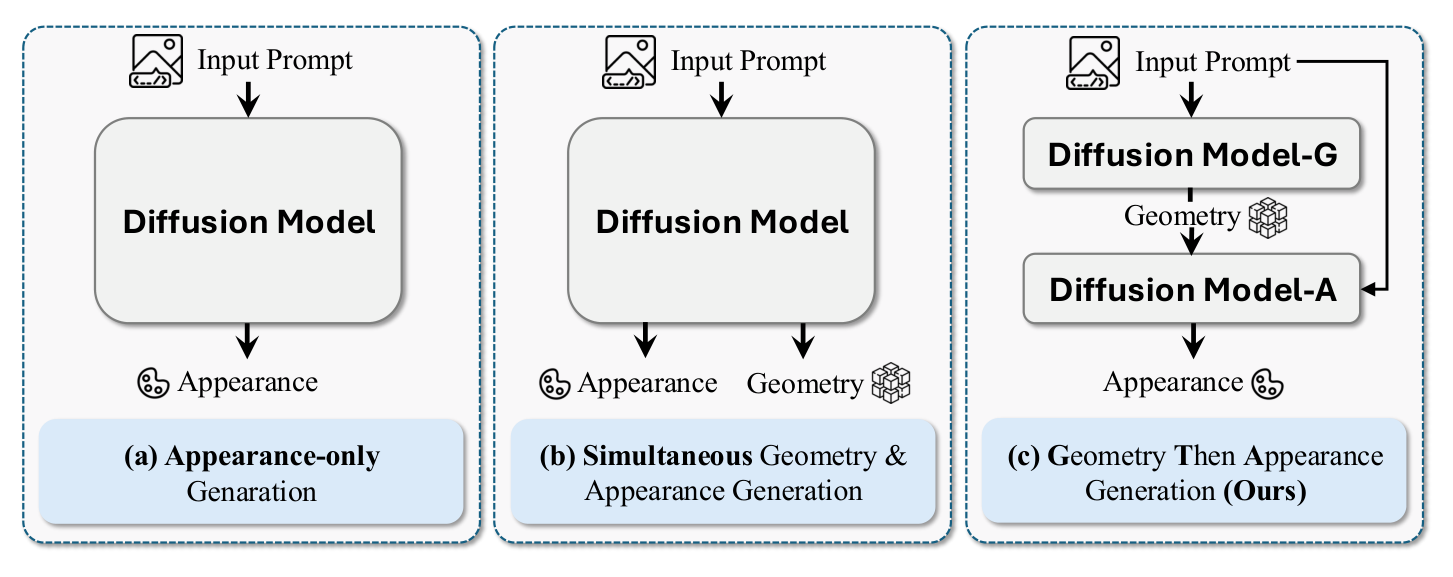
Depth Anywhere: Enhancing 360 Monocular Depth Estimation via Perspective Distillation and Unlabeled Data Augmentation
方法 数据清洗及合理数据掩码生成为了消除不合理像素对训练的影响,使用GroundingSAM将不合理的区域滤除。对于有效像素占比低于20%的图像也进行溢出。 教师模型对无标签图像使用立方体投影,然后用Depth Anything对投影后的patch进行预测,将360度模型的预测结果投影到立方体视图,再和Depth Anything的输出计算Loss。 随机旋转处理由于Depth Anything在立方体的每一个面上进行估计,缺乏对场景的综合理解,所以会出现伪影。 在等矩形坐标系下应用旋转矩阵: ( \hat{\theta}, \hat{\phi} )=\mathcal{R} \cdot( \theta, \phi). \tag{1}从等矩形到立方体投影,立方体每一个面的视场角等于90度,每一个面都能够看作一个焦距为$w/2$的透视相机,所有的面共用世界坐标系中的中心点。因此每一个相机的外参矩阵能够用一个旋转矩阵定义,则每个面上的像素表示为: p=K \cdot R_{i}^{T} \cdot q, \tag{2} q=\left[ \begin{matrix} q_{x}...
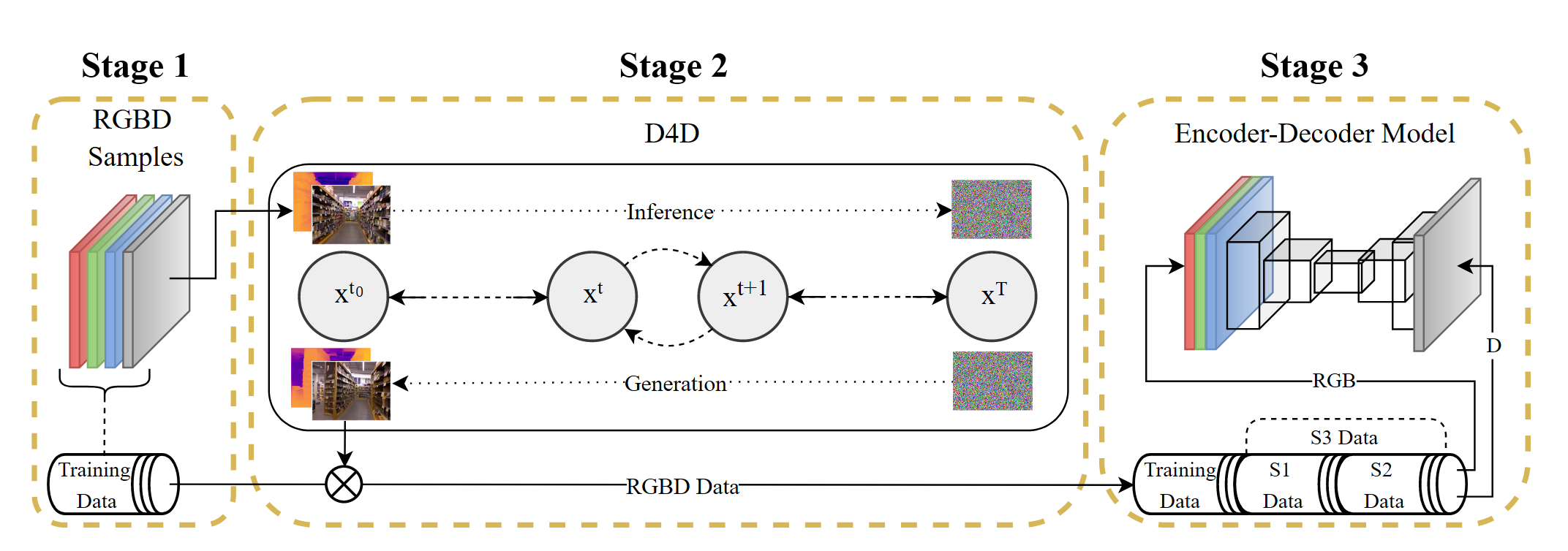
D4D: An RGBD diffusion model to boost monocular depth estimation
方法阶段一对NYU和KITTI中的RGBD样本进行预处理,进行归一化以及rescale,分辨率跟第三阶段所采用的model有关 阶段二第二阶段对输入的RGBD进行前向和后向操作训练网络,同时通过S1和S2两种不同的训练配置,得到不同的生成数据,其中$S1$使用$L1$ loss,$β$策略采用线性策略,$S2$使用$L2$ loss,$β$采用余弦策略 S 1 : L 1=\frac{1} {| \mathcal{P} |} \sum_{p \in\mathcal{P}} | | x_{p}-y_{p} | |_{1}, \; \; \beta=l i n e a r \tag{3} S 2 : L 2=\frac{1} {| \mathcal{P} |} \sum_{p \in\mathcal{P}} | | x_{p}-y_{p} | |_{2}^{2}, \; \; \beta=c o s i n e \tag{4}最终得到的$S3$就是$S1$和$S2$的并集 S 3=( s 1 \cup s 2 ) \; w h e r e \begin{cases} S 1...
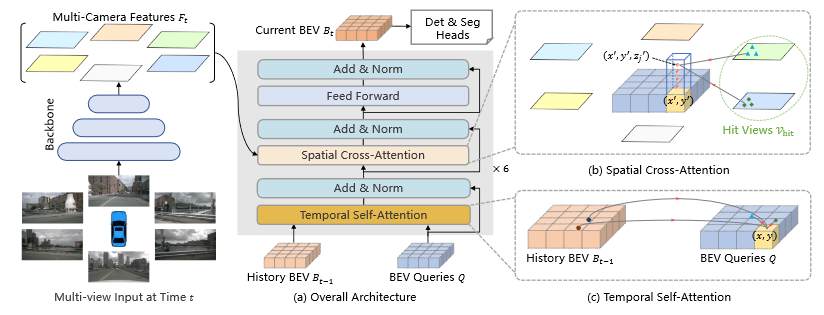
BEVFormer
BEV Queries Q∈R^{H×W×C}where H, W are the spatial shape of the BEV plane. Each grid cell in the BEV plane corresponds to a real-world size of s meters. The center of BEV features corresponds to the position of the ego car by default. Spatial Cross-Attention \mathrm{S C A} ( Q_{p}, F_{t} )=\frac{1} {| \mathcal{V}_{\mathrm{h i t}} |} \sum_{i \in\mathcal{V}_{\mathrm{h i t}}} \sum_{j=1}^{N_{\mathrm{h i t}}} \mathrm{D e f o r m A t t n} ( Q_{p}, \mathcal{P} ( p, i, j ), F_{t}^{i} ), x^{\prime}...
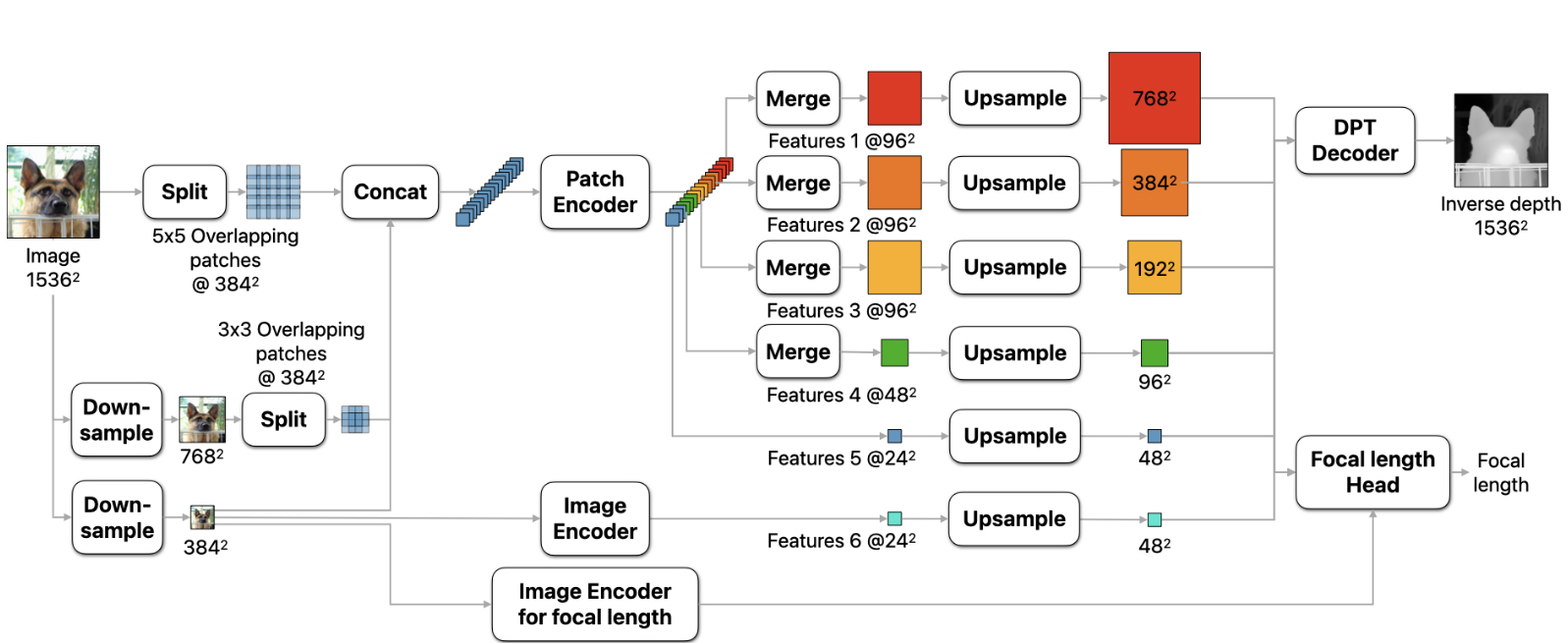
DEPTH PRO: SHARP MONOCULAR METRIC DEPTH IN LESS THAN A SECOND
思路:在不同的尺度提取patches,对patches应用ViT encoders,将patches 的预测结果融合成一个单独的高分辨率的稠密估计。 方法 1.相对于可变分辨率的方法,将输入分辨率固定为了1536×1536,保证了足够大的感受野,防止了out-of-memory的问题。使用普通的ViT encoder,能够利用多种预训练ViT的主干网络。 2.将输入图像分成5×5个分辨率为384×384的重叠patch,下采样至786×786后分成3×3个重叠的patch。将patch链接后输入patch encoder,每一个patch得到分辨率为24×24的feature。在精细的尺度上,进一步提取中间特征。得到特征之后将特征patches融合成maps输入decoder。 Sharp 单目深度估计训练目标网络预测的输出为canonical inverse depth,然后通过视场角转换为metric depth D_m=\frac{f_{px}}{wC}对于metric datasets,使用MAE...
最新文章