Dens3R: A Foundation Model for 3D Geometry Prediction
作者:Xianze Fang, Jingnan Gao, Zhe Wang, Zhuo Chen, Xingyu Ren, Jiangjing Lv, Qiaomu Ren, Zhonglei Yang, Xiaokang Yang, Yichao Yan, Chengfei Lv
单位:Alibaba Group, Shanghai Jiao Tong University
会议:2025 Arxiv
链接:https://arxiv.org/abs/2507.16290
研究动机
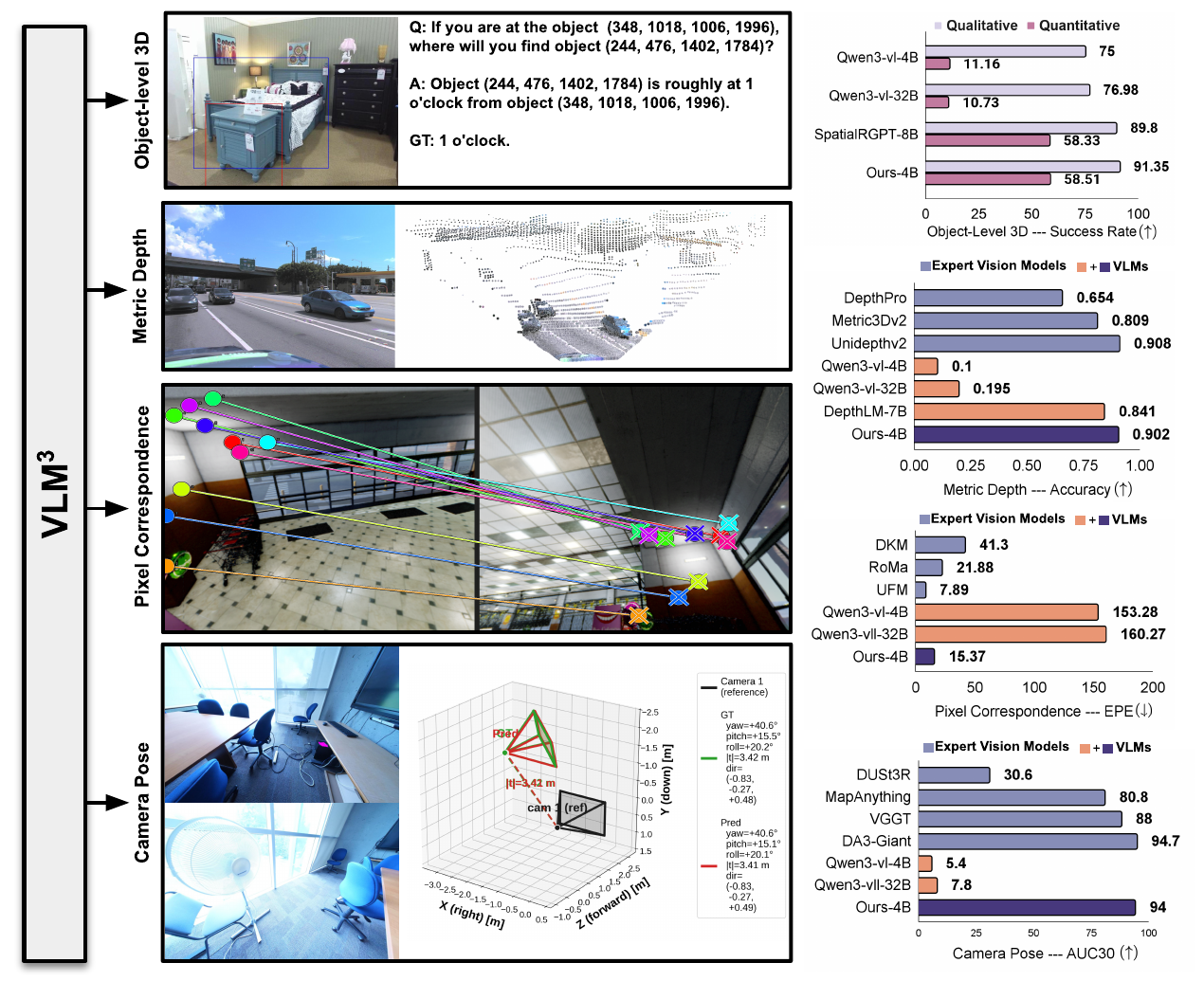
1.现有三维重建方法对各个几何属性是孤立估计的,忽略了多任务学习的相互约束(但是好像一直在强调Dust3R,估计忽略了VGGT)
2.表面法线对于捕捉物体的精细结构和局部几何特征至关重要(相较于VGGT的不同之处)
3.构建真正通用的 3D 视觉基础模型(但是看起来VGGT更加适合这个定义)
核心方法

1.模型结构
参考Dust3R才用了shared encoder,同时将decoder也设置为shared weight,捕捉多视角之间的空间一致性并降低内存消耗以适应高分辨率输入
2.位置差值RoPE
由于RoPE的三角函数表示具有周期性,对于高分辨率如果直接进行外推,会落入新的周期,从而影响空间位置的相对关系,而采用差值则能控制RoPE落入同一周期内,从而保留空间位置关系:
3.模型训练
尺度不变点图训练:第一阶段,训练ViT Encoder-Decoder、pointmap head以及matching head
局部三维回归损失:
全局三维回归损失:
点图法线损失:
像素匹配损失:
内参不变点图训练:第二阶段,微调Encoder-Decoder,pointmap head以及normal head。
之前方法使用的置信度损失通常导致模型忽略复杂的场景
- 深度/点图:单图无法确定尺度 → 必须依赖多视图约束 → 需要 confidence loss 来加权不同视图的贡献
- 法线:单图就能确定唯一解 → 不需要多视图来消歧 → 自然不需要 confidence weighting
预测法线损失:
为了进一步提高模型在高分辨率输入上的表现,首先在512的分辨率上进行训练,然后再在1024分辨率上进行微调
最后一阶段:冻结backbone,训练新heads,例如depth,normal,matching,segmentation,object detection
数据集

算力
32张A800
实验结果





优势与不足
优势
1.一次前向传播能够预测多种几何量,多任务耦合
2.位置差值的旋转位置编码,提高了对高分辨率输入的鲁棒性
3.引入了法线的监督,进一步消除了模型的多视角歧义
不足
1.无法恢复绝对的物理尺度
记忆点
1.引入表面法线监督
 微信
微信 支付宝
支付宝