UniT: Unified Geometry Learning with Group Autoregressive Transformer
作者:Haotian Wang, Yusong Huang, Zhaonian Kuang, Hongliang Lu, Xinhu Zheng, Meng Yang, Gang Hua
单位:香港科技大学(广州), 西安交通大学, 亚马逊
会议:2026 Arxiv
链接:https://arxiv.org/abs/2605.21131
研究动机

三维几何感知是计算机视觉中的经典且核心的课题,旨在从多张图像观测中恢复出场景的三维结构(通常表示为三维点云)。近年来,以点图(Point Map)为核心表征的前馈 foundation 模型(例如 DUSt3R, MASt3R, Fast3R, VGGT, $\pi^3$, DepthAnything3 等)取得了突破性的成就,这主要得益于其将 2D-to-3D 对应关系学习与 3D-to-3D 几何推理无缝融合在单次模型前向传播中。
然而,尽管这些模型非常强大,它们的核心能力依然碎片化(Fragmented)地散落在多个互不兼容的学术与工业范式中,尚未统一:
- 在线流式感知(Online Inference):适用于机器人导航或自动驾驶等增量视频流场景,需要增量地预测每一帧的几何信息。
- 离线大场景重建(Offline Reconstruction):适用于已知所有视角图像的离线三维重建,常通过并行处理以最大化视角之间的约束。
- 多模态传感器集成(Multi-modal Integration):能够灵活地接收可选的稀疏深度、相机内参或相机外参等异构信号来纠正几何预测。
- 长序列计算的可扩展性(Long-horizon Scalability):随着相机运行时间增长,历史图像帧不断积累,需要维持常数级的计算与显存开销。
- 绝对度量尺度恢复(Metric-scale Estimation):传统的三维重建常伴随严重的尺度歧义(Scale Ambiguity),直接拟合绝对米制尺寸(Metric Scale)往往会导致训练不稳定、跨域泛化性差。
针对这五大维度的瓶颈,现有前馈架构的表现均有严重缺陷。例如:
- DUSt3R 每次前向传播只能推理两张图,对于多视角或视频序列,必须依赖昂贵且耗时的全局对齐后处理(Global Alignment);
- VGGT 和 Fast3R 引入了多视角并行推理,但它们假设输入为离线已知的全局图像序列(Offline Setting),不具备增量处理能力,且当序列长度 $N$ 增大时,显存和复杂度以平方 $O(N^2)$ 的速度激增;
- 传统的 Transformer 自回归架构在应对长序列流式输入时,其 KV-cache 会因对“首帧(Anchor)”的强坐标系绑定而无法中途抛弃,进而导致无边界的内存膨胀。
为此,本研究提出了 UniT,它是首个在统一的组自回归 Transformer(Group Autoregressive Transformer)架构下,将流式/离线视图配置、多模态信号输入、常数级显存开销的长序列扩展性,以及强大的绝对度量物理尺度预测能力集于一身的前馈 3D 视觉基础模型。

核心方法
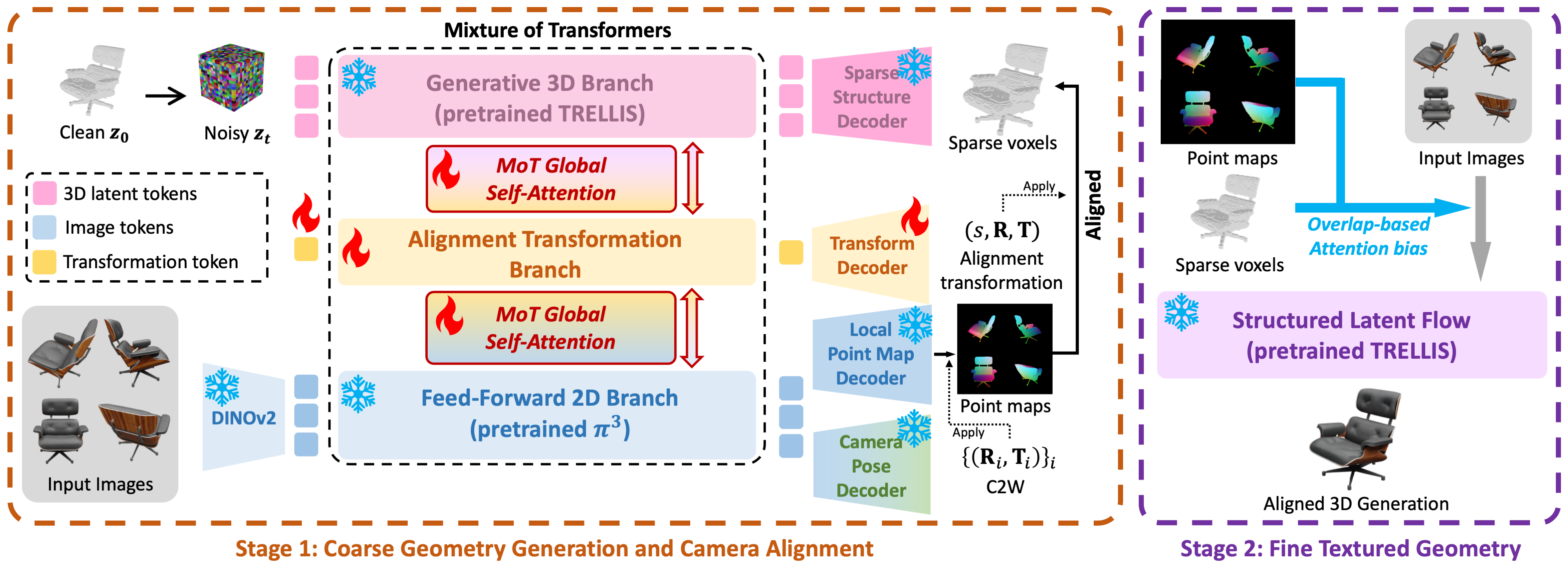
UniT 继承并深度重构了 Visual Geometry Grounding Transformer (VGGT) 的主要特征提取网络,并围绕自回归颗粒度统一、残差零初始化模态融合、无锚点(Anchor-Free)状态解耦与尺度自适应训练约束四大支柱展开设计。其核心框架图如下:

1. 组自回归公式 (Group Autoregression)
几何感知过程可描述为基于模型参数 $\Theta$ 预测序列点图的条件概率分布:
$$P(\{\mathbf{X}_t\}_{t=1}^N \mid \{\mathbf{I}_t\}_{t=1}^N, \{\mathcal{O}_t\}_{t=1}^N; \Theta) = \prod_{t=1}^{N/G} P(\mathbf{X}_t^{1:G} \mid \mathbf{I}_{\leq t}^{1:G}, \mathbf{X}_{\lt t}^{1:G}, \mathcal{O}_{\leq t}^{1:G}; \Theta)$$
其中,$G$ 表示每个时间步自回归的基本成组单位(Group Size),$\mathcal{O}_t$ 表示可选的额外模态输入。
通过调节 $G$ 的大小,UniT 自然地在相同的模型架构下统一了不同的配置:
- 当 $G=1$ 时,网络退化为标准的单目/多视角流式自回归在线推理(即流式深度与姿态预测);
- 当 $G=N$ 时,则退化为单前向离线并行重建(即类似于 VGGT 的离线并行模式)。
在自回归注意力机制中,通过使用组因果掩码(Group Causal Mask),使组内的多个视角能够进行双向注意力(Bidirectional Attention)的跨视图特征交互,而组间则应用严格的因果注意力,限制仅关注当前及历史图像帧。

2. 模态注意力层 (Modal Attention)
模型通过将图像特征与传感器信息进行统一的空间级拼接来灵活地支持多模态接入:
- 密集点标记(Point Tokens):将输入深度图与其由相机内参决定的像素射向矩阵(Local Ray Maps)拼接并进行 MLP 映射;
- 稀疏姿态标记(Pose Tokens):将 12D 的相机外参矩阵进行高维线性编码。
在 DPT Head 对应的第 [0, 5, 12, 18] 层之后插入 Modal Attention。该模块将图像标记与空间对齐后的模态特征残差叠加:
$$\mathbf{M}_t^g = \text{ModalAttn}(\mathbf{I}_t^g, \mathcal{O}_t^g)$$
通过引入零初始化的线性层(Zero-initialized Linear Projection),残差通路在初始阶段输出为 0,这使得模型微调时能 100% 保持 VGGT 已学到的强大几何特征,确保微调稳定快速。这些模块的参数量只占网络总参数量的 3% 左右。

3. 脱离 Anchor 的队列式 KV 缓存机制 (Queue-Style KV Caching)
在传统的自回归网络中,如果要保留几何一致性,必须以第一帧作为坐标锚点(Anchor),导致过往所有帧的 KV-cache 均不能释放,导致计算开销随着帧数剧增。
UniT 基于 Anchor-Free 思想解决了这一难题。它把预测的 12D 相机外参解耦为针对当前自回归单元内部的相对变换:
$$\mathbf{P}_{i} = \mathbf{R}_{i}\mathbf{X}_{i} + \mathbf{T}_{i}$$
由于点图与外参的约束均通过相对变换来度量,网络无需绑定任何绝对参考系,每个位置仅需要记忆当前队列中与自己邻近的局部视角约束。在此基础上,UniT 的 KV-cache 能够被组织为一个先进先出(FIFO)的固定队列。一旦历史缓存帧数超过设定容量 $Q$,最老旧的缓存将被丢弃,从而将显存和计算复杂度锁死在 $O(Q)$ 的常数级别。
同时,论文精简了原版 VGGT 的相机预测头(由 4 次迭代前向改为了单次前向),不仅使得相机头的计算开销锐减了 75%,更极大地方便了自回归模式下的增量 KV 缓存管理。

4. 尺度自适应几何损失 (Scale-Adaptive Geometry Loss)
因为尺度歧义,多视角系统难以直接拟合米制尺度。UniT 借鉴了单目深度估计中相对与绝对约束相融合的思路,设计了尺度自适应损失(Scale-Adaptive Geometry Loss),起到了极佳的自动课程学习(Automatic Curriculum Learning)效果。
模型首先在预测的局部点图 $\mathbf{\hat{P}}_i$ 和相机外参上施加尺度无关(相对)的约束。点图尺度无关项通过真实深度 $\mathbf{D}_i$ 均衡化:
$$\mathcal{L}_{inv\_pt} = \frac{1}{N} \sum_{i=1}^N \frac{\|\mathbf{\hat{P}}_i/\hat{s} - \mathbf{P}_i/s\|_1}{\mathbf{D}_i}$$
再结合一个具有预测置信度 $\mathbf{C}_i$ 的绝对惩罚项:
$$\mathcal{L}_{abs\_pt} = \frac{1}{N} \sum_{i=1}^N \frac{\mathbf{C}_i \|\mathbf{\hat{P}}_i - \mathbf{P}_i\|_1}{\mathbf{D}_i} + \alpha (1 - \mathbf{C}_i)$$
此时,在网络训练早期,模型会优先集中攻克较易收敛的尺度无关几何结构(点图相对排列);随着训练进行,相对平移与局部绝对尺度项驱动整体预测的全局尺度缩放因子 $\hat{s}$ 与 ground-truth 物理尺度 $s$ 进行闭式(closed-form)逼近,最终无痛收敛至米制绝对尺度。
此外,为了确保在大序列下的跨视角几何连续性,UniT 在全局预测点图 $\mathbf{\hat{X}}_i$ 上额外引入了随机洗牌法向损失(Shuffled Normal Loss)。通过对不同帧之间的随机像素进行抽样构建虚拟表面,极大地巩固了视角交界区域的三维几何一致性。

数据集
训练数据集
为了训练获得泛化能力极强的米制尺度特征,UniT 构建了一个由 21 个公开数据集组成的庞大混合训练库(总采样覆盖室内、室外、人体、静态物体和合成仿真等多维场景)。详细的数据集组成与采样权重如下:

测试基准
为了公平地与当前各大主流 SOTA 模型进行对比,测试任务被设定为了 7 个独立的感知方向:多视角重建、相机姿态估计、视频深度预测、单目深度、长序列定位重建、多模态感知和深度图补全。
算力
训练资源
- 硬件平台:64 张 NVIDIA H100 GPU
- 训练周期:7 天以上(约 80K 次迭代)
- 训练超参:
- 主干网络:使用 VGGT 初始化,其中 DINO-v2 编码器全程冻结;
- 学习率:预训练 Backbone 微调率 1e-5,其余模态及 Head 层 1e-4;
- 序列长度:随机在 12 至 24 帧间采样;
- 组大小 $G$:在 1 到 24 间进行随机动态训练采样;
- 批大小:单卡 Batch Size 为 48,图像分辨率 518。
运行复杂度与资源占用率
在 24 帧及长序列流式处理中,UniT 在推理帧率与显存消耗上对主流的 DUSt3R 及 VGGT 表现出绝对碾压级别的硬件开销缩减:

实验结果
1. 多视角重建定性效果
得益于组自回归的全局约束与尺度自适应融合,UniT 能够直接端到端输出处于绝对米制尺度下的三维点云。各序列直接通过预测位姿渲染拼接,没有任何后处理对齐与降噪滤波操作:

2. 7大感知任务定量对比
UniT 在多项评测中全方位击败了包括 DUSt3R, Fast3R, VGGT, DepthAnything3, MoGe 等在内的业界领先几何感知模型:
- 多视角重建 (TABLE III):在 7-Scenes, NRGBD, DTU 上取得更低的三维Chamfer距离。
- 相机位姿估计 (TABLE IV):在 Sintel, TUM, ScanNet 上的绝对轨迹误差(ATE)达到最优。
- 视频与单目深度估计 (TABLE V & TABLE VI):各项 RMSE、AbsRel 误差均取得明显缩减。




3. 多模态集成与长序列表现
- 多模态感知能力 (TABLE VII):测试显示,当给模型喂入稀疏 LiDAR 点、局部内参外参等附加信号后,UniT 的 Chamfer 精度与 ATE 会随着信息的补齐而稳步提升,展现出了极好的可扩展性与融合鲁棒性。
- 深度图补全 (TABLE VIII):完美应对 Sintel, KITTI 的各种超稀疏特征补全任务。
- 长序列定位稳定性 (Fig. 9):当序列帧数长达 90 帧以上时,传统的在线方法会因为累积误差而造成位姿大漂移,而 UniT 由于使用队列式 KV-cache,可以做到在 90 帧的时间内误差依然维持在极低的常数级水平:


4. 关键消融实验
论文对多模态融合、损失函数设计、缓存丢弃算法进行了深度消融,并详细绘制了自回归组大小与 KV 缓存队列容量对定位精度的曲线影响:





优势与不足
优势
- 多重视角与多模态在基础模型中的大一统:UniT 改变了学术界以往“单目深度”、“多目重建”、“SLAM定位”三块业务割裂研究的局面,以单个统一的组自回归模型横扫几乎全部几何感知任务。
- 解决自回归显存无限增长的硬伤:基于 Anchor-Free 空间解耦设计的固定长度 FIFO 缓存管理,首次实现了常数级显存占用且完全不依赖第一帧坐标系,对边缘设备和增量三维感知有着极为重要的应用价值。
- 优雅且高度稳健的度量尺度训练课程:巧妙结合的尺度自适应损失,成功驯服了训练直接回归物理尺度的不稳定性,保证了混合 21 个异构数据集训练的高质量收敛。
不足
- 高昂的训练资源壁垒:使用 64 张 H100 训练超 7 天的算力成本对大多数中小型科研团队来说是不可逾越的鸿沟。
- 强依赖冻结的 DINO-v2 特征:冻结 DINO-v2 意味着模型底层的特征颗粒度上限已经完全由 DINO 决定。如果遇到极端的低纹理、动态干扰或模糊运动区域,模型提取有效几何特征的上限会遭遇瓶颈。
- 长序列大开阔场景下的闭环能力退化:为了维持常数显存,FIFO 队列会在行驶距离过长时抛弃全部“远古历史帧”。当相机再次回到原点时,由于早期 KV-cache 已彻底从队列移除,模型将无法实现闭环(Loop Closure),容易累积位姿漂移。
记忆点
- 组自回归(Group Autoregression)的颗粒度统一:这是解决流式视频和离线重建架构割裂的杀手锏。通过灵活改变成组大小 $G$,把组内设为 Bidirectional(充分提取短时空间一致性),组间设为 Causal(限制时间传播关系),在公式层面完美大一统。
- 零初始化的残差多模态注入 (Zero-initialized Modal Residual Block):在模态融合中引入残差结构,且其输出映射层的权重全部初始化为 0。该操作在数学上屏蔽了初始阶段模态模块对网络产生的任何负面抖动,使模型能无损、平滑且极快地继承大型离线预训练模型(如 VGGT)中蕴含的几何表征。
- 摆脱首帧锚点的自回归 (Anchor-Free Autoregression):自回归要引入 FIFO 队列,就不能存在对全局绝对原点的依赖(因为丢掉首帧就会导致坐标系瓦解)。UniT 极具创意地将位姿与点图损失全部构造为基于当前窗口内相对几何变换的表达形式,使整个局部系统在空间上具有平移/旋转不变性,完美解决自回归缓存的“空间泄露”问题。
 微信
微信 支付宝
支付宝