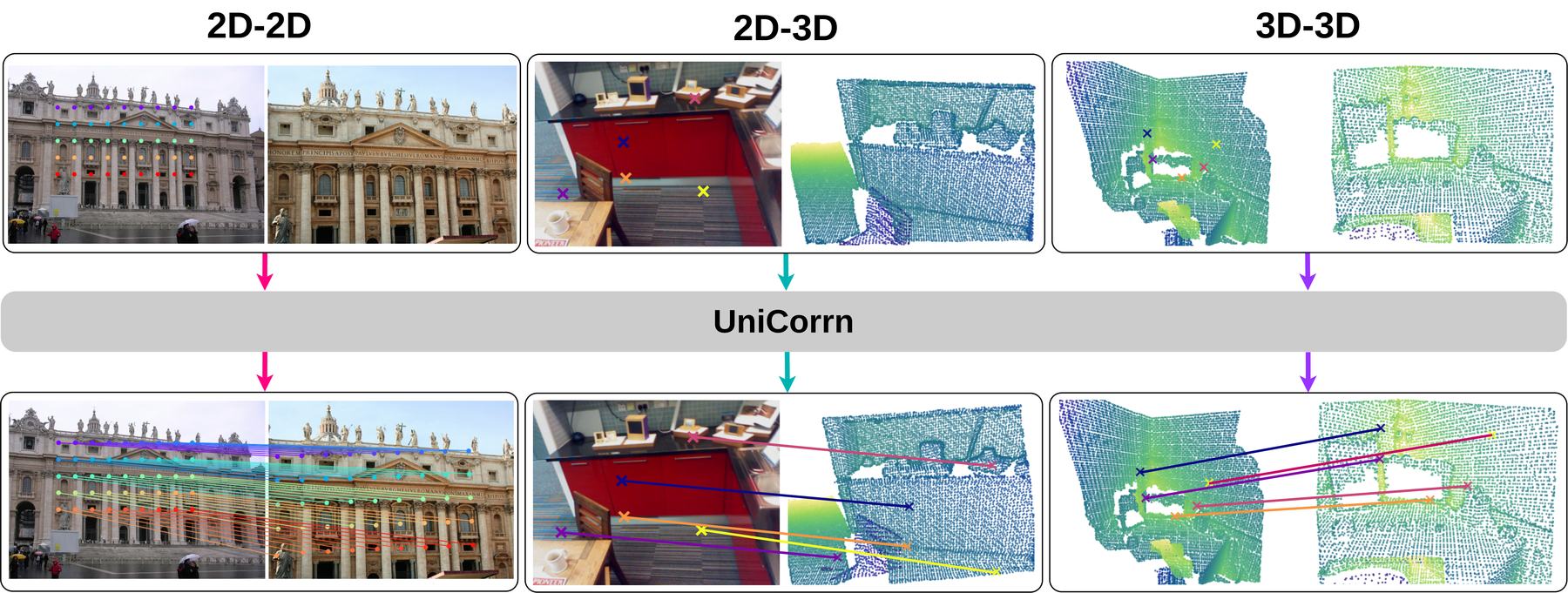
Tango3D: Towards Alignment for Global and Local 2D-3D Correspondence
作者:Zebin He, Mingxin Yang, Shuhui Yang, Hanxiao Sun, Xintong Han, Chunchao Guo, Wenhan Luo
单位:HKUST, Tencent Hunyuan
会议:2026 Arxiv
链接:https://arxiv.org/abs/2605.19727
研究动机
现有 3D foundation model 很多都沿着同一条路线走:把整段点云或 shape 压成一个全局向量,再去对齐 CLIP 这类 2D 语义空间。这样做对 zero-shot 分类、shape retrieval 很有效,但它天生有一个缺口:
- 全局向量只保留“这是什么”,很难回答“图中这个像素在 3D 形体的哪一个局部”。
- 纯语义对齐能够建立 category-level matching,却无法自然支持 pixel-to-point 这种细粒度几何 grounding。
- 如果只追 global retrieval,3D token 本身就不需要保留局部拓扑和几何结构,这会让很多 dense downstream task 无法直接复用。
这篇工作想把两个通常被分开的目标揉到一起:
能不能在同一个共享 token space 中,同时做 object-level 的 2D-3D dense correspondence 和 instance-level 的 image-to-shape / shape-to-shape retrieval?

Figure 1 很直观地说明了它的 ambition。Tango3D 不只想做单一方向的 2D-to-3D 检索,而是希望一个共享表示同时支持:
2D pixel -> 3D point3D point -> 2D pixel2D part -> 3D partimage -> 3D shape retrieval3D shape -> 3D shape retrieval
这比传统 CLIP-style global alignment 更激进,因为它要求 3D 表示既有局部几何分辨率,又能被压缩成全局语义描述子。
核心方法
Tango3D 的整体结构就是一个“共享 token space + 双分支训练目标”。

1. 2D 和 3D 先各自编码,再映射到共享空间
2D 侧使用 冻结的 VGGT backbone 作为 geometry-aware visual encoder。和直接拿 CLIP 的 class token 不同,作者明确需要一个保留空间结构的 2D 基座,因此取的是 VGGT 的 patch-level feature 与 DPT refinement feature。
论文的做法是:
- 每个输入视图先经过 frozen VGGT,一次前向得到 4 个中间特征图和 1 个 fused DPT feature。
- 这些 feature 被 resize 到当前 stage 的 patch grid 后拼接成每个 patch 一个 3072 维向量。
- fused DPT feature 还会全局平均成一个 256 维的 per-view context,用于后续 global branch 的语义增强。
3D 侧则不是把整形状压成一个向量,而是使用 Hunyuan3D 2.1 VAE encoder,把 point cloud 编码成 1024 个 latent tokens 以及对应的 3D spatial centers。
两边最终都通过残差 MLP 投到同一个 1024 维共享空间:
这里最关键的一点是:作者没有让 2D token 和 3D token 只在 global pooling 之后才见面,而是在 token 级别先对齐。这样共享空间一开始就被约束成“既有几何可定位性,又有跨模态语义一致性”。
2. Local branch 负责真正的 pixel-to-point 几何对齐
论文里最重要的 supervision 在 local branch。对每个 2D query patch,作者根据 position map 恢复它的 3D 几何位置,然后用 nearest-neighbor assignment 在 3D token centers 中找到正样本 token。
由于 patch center 和离散 3D token center 不可能完全重合,Tango3D 用一个 Gaussian confidence weight 给每个 query 赋权,并在负样本构造时剔除空间上太近的 token,避免把几何邻域误当 hard negative。
局部匹配损失采用双向 InfoNCE:
这里的关键不是公式本身,而是双向性。如果只做 2D 到 3D 的单向匹配,多个 2D query 很容易塌到同一个 3D token 上;反向聚合可以显式约束 many-to-one collapse。

Figure 3 展示了 local branch 学到的共享 descriptor space 很有意思的性质:
- 同一个物体内部可以做标准的
2D -> 3D局部定位。 - 不同实例之间也能做
cross-case 2D -> 3D,说明它学到的是“同类局部语义部件”而不只是记忆某个 shape。 3D -> 2D和3D -> 3D也能工作,说明这个局部空间本质上是跨模态统一的 part-level correspondence space。
3. Global branch 在不破坏几何 grounding 的前提下做语义汇聚
如果直接把 CLIP/DINO 语义 token 混进 patch-level local descriptor,语义 shortcut 很容易绕过几何对齐。所以作者把 global branch 放在 local branch 之后:
- 先在每个 view 内对共享 2D tokens 做 pooling,得到 preliminary view tokens。
- 再把 VGGT 的 DPT context 和 DINO class token 以 gated 方式注入这些 pooled view tokens。
- 最后跨视角再做一次 pooling,得到 2D global descriptor。
作者显式强调一个设计原则:DINO 的语义信号只能做 semantic enrichment,不能绕开已经学到的 local geometry evidence。这也是为什么 DINO 注入发生在 pooling 之后,而不是 patch level。
3D 侧更直接:共享 3D tokens 先过一层 self-attention 和 FFN,让空间上远距离的部件交换上下文,再 pool 成 3D global descriptor。
这个 global branch 对应三类 loss:
- 跨模态对比的
L_global - 缺失视角鲁棒性的
subset-consistency loss - 从 2D teacher 传递关系结构的
semantic distillation loss
这里第三点很值得记。作者不是强行让 3D token 去回归 2D teacher feature,而是蒸馏 teacher 的 similarity matrix,让共享空间学到“哪些对象在语义上彼此邻近”的结构。
4. Progressive training 把 dense 和 global 目标分三步耦合
如果一开始同时做 dense correspondence 和 global retrieval,两种目标很容易相互干扰。Tango3D 的解法很工程化,但很有效:
- Stage I:关闭 global branch,只训练 local branch 和共享编码器,先把 pixel-to-point 对齐打牢。
- Stage II:打开 global branch,引入
L_global + L_sub + L_sd,同时降低 local 模块学习率,尽量保住 Stage I 学到的 correspondence structure。 - Stage III:把 2D 输入从
518×518提到1022×1022,并增强 hard-negative mining,进一步 sharpen 整个表示空间。

Table 3 给出的信号很清楚。随着 Stage I -> II -> III:
LocAcc@1从76.47升到76.99再到77.37- retrieval 在 Stage II 才真正启用,但 Stage III 还能继续把
R@1从36.79提高到39.12 - 说明 dense 与 global 不是天然冲突,只要训练顺序安排得对,两者是可以互相增益的
数据集
训练和评测都围绕 object-level 2D-3D 对齐构建。
训练数据
- 约
650,000个 3D objects,主要来自Objaverse / Objaverse-XL,其中包含一部分 Objaverse-LVIS 数据。 - 3D 侧对每个 object 抽取
20,480个带坐标与法向的 surface points。 - 2D 侧为每个 object 渲染
60个视图,其中6个正交视图、54个随机视图,并为每个视图提供 RGBA position map。 - 训练时不固定用满所有视图,而是从
S ∈ {1, 2, 3, 4}中采样 view count。
评测 benchmark
- 为避免训练集包含 Objaverse-LVIS 造成泄漏,作者没有直接复用标准 LVIS split,而是自建 benchmark。
- 测试集包含
3,055个 textured objects,覆盖40个ModelNet40类别。 - 每个 test object 提供
10个 rendered views 和配套的 surface point cloud。
这说明论文评测的是object-centric 2D-3D alignment,不是室内/室外场景级配准。它更接近“单物体部件定位 + 形状检索”的 3D foundation setting。
算力
论文没有明确给出 GPU 数量和总训练时长,所以不能像 DVD、VGGT-Ω 那样精确报出“多少张 H100、几天训练完”。能确认的是:
- 训练分为
5 + 3 + 3个 epoch,对应 Stage I / II / III。 - 2D 输入分辨率在前两阶段是
518×518,最后阶段提升到1022×1022。 - appendix 给了 per-GPU batch size:Stage I 为
30,Stage II 为25,Stage III 为7。 - 优化器使用
AdamW,并在附录中说明用了DeepSpeed ZeRO-2和bf16。 - local branch 的 hard negatives 从 Stage II 的
top-k = 64增强到 Stage III 的96。
所以这篇论文的算力信息更像“训练配置表”,而不是完整的 compute disclosure。GPU 数量、总 tokens、总 FLOPs、wall-clock time 都没有明确写出来。
实验结果
1. Pixel-to-point correspondence 真的成立

Table 1 评测的是 local correspondence,用 LocAcc@k 衡量 query pixel 的真值 3D 坐标是否落在 top-k retrieved 3D token centers 附近。
结果有两个值得记住的点:
- 单视图随机输入已经很强:
S=1, random时LocAcc@1 = 77.43。 - 多视图更稳定但不一定提升 top-1:
S=4, random时LocAcc@10 = 87.38是最高,但LocAcc@1 = 77.37反而略低于单视图随机。
这说明 Tango3D 的 local descriptor 并不是简单依赖“更多视角必然更好”,而是已经能在 object-level 2D-3D grounding 上稳定工作。
2. 学到的不只是同实例匹配,还有跨实例部件语义
Figure 3 已经展示了这一点,但 Figure 4 更直观。

Figure 4 里,作者先用 SAM 在 2D 图像上圈一块局部区域,再把这块区域映射回 3D point cloud。这个实验没有额外的 part supervision,本质上是在验证:
- local descriptor space 是否足够细,能支持 part-level transfer
- 这种 transfer 是否能跨形状、跨实例泛化
从可视化看,红色高亮区域确实落在语义一致的部件上,例如屋顶尖端、帽檐、锤柄等。这是这篇文章比纯 retrieval 论文更有意思的地方,因为它证明 3D token 内部确实长出了 part-level structure。
3. Global retrieval 竞争力不错,但不是单视图绝对第一

Table 2 是 image-to-shape retrieval。
单视图下:
Tango3D (S=1)的R@1 = 35.04,低于OpenShape的36.44MRR = 47.17,也低于OpenShape的48.19
多视图下:
S=4, ortho时R@1 = 37.60S=4, random时R@1 = 39.12,MRR = 50.69
也就是说,Tango3D 不是单视图 global retrieval 的最强方法,但一旦有多视角信息,它就能把 local geometry grounding 的优势转化成更强的全局检索性能。
4. 定性 retrieval 证明它学到的是结构相似,而不只是大类标签

Figure 5 做的是 image -> shape retrieval。最有意思的地方不是 top-1 是否同类,而是 top-ranked shapes 往往连局部构型都和 query image 很接近,比如棒球缝线、哑铃盘片厚度、手电筒头部结构。

Figure 6 则显示即使完全不输入 2D 图像,只做 3D -> 3D retrieval,检索结果也能保持比较细的几何和拓扑相似性。这说明通过 joint training,3D encoder 学到的已经不是普通的 semantic class vector,而是带有结构偏好的 token space。
优势与不足
优势
- 问题定义很准。它抓住了现有 3D foundation model 的核心短板: 只有 global semantics,没有 dense grounding,于是直接把 pixel-to-point correspondence 作为一等公民来建模。
- 共享 token space 的设计有说服力。2D patch 和 3D token 在同一空间先局部对齐,再全局聚合,这比“先压成向量再对齐”更适合 dense task。
- progressive training 很务实。先练 local,再接 global,最后提分辨率和 hard negatives,训练逻辑清晰,也确实从 Table 3 里看到阶段性收益。
- semantic distillation 的位置放得对。DINO 语义只在 global pooling 之后注入,避免了 semantic shortcut 直接破坏 local geometric grounding。
- qualitative evidence 很扎实。Figure 3、4、5、6 共同证明它既能做 part-level transfer,也能做 instance-level retrieval,不只是报了几个数字。
不足
- local 对齐分辨率仍然受限。作者自己在 conclusion 里承认,VGGT 的 patch 是
14×14,3D VAE 只有1024个离散 token,sub-patch / sub-token 细节天然会丢失,point-level localization 有硬上限。 - single-view retrieval 还不如 OpenShape。这说明 global branch 的语义判别力仍然不如成熟的 CLIP-style global alignment,尤其作者依赖的是 DINO class token 而不是更强的语言对齐语义。
- 评测主要是 object-level,不是 scene-level。论文展示的是单物体 2D-3D 对齐和 retrieval,离 DUSt3R / MASt3R / VGGT 那种 scene reconstruction 还有明显任务边界。
- 3D 侧依赖 Hunyuan3D VAE encoder。这个 encoder 本身带来的 shape prior 是有效的,但也意味着方法对 object-centric 3D generative representation 有明显依赖。
- 算力披露不完整。附录给了 batch size、epoch、learning rate 和 ZeRO-2/bf16,但没有给 GPU 数量和总训练时长,复现成本不好直接估。
记忆点
- 不要把 3D foundation model 只做成 global vector,对 dense downstream task 来说,token-level 对齐才是关键。
- 语义增强不能太早注入。先用 local branch 建立几何 grounding,再用 DINO class token 做 gated global enrichment,是这篇论文里最值得借鉴的训练顺序。
- 同一个 shared token space 既可以支持
pixel -> point,也可以支持image -> shape和shape -> shape,说明“局部几何”和“全局语义”并不一定冲突。
 微信
微信 支付宝
支付宝