Pow3R:Empowering Unconstrained 3D Reconstruction with Camera and Scene Priors
作者:Wonbong Jang, Philippe Weinzaepfel, Lourdes Agapito, Vincent Leroy, Jerome Revaud
单位:UCL, Naver Labs Europe
会议:2025 CVPR
研究动机
传统的SfM(如COLMAP)缺乏预先学习的先验,每个场景必须独立优化,且对异常值和挑战性条件很敏感 。
现有的3D视觉基础模型(如DUSt3R和MASt3R)输入空间受限,仅支持纯RGB图像输入,无法利用测试时可能获取到的辅助先验信息(如相机内参、相对位姿或稀疏/稠密深度图) 。
缺乏高分辨率处理能力,受限于训练分辨率,DUSt3R处理大尺寸图像时容易模糊,且由于不输出第二张图自身坐标系下的点图,相对位姿估计速度慢且需要两次前向传播 。
能否设计一个统一的3D前馈回归模型,既能像DUSt3R一样在无约束条件下工作,又能灵活地在测试时注入任意组合的相机或场景先验,从而实现精度的提升以及原生高分辨率处理等新功能?
核心方法

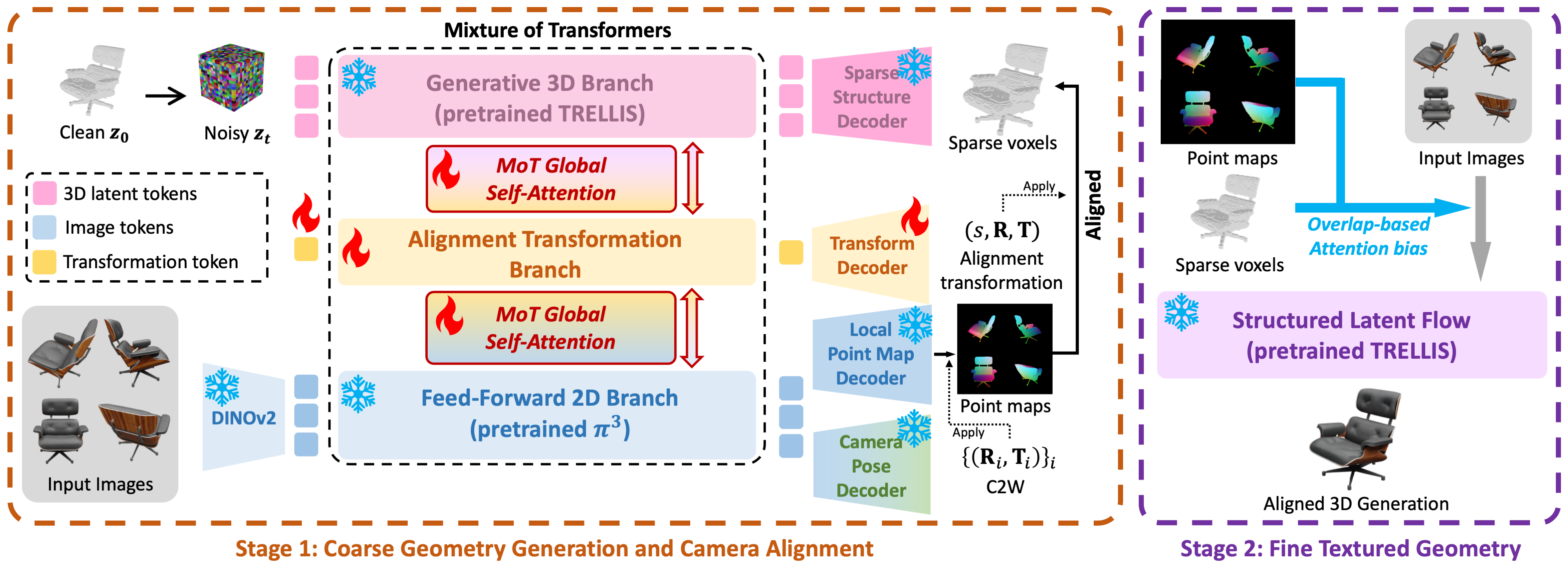
统一的多先验注入网络架构

模型基于DUSt3R的Transformer架构,但在预测 $X^{1,1}$ 和 $X^{2,1}$ 的基础上,增加了一个预测分支来输出第二张图像在其自身相机坐标系下的点图 $X^{2,2}$ 。为了注入辅助信息,模型采用了“Inject-1”策略,即在Encoder或Decoder的第一个Block注入对应的多模态嵌入特征 。
- 多模态先验的特征编码与对齐
内参(Intrinsics): 将相机内参 $K$ 转换为密集的相机光线映射 $K^{-1}[i,j,1]$,进行Patchify编码后与RGB特征结合,这使模型能够理解非中心裁剪图像的空间位置 。
深度(Depthmaps / Point Clouds): 将稀疏或稠密的深度图 $D$ 及其掩码 $M$ 拼接为 $[D’, M]$ 后进行Patchify编码输入到Encoder 。
相对位姿(Camera Pose): 将相对位姿平移向量归一化后,通过MLP编码并直接加到Decoder的全局CLS Token上 。
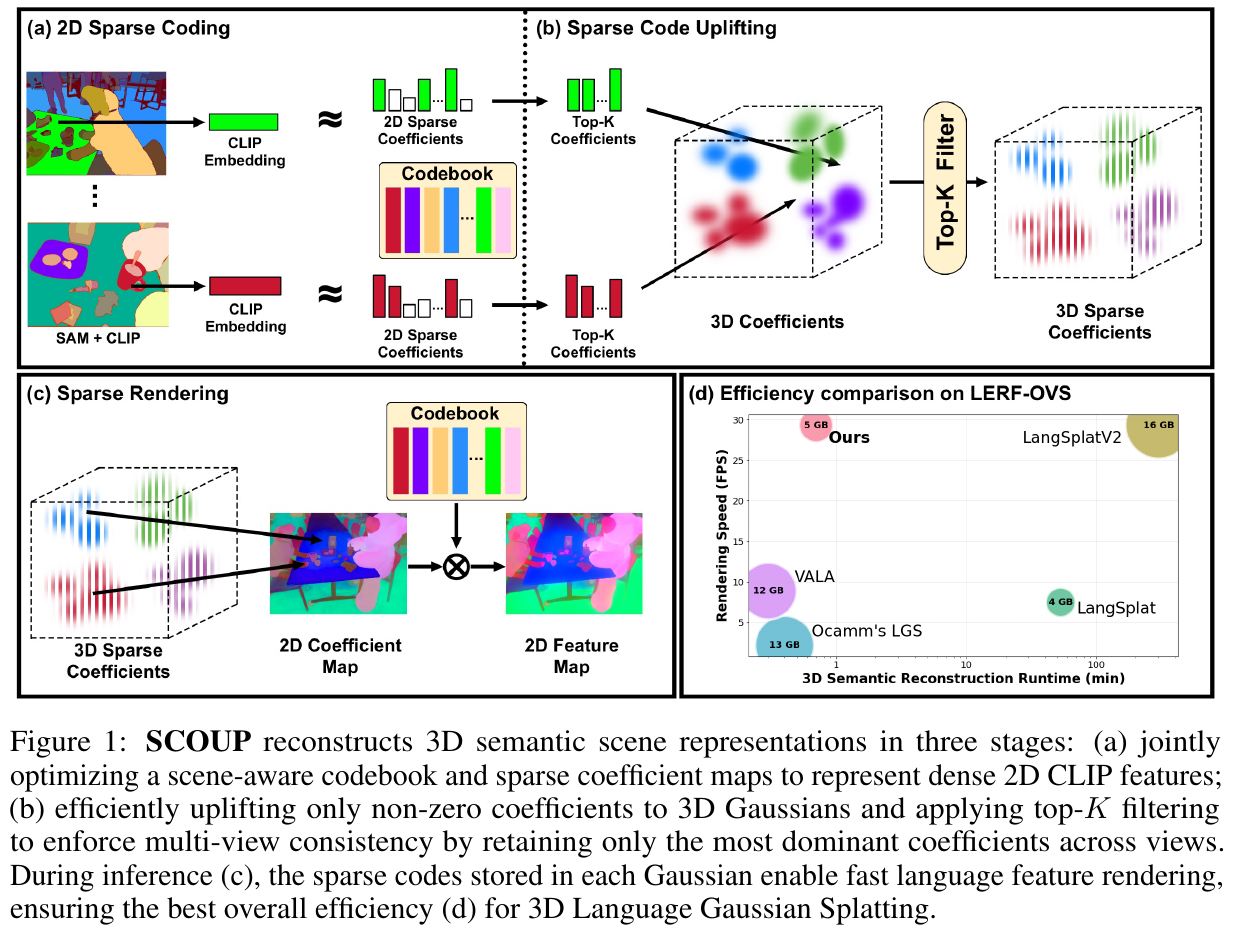
- 基于置信度的3D回归损失
除了预测点图,模型还预测置信度图 $C_{i,j}^{n,m}$。损失函数采用置信度加权的尺度不变3D回归损失,鼓励模型在困难区域推断:
其中,$\alpha=0.2$ 。总损失结合了三个点图的预测 。
- 滑动窗口高分辨率处理与快速位姿估计
由于注入了相机内参光线,模型具备了“裁剪感知”能力 。推理时可以通过滑动窗口切片处理高分辨率图像,通过中值尺度因子对齐重叠区域,实现原生高分辨率预测 。同时,利用新预测的 $X^{2,2}$ 和 $X^{2,1}$,可以直接通过Procrustes对齐算法求解相对位姿 $[R^|t^]$,比RANSAC PnP快一个数量级:
数据集
Train:Habitat, MegaDepth, ARKitScenes, Static Scenes 3D, BlendedMVS, ScanNet++, Co3D-v2, Waymo (共计850万图像对)
Eval:NYUv2 (深度补全), KITTI, ScanNet, ETH3D, DTU, Tanks and Temples, Co3Dv2, RealEstate10K, InfiniGen
算力
8张 A100 GPUs (先在 224px 分辨率下训练3天,再在 512px 下微调2天)
实验结果






优势与不足
优势
极其灵活的输入模态: 在没有任何先验时,性能与DUSt3R相当;当提供任意组合的先验(内参、稀疏深度、位姿)时,性能均能得到显著提升(统一网络,无需重新训练) 。
解锁了高分辨率预测能力: 通过引入内参对应的光线编码,打破了Transformer固定分辨率的限制,实现了基于滑窗的无缝高分辨大图推理 。
推断效率的巨大提升: 单次前向传播即可输出 $X^{2,2}$,使得相对位姿估计可以直接使用Procrustes对齐,相比传统PnP速度提升约10倍 。
对噪声先验的鲁棒性(可控性): 当输入的辅助信息偏离真实值太多时,模型能够自主判断并降低预测置信度,而不会被错误先验完全带偏 。
不足
继承了基础模型(如DUSt3R)的计算代价,ViT处理图像对的方式在应对超大规模视频或实时SLAM系统时依然偏重 。
对于极度缺乏纹理或者存在极强反射的困难区域,尽管有置信度预测,仅靠双视图的匹配与先验仍可能存在一定的不稳定。对于全局大规模场景,仍需依赖全局对齐优化(Global Alignment) 。
记忆点
随机模态丢弃训练 (Random subset dropout): 训练时随机丢弃不同的辅助输入组合,使得单一模型可以在测试时自适应不同级别的先验信息 。
将内参转化为空间光线映射 (Rays from Intrinsics): 这一简单的设计赋予了图像块强烈的空间位置先验,从而允许模型理解局部裁剪(Crop),解锁了高分辨率推理 。
$X^{2,2}$ 的预测极大提升位姿解算效率: 预测第二张图自身坐标系的点图,使得原本复杂的透视N点问题(PnP)简化为闭式解的Procrustes对齐问题 。
 微信
微信 支付宝
支付宝