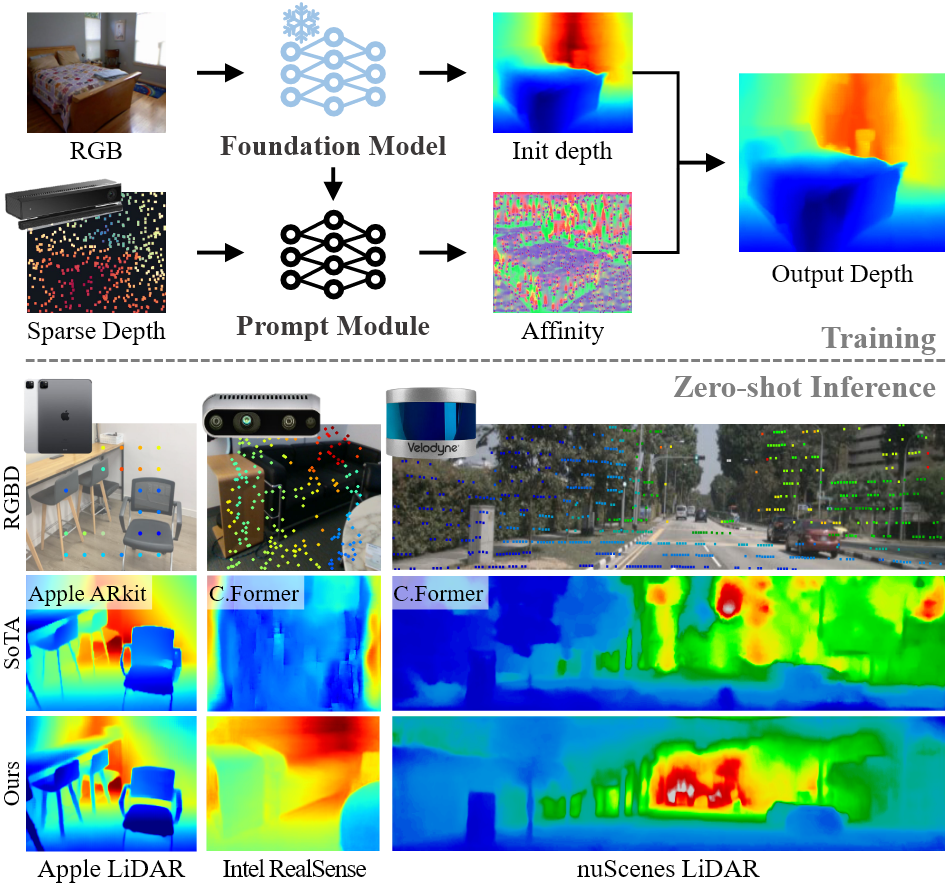
Any to Full: Prompting Depth Anything for Depth Completion in One Stage
作者:Zhiyuan Zhou, Ruofeng Liu, Taichi Liu, Weijian Zuo, Shanshan Wang, Zhiqing Hong, and Desheng Zhang
单位:Rutgers University,Michigan State University,JD Logistic,The Hong Kong University of Science and Technology (Guangzhou
会议:2026 Arxiv
链接:https://github.com/zhiyuandaily/Any2Full
研究动机
1. 现有RGBD融合方法的局限性
传统深度补全方法联合学习RGB分布和特定深度模式,导致:
- 域局限性:在光照、纹理、场景变化等视觉域偏移下性能下降
- 模式敏感性:对不同传感器产生的异构深度模式(稀疏密度、缺失区域、测距限制)鲁棒性差
2. 利用MDE先验的两阶段方法存在缺陷
近期工作尝试利用单目深度估计的域通用几何先验,但采用两阶段策略(先对齐相对深度与稀疏度量深度生成粗深度图,再细化)带来:
- 计算开销:额外的对齐和细化模块增加推理延迟
- 结构化失真:显式的相对-度量对齐往往空间不一致,引入非线性畸变和伪影,对未见过的深度模式(如Range模式)产生明显瑕疵

3. 核心问题驱动
如何绕过中间粗深度图的生成,在一个阶段内无缝集成MDE的几何先验,实现域通用且模式无关的深度补全?
相对深度预测通常展现出非线性的失真,需要和绝对真值计算空间相关的尺度因子进行对齐。直接对齐会导致伪影。

核心方法

首先将sparse depth输入嵌入为patch级别的深度特征,然后通过下面两个模块编码为尺度提示
局部增强模块:首先通过广义特征线性调制将sparse depth的特征与MDE特征进行交互:
全局传播模块:通过L层几何引导的Transformer Block更新局部尺度感知特征得到尺度提示
MDE的feature提供query和key,全局的feature作为value,确保尺度线索沿着几何结构传播
尺度提示融合:每一层的尺度提示都注入MDE的解码器中,通过分层的特征线性调制得到尺度一致的预测
效率和轻量化设计:对第一个transformer block应用masked attention,限制尺度信息只从合理的深度位置进行传播;对于较低层级的编解码层特征,直接省略其传播和提示
For example, with a ViT-L backbone providing intermediate features at layers {5, 11, 17, 23}, we enrich local features using layer 10, perform three propagation steps guided by layers {10, 16, 22}, and execute prompt fusion at levels corresponding to layers {11, 17, 23}.
数据集
训练时采用两种深度采样策略:
(1)随机采样
(2)孔洞采样
Train:Hypersim,VKITTI2,TartanAir
Eval:NYU Depth v2,iBims-1,KITTI DC,DIODE,ETH3D,VOID,Logistic-Black
算力
四NPU
实验结果






优势与不足
优势
1.单阶段尺度提示,更轻量化的同时提高了模型的预测精度
2.实现了鲁棒的泛化性以及模式无关性
不足
1.依赖于MDE基础模型,在特定具有挑战性的场景下可能会失效
2.可能对Sparse Depth的精度较为敏感
记忆点
1.相对深度预测的尺度不一致是非线性,空间变化的,这篇工作的本质是通过Scale-aware Prompt Encoder去消除这种非线性的不一致关系
 微信
微信 支付宝
支付宝