训练
真实标签数据的缺点:
1)标签噪声:传感器固有的缺点、透明等场景
2)忽略的细节:边缘、洞
导致错误的估计,过度平滑的估计
合成数据的局限性:
1)合成图像与真实图像之间的分布偏移
真实图像包含更多随机性,合成图像场景的布置较为有序。
2)所覆盖的场景有限,难以与真实世界的场景相匹敌
大规模无标签真实图像的作用:
1)缩小合成图像与真实场景之间的领域差异
2)增大所覆盖的场景范围
3)知识迁移


sparse的gt在评估的时候真的会影响指标的可靠性么?
能否直接训练或者使用一个强大的metric depth网络来生成metric的伪标签,从而使得学生模型能够具备metric depth预测能力?
 微信
微信 支付宝
支付宝
相关推荐
2024-12-06
DEPTH PRO: SHARP MONOCULAR METRIC DEPTH IN LESS THAN A SECOND
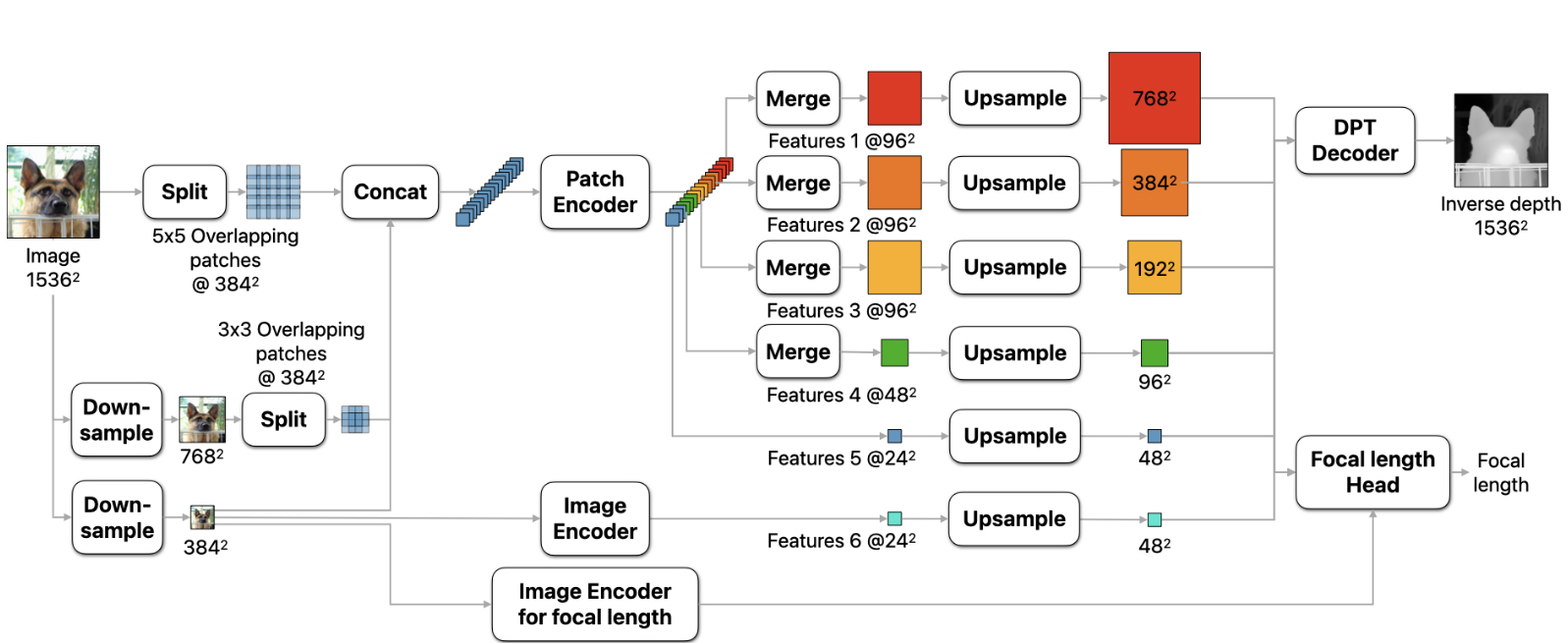
思路:在不同的尺度提取patches,对patches应用ViT encoders,将patches 的预测结果融合成一个单独的高分辨率的稠密估计。 方法 1.相对于可变分辨率的方法,将输入分辨率固定为了1536×1536,保证了足够大的感受野,防止了out-of-memory的问题。使用普通的ViT encoder,能够利用多种预训练ViT的主干网络。 2.将输入图像分成5×5个分辨率为384×384的重叠patch,下采样至786×786后分成3×3个重叠的patch。将patch链接后输入patch encoder,每一个patch得到分辨率为24×24的feature。在精细的尺度上,进一步提取中间特征。得到特征之后将特征patches融合成maps输入decoder。 Sharp 单目深度估计训练目标网络预测的输出为canonical inverse depth,然后通过视场角转换为metric depth D_m=\frac{f_{px}}{wC}对于metric datasets,使用MAE...

2024-12-06
Depth Anywhere: Enhancing 360 Monocular Depth Estimation via Perspective Distillation and Unlabeled Data Augmentation
方法 数据清洗及合理数据掩码生成为了消除不合理像素对训练的影响,使用GroundingSAM将不合理的区域滤除。对于有效像素占比低于20%的图像也进行溢出。 教师模型对无标签图像使用立方体投影,然后用Depth Anything对投影后的patch进行预测,将360度模型的预测结果投影到立方体视图,再和Depth Anything的输出计算Loss。 随机旋转处理由于Depth Anything在立方体的每一个面上进行估计,缺乏对场景的综合理解,所以会出现伪影。 在等矩形坐标系下应用旋转矩阵: ( \hat{\theta}, \hat{\phi} )=\mathcal{R} \cdot( \theta, \phi). \tag{1}从等矩形到立方体投影,立方体每一个面的视场角等于90度,每一个面都能够看作一个焦距为$w/2$的透视相机,所有的面共用世界坐标系中的中心点。因此每一个相机的外参矩阵能够用一个旋转矩阵定义,则每个面上的像素表示为: p=K \cdot R_{i}^{T} \cdot q, \tag{2} q=\left[ \begin{matrix} q_{x}...
2026-05-25
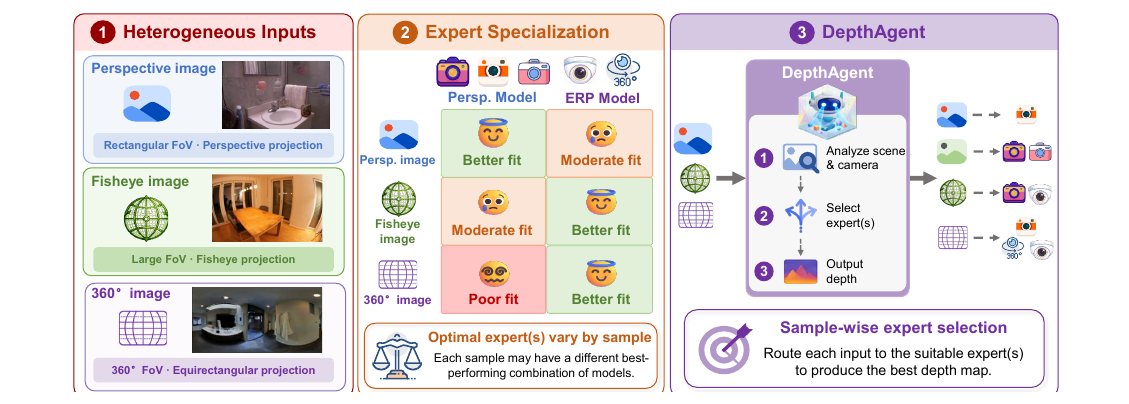
DepthAgent: Towards Better Universal Depth Estimation via Sample-wise Expert Selection
作者:Jie Zhu, Girish Chandar Ganesan, Xiaoming Liu 单位:Michigan State University, University of North Carolina at Chapel Hill 会议:2026 Arxiv 链接:https://arxiv.org/abs/2605.23281 研究动机 这篇文章的出发点很实际:现在单目 metric depth 模型已经很多,而且每个模型都很强,但真实部署时输入并不总是同一种相机。普通透视图、鱼眼图、ERP 全景图在成像几何上差别很大,一个模型即使在平均指标上很强,也不一定能稳定覆盖所有相机域。 已有“通用深度估计”通常试图训练一个统一模型,或者对多个模型做固定规则融合。但本文先指出一个更细的现象:不同 depth expert 的强弱不是随机的,而是和相机几何、场景类型、样本难度强相关。 Table 1 说明了这个现象。透视数据里,Perspective 系模型作为 best single 的比例达到 80.1%;Native ERP 数据里,ERP 系模型作为 best...
2026-05-14
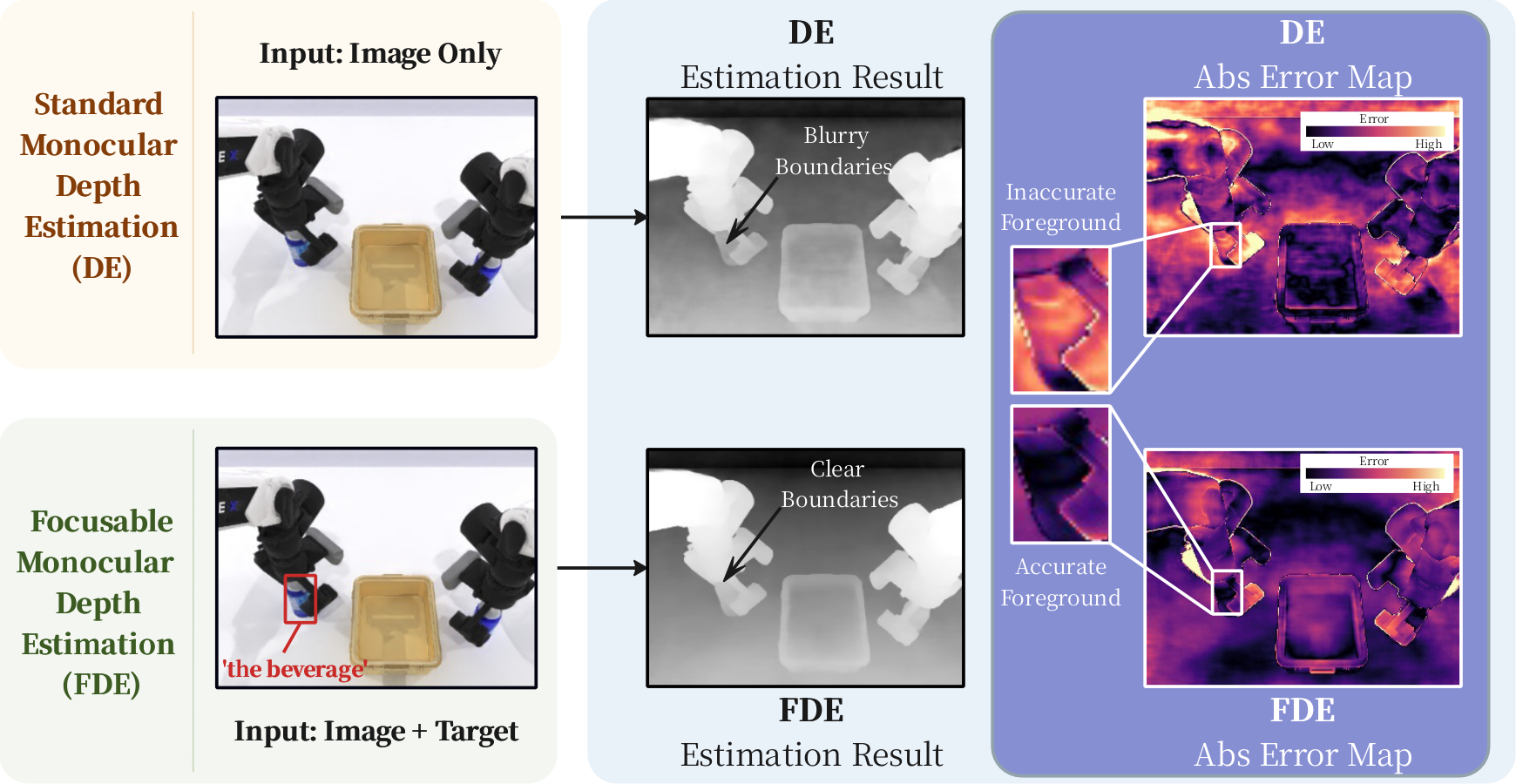
FocusDepth: Focusable Monocular Depth Estimation
作者:Yuxin Du, Tao Lin, Zile Zhong, Runting Li, Xiyao Chen, Jiting Liu, Chenglin Liu, Ying-Cong Chen, Yuqian Fu, Bo Zhao 单位:School of Artificial Intelligence, Shanghai Jiao Tong University; The Hong Kong University of Science and Technology (Guangzhou); King Abdullah University of Science and Technology 会议:2026 Arxiv 链接:https://arxiv.org/abs/2605.11756 研究动机 现有单目深度估计通常是 image-centric 的:输入一张图,输出一张整图深度,训练和评测也主要把所有有效像素的误差聚合起来。这个设定对全局场景理解很合理,但很多真实任务其实不是平均地关心每个像素。 机器人抓取时更关心目标物体和接触边界,AR...

2026-05-19
Lotus-2: Advancing Geometric Dense Prediction with Powerful Image Generative Model
作者:Jing He, Haodong Li, Mingzhi Sheng, Ying-Cong Chen 单位:HKUST(GZ), UC San Diego, HKUST 会议:2025 Arxiv 链接:https://arxiv.org/abs/2512.01030 研究动机 这篇文章讨论的是一个很尖锐的矛盾:单目几何密集预测本质上是病态问题,但现在最强的两类路线各有明显短板。 大规模判别式深度模型依赖海量监督数据,性能上限很大程度由训练集规模、真实性和标注质量决定,一旦遇到稀有场景或开放域图像,泛化就容易掉下来。 扩散/rectified-flow 这类生成模型确实在海量图文数据里学到了强 world prior,但它们原生的随机采样、多步生成和高保真图像目标,并不天然适合“同一张图稳定输出一张几何图”这种确定性任务。 如果直接把生成模型的随机生成范式搬过来,模型会出现结构方差、几何幻觉和推理开销过高的问题;但如果完全退回普通回归模型,又拿不到生成模型里蕴含的大规模几何先验。 所以 Lotus-2...

2024-12-28
Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution
ABSTRACT提出目前存在的问题神经网络方法得到的深度图远低于1兆像素的分辨率,缺少细粒度的细节,限制了其实用性 本文方法和创新点证明了一致的场景结构和高频细节之间存在一种权衡,并利用一个简单的深度融合网络来融合低分辨率和高分辨率的估计,来利用这种二元性 采用双重估计方法提高整幅图像的深度估计,采用patch选择方法,为最终的结果添加局部细节 通过合并不同分辨率的估计以及不断变化的context,可以用预训练好的模型生成高水平细节的数百万像素深度图。 INTRODUCTION问题:单目深度估计网络的输出特性随着输入图像的分辨率改变,高分辨率的图像输入网络,能够更好地捕捉高频细节,但估计的结构一致性会降低,这种二元性源于给定模型的容量和感受野大小限制 当深度线索相比于感受野间隔太大时,模型会生成结构不一致地结果,不同区域的正确分辨率发生局部改变 本文提出(创新点)①...
评论