PhyWorld: Physics-Faithful World Model for Video Generation
作者:Pu Zhao, Juyi Lin, Timothy Rupprecht, Arash Akbari, Chence Yang, Rahul Chowdhury, Elaheh Motamedi, Arman Akbari, Yumei He, Chen Wang, Geng Yuan, Weiwei Chen, Yanzhi Wang
单位:Northeastern University, University of Georgia, Tulane University, EmbodyX
会议:2026 Arxiv
链接:https://arxiv.org/abs/2605.19242
研究动机
这篇论文把视频生成模型当作 Physical AI 的训练环境,而不是只把它当成“看起来逼真”的生成器。对于世界模型来说,真正关键的不只是下一帧清不清晰,而是给定当前观测后,后续视频是否还能保持同一个物体、同一个背景、同一种运动状态,并继续沿着符合物理规律的方向演化。
作者认为现有视频世界模型有两个核心短板。第一类问题是时序物理状态不稳定,例如背景颜色漂移、物体速度忽快忽慢、前后帧身份不一致;第二类问题是模型内部没有显式的“物理约束入口”,训练时主要靠海量视频统计规律,缺少直接教模型什么叫碰撞、流体连续、反射或重力合理性的监督。
因而论文的核心问题不是“怎么再把视频质量做高一点”,而是:能否在一个开源大视频模型上,用后训练的方式同时补两件事,一件是 continuation 的稳定性,另一件是 physics faithfulness 的可监督对齐?
PhyWorld 的回答是把问题拆成两阶段:先用 flow matching 把视频延续这件事训练稳,再用基于物理偏好的 DPO 让模型朝着“更符合物理规律”的方向移动。
核心方法

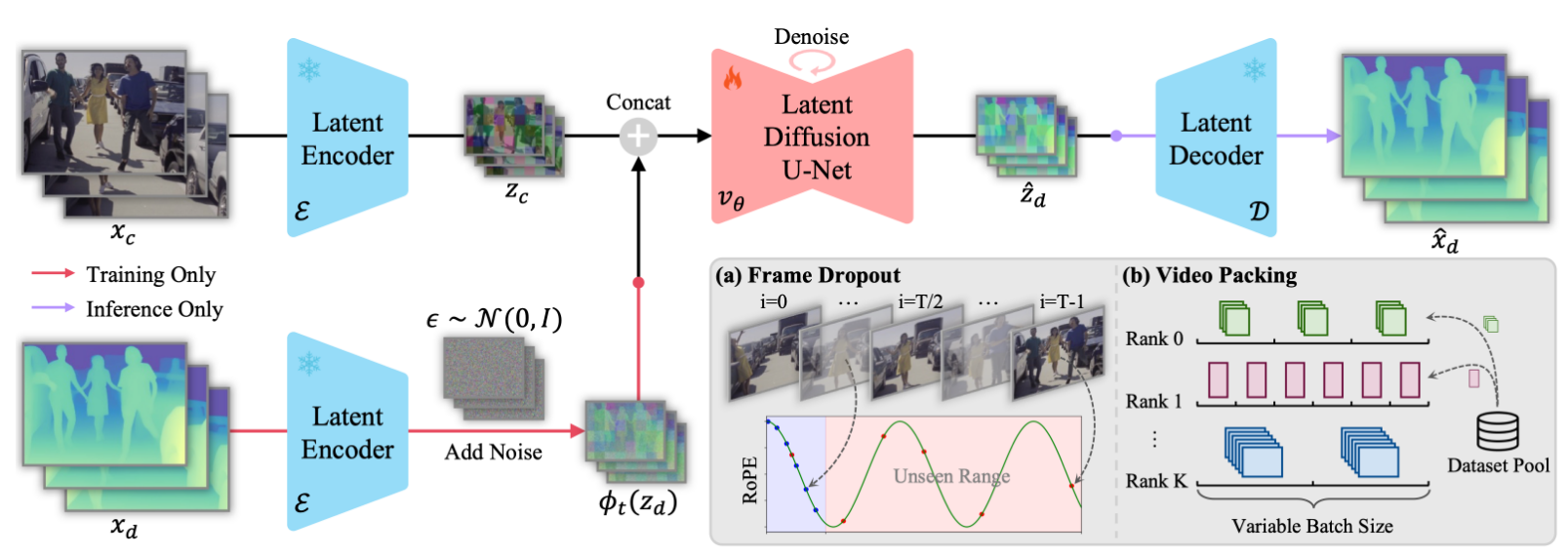
PhyWorld 建立在 Wan2.2-I2V-A14B 上,但不是直接拿原始 image-to-video 模型来评测,而是先把它改造成既能做 image-to-video,也能做 video-to-video continuation 的底座。整套方法可以分成两个连续阶段。
- 阶段一:用 flow matching 把 video continuation 训练稳。
作者把一段条件视频送入 Wan-VAE 编码成 latent,并额外构造一个二值 mask,显式区分哪些帧来自条件输入、哪些帧需要模型续写。这样做的重点不是“多喂一点历史帧”,而是让模型知道 continuation 的边界在哪里,避免把保留帧和生成帧混成一团。除此之外,作者还用条件视频最后一帧的 CLIP 特征作为全局语义上下文,经由三层 MLP 投影后,通过 decoupled cross-attention 注入 DiT,使模型在续写时既保留局部时序信息,又维持场景级语义一致性。
- 阶段一的数据过滤也在为“物理稳定”服务。
作者并没有直接把 OpenVid-1M 全量拿来微调,而是做了两层筛选。第一层是时间一致性筛选,用相邻帧 CLIP 特征的余弦相似度排掉几乎静止的片段和严重闪烁/切镜的片段;第二层是运动过滤,用 UniMatch 估计光流,把运动过猛或异常不稳定的片段去掉。这个设计非常工程化,但逻辑是对的:如果阶段一的目标是“学会稳定地续写物理状态”,那训练数据本身就不能充满高速混乱运动和频繁断裂的镜头。
- 阶段二:把“是否符合物理规律”转成偏好学习问题。
作者不试图显式写一个碰撞方程或流体方程塞进生成器,而是把物理违反看作 preference learning。具体做法是给同一 prompt 和同一条件图像下的两个候选视频打分,形成 winner/loser 配对,再用 DPO 去训练一个 LoRA policy 分支,相对于冻结的 reference 分支更偏好物理更合理的输出。这里的关键点有两个:
第一,训练只更新 LoRA,底座保持冻结,意味着作者想尽量保留原模型的视频先验,只在偏好方向上做校正;第二,DPO 只在高噪声时间窗 t ∈ [901, 999] 上训练,作者的解释是 judge 的区分信号主要集中在这里,这样可以减少 reward hacking 式的投机修正。
- 他们没有只做 DPO,还自己造了一套物理对齐基准。
论文的一个重要贡献是自建 TI2V physics benchmark。它包含 250 个 prompt,每个 prompt 对应一张条件首帧,并按物理规律组织成多个维度:一般质量维度包括 SA / PTV / persistence,物理维度包括 collision/rebound、destruction/deformation、fluids、shadow/reflection、chain、rolling/sliding 和 throwing/ballistic。然后作者用约 350 位标注者、约 4500 条清洗后的标注,微调了一个开源的 Qwen3.5-9B 视频语言 judge,用它既做评测,也为 DPO 提供偏好信号。
- 偏好对的构造不是随手拼的,而是一个四阶段管线。

Table 1 对应 T0→T1→T2→T3 管线:先给单个视频打总分,再在同组内形成有序 pair,然后解析条件图像并落盘,最后才进入 RL 采样池。这里最值得记住的是,作者不是对所有 pair 一视同仁,而是在形成最终 1000 个训练 pair 之前做了多轮过滤,把“能稳定提供物理偏好差异”的样本尽量留下。

Table 2 展示了最终 1000 对 DPO 训练样本的事件配额。碰撞/反弹类最多,为 513 对;流体类 168 对;破坏/形变类 93 对;阴影/反射类 68 对;rolling/sliding 和 throwing/ballistic 更少。这意味着 PhyWorld 学到的“物理常识”不是均匀覆盖所有物理现象,而是更偏向视频生成里最常见、最容易被 judge 识别的那几类规律。
数据集
阶段一训练数据:
OpenVid-1M。作者从中筛出时间一致、运动平滑的子集,用来把Wan2.2-I2V-A14B微调成更稳定的 continuation 模型。阶段二训练与评测数据: 作者自建的
TI2V physics benchmark。它由 250 个 prompt 与条件首帧组成,每条样本都会按一般质量和物理规律维度分别打分。DPO 训练使用的偏好对并不是 benchmark 全量,而是由T0→T1→T2→T3管线逐步过滤出来的子集。偏好对规模:
T1 retained有 3,324 对、250 个 group、253 个 prompt;T3 RL pool还剩 2,202 对、208 个 group;最终 round-4 的训练集是 1,000 对。评测集: 视频质量评测使用
VBench的 500 个随机 prompt,分辨率为480p;物理一致性评测使用作者的 250-prompt TI2V 基准,并用发布出来的开源 judge 模型做逐维度打分。
算力
论文明确披露了 第二阶段 DPO 的训练配置:
world_size = 4,micro_batch = 1,梯度累积 2,对应有效 batch size 为 8。1000 对样本每个 epoch 对应 125 个 optimizer step,共训练 2 个 epoch,也就是 250 个 optimizer step。DPO 阶段优化器为
AdamW,学习率1×10^-5,β = 100,并最终选择最后一个 epoch 的 checkpoint。论文明确说明这一阶段使用了 16 张 Nvidia H100。第一阶段 flow matching 微调 的总 GPU 数没有在正文里明确给出,但给了关键输入规格:video-to-video 管线中,输入视频为 17 帧,ground truth 视频为 49 帧;在这一阶段,作者从
Wan2.2-I2V-A14B出发,顺序微调其两个面向不同 timestep 的 DiT,学习率为1e-6。
实验结果

Table 3 是标准视频质量指标。PhyWorld 在 VBench 上的平均分达到 0.769,高于 Wan2.2-I2V-A14B 的 0.756,也高于 Cosmos-14B、LTX-2.3-22B、OmniWeaving 等开源 baseline。更重要的是,它的提升不是只体现在一个边角指标上,而是 subject consistency、background consistency、motion smoothness、imaging quality 几项都比底座更高。这和第一阶段的设计目标是吻合的,说明 flow matching 微调确实先把“继续生成时不要漂”这件事做好了。

Table 4 是这篇论文真正的主菜。PhyWorld 的 Overall 物理一致性得分为 3.09,高于冻结底座 Wan2.2-I2V-A14B 的 2.99。论文特别强调,提升主要集中在 DPO 真正优化到的方向上:PTV 提升 +0.10,Persistence 提升 +0.15,Optical 物理域提升 +0.21。这很关键,因为它说明第二阶段不是在瞎涨分,而是在物理 judge 真正关注的轴上移动。

Figure 2 给出几组视觉示例。PhyWorld 相比 baseline 更少出现背景颜色漂移、主体位置关系突变和不合理外观变化。严格说,这些例子还不是“牛顿方程级”的物理推演,而更像是“视频延续时别突然不讲理”。但对于把视频模型作为 world simulator 的第一步,这已经是很实际的改进,因为很多下游策略学习首先就会被这种跨帧身份漂移绊住。
优势与不足
优势
问题拆分很清楚。 先修 continuation 稳定性,再修 physics alignment,比一上来就端到端追求“懂物理的视频生成器”更现实,也更容易定位收益来自哪里。
评测和训练信号是闭环的。 作者没有只说“我们感觉更符合物理”,而是构建了有 taxonomy、有人工标注、还有开源 judge 的评测管线,并进一步把这套信号用于 DPO 训练,这让论文的叙事比较完整。
改进方向和训练目标一致。 从
PTV、Persistence、Optical的提升可以看出,模型不是仅靠审美或清晰度混到更高总分,而是在物理相关维度上被显式推了一步。工程改造成本相对可控。 整个方法仍然是基于
Wan2.2-I2V-A14B + LoRA + DPO的后训练路线,没有引入沉重的显式 3D 场景状态或外部物理引擎,因此对开源视频模型社区比较容易复现。
不足
它仍然是“对生成视频打物理补丁”,不是显式状态世界模型。 PhyWorld 并没有维护可解释的 3D 状态、接触关系或动作条件,只是通过偏好学习把输出往更像“物理正确”的方向拉。因此它更像 physics-aware video generator,而不是能直接支撑规划和闭环交互的可执行模拟器。
物理知识覆盖面受偏好数据分布限制。 最终 DPO 只用了 1000 对样本,而且事件分布明显不均衡,碰撞/反弹占比很高,chain、throwing 等类很少。这意味着模型更可能学到“常见违规模式的修补策略”,而不是广义物理规律。
论文自己也承认它继承了底座偏差。 结论部分明确写到,PhyWorld 是从
Wan2.2-I2V-A14B后训练得到的,因此会继承原模型的数据偏见和失败模式。换句话说,它不是重建世界模型,只是在原有生成先验上做 physics alignment。距离真正的 Physical AI policy transfer 还有一层。 作者把“训练出的世界模型策略能否迁移到真实 agent”留给未来工作。也就是说,这篇论文证明了“物理更像了”,但还没有证明这种改进会直接转化成更好的控制、规划或机器人学习收益。
记忆点
把视频世界模型的问题拆成“先学会稳定续写,再学会服从物理偏好”是这篇论文最值得记住的设计。
TI2V physics benchmark + Qwen3.5-9B judge + DPO组成了一条完整的 physics alignment 闭环,评测信号和训练信号来自同一套 taxonomy。PhyWorld 的提升主要不在“更好看”,而在
PTV、Persistence和Optical physics这些更接近物理一致性的维度。这篇论文提醒我们:很多所谓 world model 的第一性问题,未必是生成分辨率或时长,而是有没有明确机制去约束“后续视频仍然讲同一套物理故事”。
 微信
微信 支付宝
支付宝