BetterDepth: Plug-and-Play Diffusion Refiner for Zero-Shot Monocular Depth Estimation
Problem Formulation
feed-forward model:
Diffusion model:
Framework

Global Pre-Alignment
给定预训练仿射不变深度模型$\bf{M}_{FFD}$ 和数据对$\bf{(x, d)} ∈ \bf{D}_{syn}$ ,先预测粗糙的深度图$\bf{\widetilde{d}}=\bf{M}_{FFD}(x)$,估计尺度$s$和偏移量$b$对$\bf{\widetilde{d}}$进行对齐:
VAE Encoder将$\bf{x, \widetilde{d}^{‘}, d}$转换到潜在空间,然后对$\bf{d}$加噪声得到$\bf{z}^{d}_t$和$\bf{z^x,z^{\widetilde{d}^{‘}}}$连接输入UNet训练。
Local Patch Masking
将$\bf{\widetilde{d}^{‘}, d}$分为多个patch,然后计算对应patch的欧氏距离比较patch之间的相似性:
mask:
Inference Strategies

精细的细节是diffusion model 带来的么,如果不是的话,diffusion 的部分是不是也可以更换为传统的回归模型
 微信
微信 支付宝
支付宝
相关推荐
2024-12-06
D4D: An RGBD diffusion model to boost monocular depth estimation
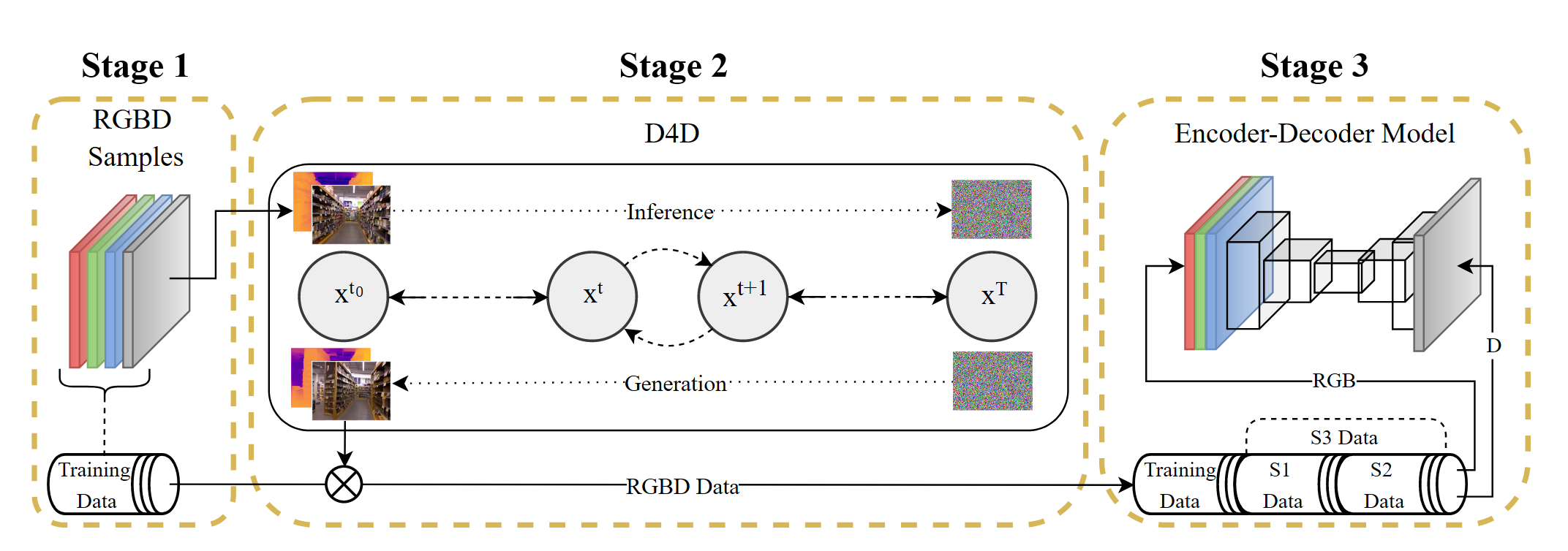
方法阶段一对NYU和KITTI中的RGBD样本进行预处理,进行归一化以及rescale,分辨率跟第三阶段所采用的model有关 阶段二第二阶段对输入的RGBD进行前向和后向操作训练网络,同时通过S1和S2两种不同的训练配置,得到不同的生成数据,其中$S1$使用$L1$ loss,$β$策略采用线性策略,$S2$使用$L2$ loss,$β$采用余弦策略 S 1 : L 1=\frac{1} {| \mathcal{P} |} \sum_{p \in\mathcal{P}} | | x_{p}-y_{p} | |_{1}, \; \; \beta=l i n e a r \tag{3} S 2 : L 2=\frac{1} {| \mathcal{P} |} \sum_{p \in\mathcal{P}} | | x_{p}-y_{p} | |_{2}^{2}, \; \; \beta=c o s i n e \tag{4}最终得到的$S3$就是$S1$和$S2$的并集 S 3=( s 1 \cup s 2 ) \; w h e r e \begin{cases} S 1...
2026-05-25
DepthAgent: Towards Better Universal Depth Estimation via Sample-wise Expert Selection
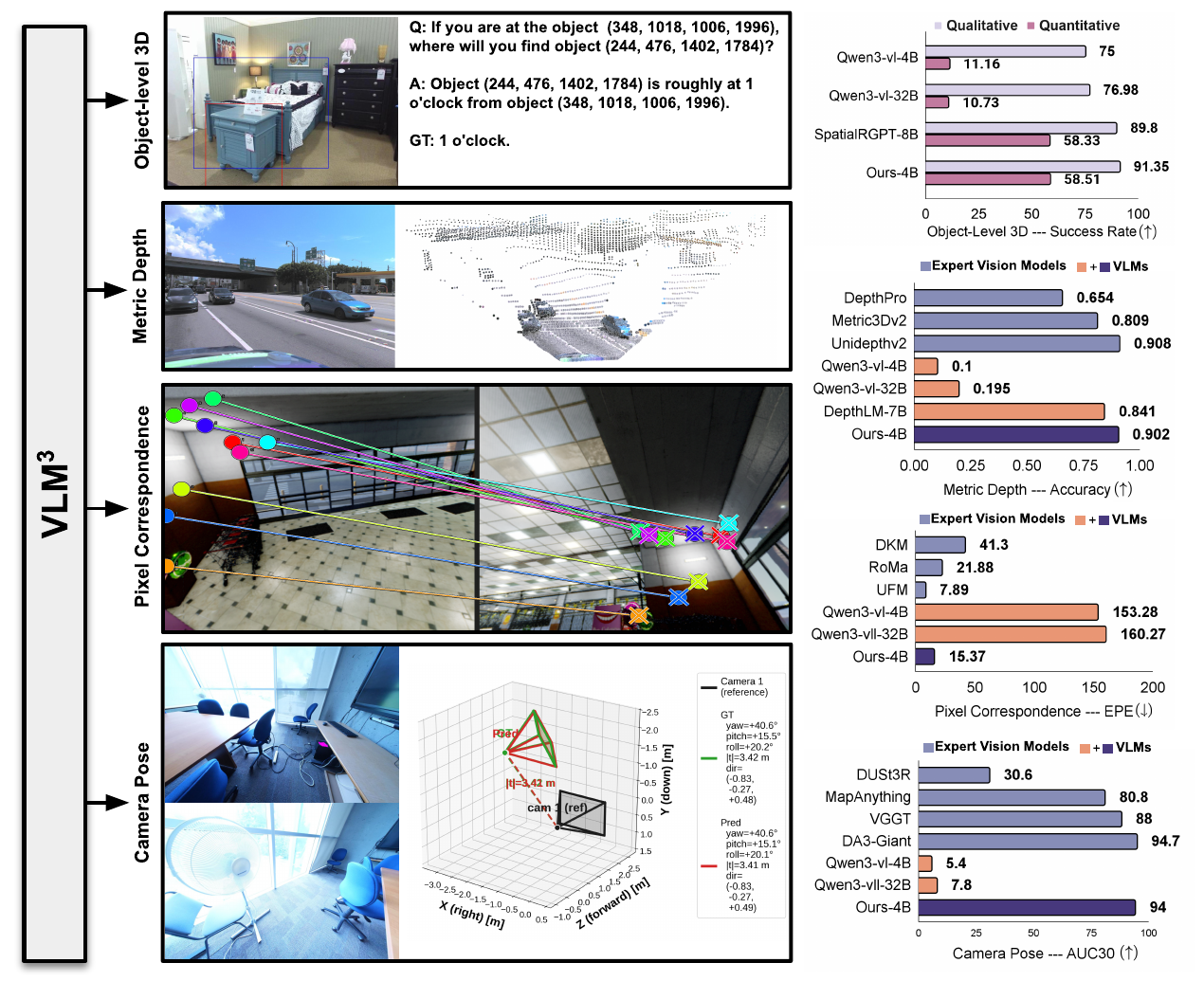
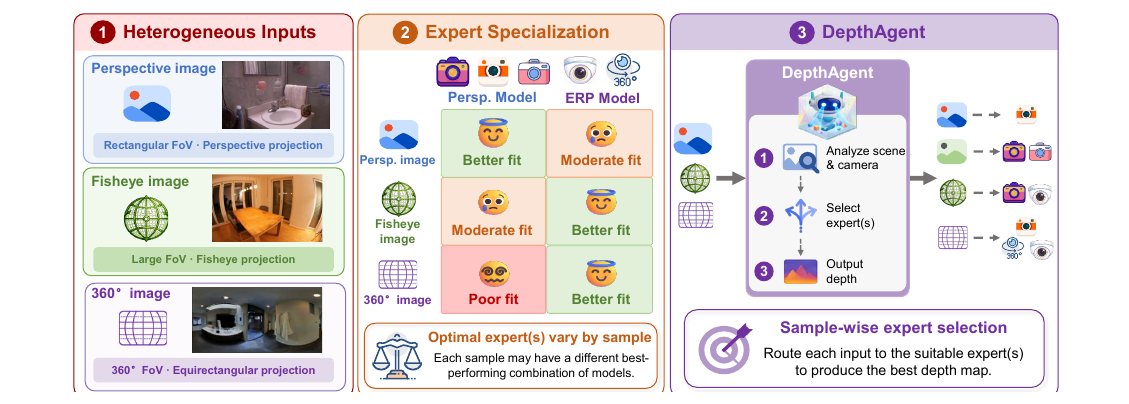
作者:Jie Zhu, Girish Chandar Ganesan, Xiaoming Liu 单位:Michigan State University, University of North Carolina at Chapel Hill 会议:2026 Arxiv 链接:https://arxiv.org/abs/2605.23281 研究动机 这篇文章的出发点很实际:现在单目 metric depth 模型已经很多,而且每个模型都很强,但真实部署时输入并不总是同一种相机。普通透视图、鱼眼图、ERP 全景图在成像几何上差别很大,一个模型即使在平均指标上很强,也不一定能稳定覆盖所有相机域。 已有“通用深度估计”通常试图训练一个统一模型,或者对多个模型做固定规则融合。但本文先指出一个更细的现象:不同 depth expert 的强弱不是随机的,而是和相机几何、场景类型、样本难度强相关。 Table 1 说明了这个现象。透视数据里,Perspective 系模型作为 best single 的比例达到 80.1%;Native ERP 数据里,ERP 系模型作为 best...
2024-12-06
Depth Anything v2
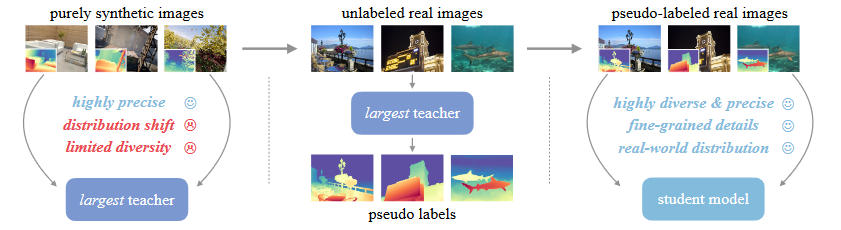
三个关键方法:1)将所有有标签的真实图像更换为合成图像 2)增强了教师模型的capacity 3)通过大规模伪标签真实图像对学生模型进行训练 真实标签数据的缺点:1)标签噪声:传感器固有的缺点、透明等场景 2)忽略的细节:边缘、洞 导致错误的估计,过度平滑的估计 合成数据的局限性:1)合成图像与真实图像之间的分布偏移 真实图像包含更多随机性,合成图像场景的布置较为有序。 2)所覆盖的场景有限,难以与真实世界的场景相匹敌 大规模无标签真实图像的作用:1)缩小合成图像与真实场景之间的领域差异 2)增大所覆盖的场景范围 3)知识迁移 sparse的gt在评估的时候真的会影响指标的可靠性么? 能否直接训练或者使用一个强大的metric depth网络来生成metric的伪标签,从而使得学生模型能够具备metric depth预测能力?
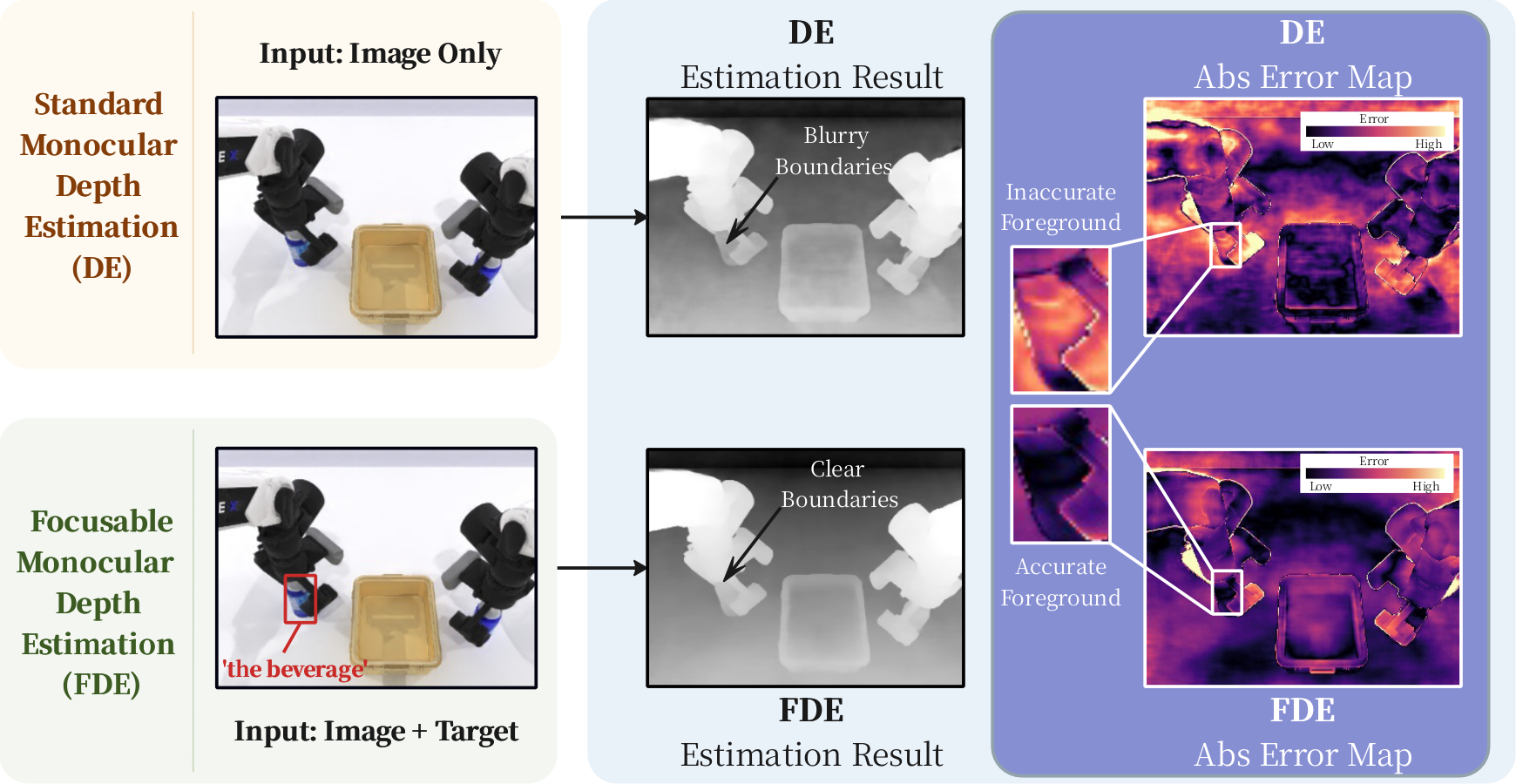
2026-05-14
FocusDepth: Focusable Monocular Depth Estimation
作者:Yuxin Du, Tao Lin, Zile Zhong, Runting Li, Xiyao Chen, Jiting Liu, Chenglin Liu, Ying-Cong Chen, Yuqian Fu, Bo Zhao 单位:School of Artificial Intelligence, Shanghai Jiao Tong University; The Hong Kong University of Science and Technology (Guangzhou); King Abdullah University of Science and Technology 会议:2026 Arxiv 链接:https://arxiv.org/abs/2605.11756 研究动机 现有单目深度估计通常是 image-centric 的:输入一张图,输出一张整图深度,训练和评测也主要把所有有效像素的误差聚合起来。这个设定对全局场景理解很合理,但很多真实任务其实不是平均地关心每个像素。 机器人抓取时更关心目标物体和接触边界,AR...

2026-05-19
Lotus-2: Advancing Geometric Dense Prediction with Powerful Image Generative Model
作者:Jing He, Haodong Li, Mingzhi Sheng, Ying-Cong Chen 单位:HKUST(GZ), UC San Diego, HKUST 会议:2025 Arxiv 链接:https://arxiv.org/abs/2512.01030 研究动机 这篇文章讨论的是一个很尖锐的矛盾:单目几何密集预测本质上是病态问题,但现在最强的两类路线各有明显短板。 大规模判别式深度模型依赖海量监督数据,性能上限很大程度由训练集规模、真实性和标注质量决定,一旦遇到稀有场景或开放域图像,泛化就容易掉下来。 扩散/rectified-flow 这类生成模型确实在海量图文数据里学到了强 world prior,但它们原生的随机采样、多步生成和高保真图像目标,并不天然适合“同一张图稳定输出一张几何图”这种确定性任务。 如果直接把生成模型的随机生成范式搬过来,模型会出现结构方差、几何幻觉和推理开销过高的问题;但如果完全退回普通回归模型,又拿不到生成模型里蕴含的大规模几何先验。 所以 Lotus-2...
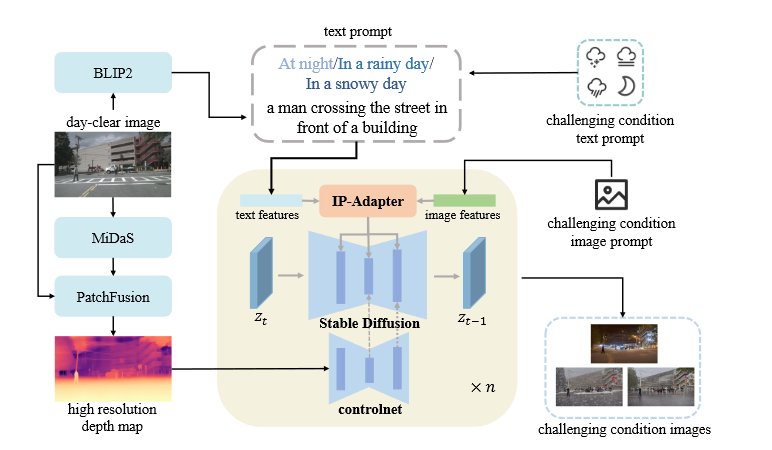
2024-12-08
SSD:Stealing Stable Diffusion Prior for Robust Monocular Depth Estimation
背景现有的MDE方法在标准的环境下(例如晴天)表现的很好,但是在一些具有挑战性的条件下效果会变得很差,这主要是由于一些关键的假设失效了,例如光度一致性假设,同时也没有可靠的ground truth包含这些场景。 现有的一些鲁棒的解决方案 基于模型的方法 这一方法通过修改网络结构来增强模型处理各种条件的能力 缺点:网络模型过于复杂,不能够适应各种环境 基于数据的方法 利用域自适应或其他模态的数据来增强图像信号 缺点:缺乏高质量的数据,需要后处理 方法Generative Diffusion Model-based Translation生成在深度方面与白天清晰图像非常相似的训练样本 I_{g}=S D ( I P ( T_{p}, I_{p} ), C N ( D_{h} ), z ) BILP2:获取场景描述符,保留图像内容信息 ControlNet d2i:保持近似深度一致性 MiDas:获取初始深度图 PatchFusion:获得高分辨率的深度图 text prompt=BILP2 场景描述符+challenging condition...
评论