MTD: The Midas Touch for Metric Depth
作者:Yu Ma, Zizhan Guo, Zuyi Xiong, Haoran Zhang, Yi Feng, Hongbo Zhao, Hanli Wang, Rui Fan
单位:College of Electronic and Information Engineering, Tongji University; Shanghai Research Institute for Intelligent Autonomous Systems, Tongji University; National Key Laboratory of Human-Machine Hybrid Augmented Intelligence, Xi’an Jiaotong University
会议:2026 Arxiv
链接:https://arxiv.org/abs/2605.11578
研究动机

相对深度基础模型已经有很强的跨场景泛化能力,例如 MiDaS、DepthAnythingV2、Marigold 等模型可以在新场景里给出结构很好的相对深度。但是这类输出天然缺少米制尺度,直接落到机器人、自动驾驶、SLAM 或 RGB-D 设备增强时,会遇到三个问题。
全局尺度对齐不够。用少量 3D 点做一次全局 least-squares 可以把相对深度拉到米制尺度,但不同物体、不同区域往往有不同的 scale ratio 和 shift bias,一个全局仿射变换很难同时照顾远处道路、近处物体和细薄结构。
训练式深度补全泛化成本高。BP-Net、DMD$^3$C、Marigold-DC 等方法通过网络融合 RGB 和稀疏深度,但通常依赖特定训练域或大规模深度补全数据,换场景、换传感器、换稀疏模式时未必稳。
真实系统还需要速度。高质量扩散式深度模型和大 backbone 往往推理慢,嵌入式设备或手持 RGB-D 系统更需要一个轻量、可插拔、数学上可解释的后端。
这篇论文的核心问题可以概括为:
能否只用极稀疏的 3D seed,把任意相对深度基础模型的输出稳定地转换为米制深度,同时保持跨场景泛化、边界质量和实时部署能力?
核心方法

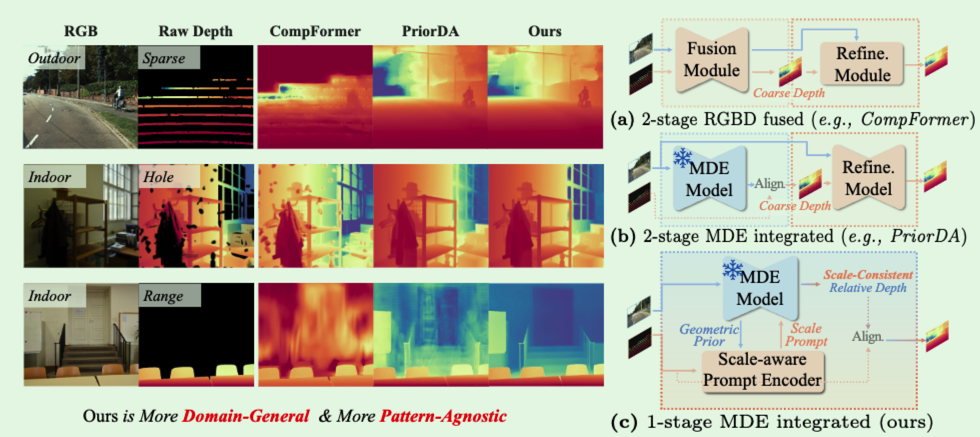
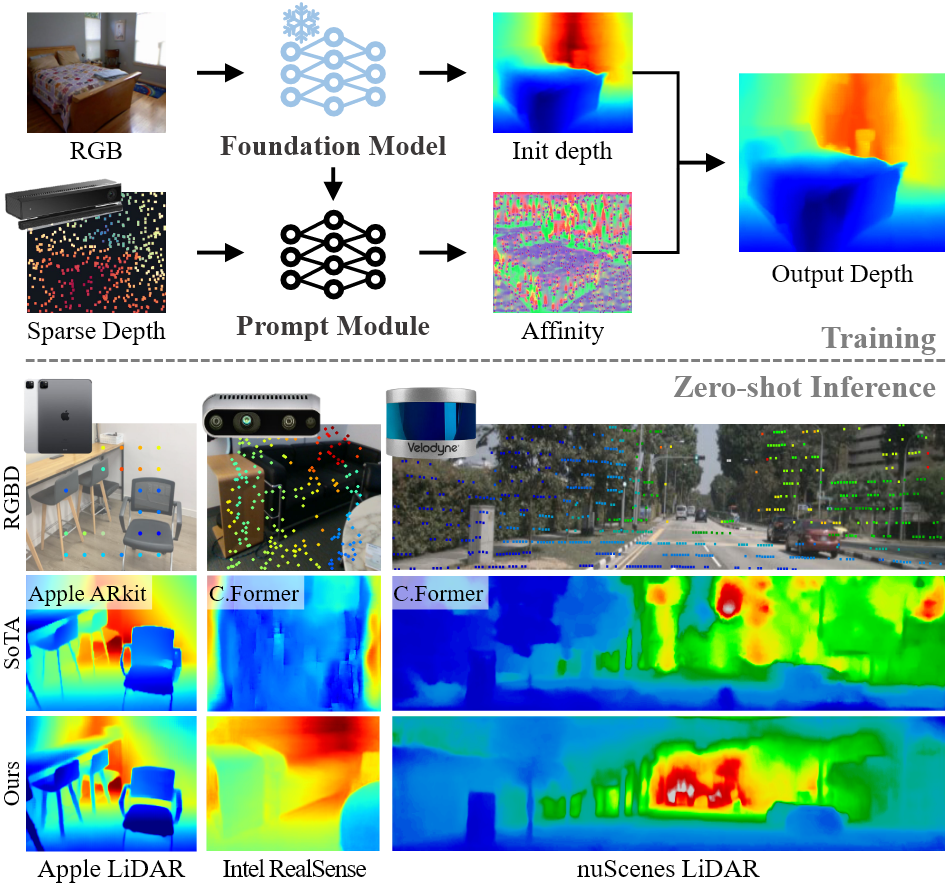
MTD 的输入包括一张 RGB 图像、一个深度基础模型输出的相对深度、极稀疏 3D seed,以及由图像得到的 superpixel segment set。输出是 dense metric depth。整个方法是一个 coarse-to-fine pipeline:先做分段尺度恢复,再做像素级细化。
1. 3D seed 的统一视角
论文把可提供尺度信息的稀疏输入都称为 3D seeds。它可以来自 LiDAR sparse depth、低成本 RGB-D 相机的粗深度、stereo 或 MVS 中的 correspondence matches。关键不是输入来源,而是这些点能给相对深度提供少量已知尺度锚点。
相对深度模型给出每个 seed 投影位置的相对深度 $d_i^j$,3D seed 给出可与真实深度单调对应的 scalar proxy $\xi_i^j$。MTD 的任务就是学习从 $d$ 到 $\xi$,再到 metric depth $z$ 的局部映射。
2. Segment-wise recovery:先把局部尺度找回来
如果直接对整张图做全局 least-squares,只能得到一个统一尺度。MTD 先把图像切成 superpixels,每个 segment 都允许有自己的标定函数 $g_i:d\mapsto\xi$。对于含有 seed 的 segment,论文用 least-squares 或 median matching 得到局部标定参数,并把这些参数存在 lookup table 里。
问题在于 seed 很稀疏,很多 segment 没有任何投影点。论文因此构建一个 segment graph $\mathcal{G}=(\mathcal{V},\mathcal{E})$,每个节点对应一个 segment,边权由 segment centroid 的距离衰减核决定,并保留近邻边来稀疏化图。然后求解图正则化目标:
第一项让有 seed 的 segment 保持自己的尺度锚点,第二项让邻近 segment 的标定参数平滑传播。这样就能把少量 seed 的尺度信息扩散到整张图,同时避免跨物体边界的过度混合。
3. Pixel-wise refinement:再把 segment 内残差补掉
分段标定之后仍然会有像素级误差,尤其是 segment 内部深度变化、边界附近和细结构区域。MTD 把这个问题改写成 discontinuity-aware geodesic propagation。
论文从 coarse metric depth $z(u,v)$ 出发,定义二阶变化相关的局部不连续密度:
若一条路径穿过物体边界,$\phi$ 会变大,路径代价也会变大。于是从可靠 seed 像素向其他像素传播时,最短测地路径会倾向于沿同一物理表面传播,而不是跨越深度断裂。连续形式的测地代价为:
离散实现里,论文把路径积分写成单像素移动的 Riemann sum,并用 dynamic programming 求解。每次更新把旧估计和当前局部预测做凸组合:
这个设计的好处是,传播不是普通的局部滤波,而是带有几何意义的路径优化。它既能补 seed 周围的局部误差,又能避免把前景物体的深度错误传播到背景。
4. 轻量化 front-end
MTD 的后端是非参数的,主要耗时来自前端相对深度模型。论文进一步用 DepthAnythingV2 作为 teacher,通过 feature distillation 和 logit distillation 蒸馏 TinyViT、EfficientViT 等轻量 backbone。这样 MTD 不必依赖大模型,也能在 Jetson AGX Orin 这类平台上接近实时运行。
数据集
训练或蒸馏数据主要包括:
- VKITTI2
- Hypersim
- TartanAir
- SA-1B
深度估计评测使用 KITTI、NYU-Depth V2、ScanNet、ETH3D、DIODE 等数据集,采用 prior works 的 split。
深度补全评测覆盖 nuScenes、DDAD、Make3D、DIODE、ETH3D、ScanNet、VOID、SUN-RGBD、IBims-1、HAMMER 等数据集。nuScenes、DDAD、VOID 本身提供 sparse depth;其他数据集通过随机保留 $0.01\%-0.1\%$ 的深度点来模拟极稀疏输入,并加入 $10\%-20\%$ 的噪声扰动。
下游应用还包括 RealSense D455 深度修正、VGGT 多视角重建、KITTI Odometry 上的 SLAM,以及 KITTI-360 上的 occupancy prediction。
算力
论文没有明确给出训练用 GPU 数量和完整训练时长,但给了较详细的推理设置。
VOID1500 上的速度和精度对比使用 RTX 3090,输入分辨率为 $480\times640$。
MTD 后端开销很小。在 $480\times640$ 输入上,segment-wise recovery 加 pixel-wise refinement 的总后端时间为 1.9 ms,显存低于 1.8 GB,GPU utilization 低于 4%。
嵌入式实验使用 NVIDIA Jetson AGX Orin Platform,并经过 TensorRT 与多线程加速。论文强调后端是非参数轻量算法,主要瓶颈是前端 depth foundation model。

实验结果

在深度补全 zero-shot 评测中,MTD 在多数数据集上超过现有方法。相对于 Marigold-DC,论文特别指出在 nuScenes 上 MAE 降低 0.418,RMSE 降低 0.537。表格里的整体趋势是:室外数据集更难,因为点云更稀疏、深度范围更大,但 MTD 的分段尺度恢复能明显缓解全局对齐失效。
在单目深度估计评测中,MTD 被作为 plug-and-play 后端接到不同相对深度模型后面。MiDaS、LeReS、DPT、Depth Pro、DepthAnythingV2、Marigold、GeoWizard、Lotus、DepthMaster 等模型接入 MTD 后,AbsRel 普遍下降,$\delta_1$ 普遍上升。与 DepthAnythingV2 搭配时整体效果最好,因此论文后续硬件和应用实验主要采用 DepthAnythingV2。

消融实验验证了几个关键设计:
Per-segment calibration 中,least-squares 优于 median,对 inverse depth $z^{-1}$ 做 proxy 效果更好。
Sparse graph optimization 比 global-based propagation 更稳,在 KITTI 和 VOID 上都降低 RMSE/MAE。
Pixel-wise refinement 中,去掉 $d_\phi$ 后效果下降,说明普通边缘或无测地约束的传播不足以处理跨边界错误。多项式 basis 优于 B-spline,较大的迭代 receptive field 在 KITTI 上继续带来收益。
当 3D seed 数量很少时,MTD 会退化接近全局 least-squares,相当于有一个保守下限;当 seed 增多时,MTD 能继续利用更细的 segment scale,而全局 least-squares 的提升有限。


下游应用的结论也比较强。对于低成本 range camera,Raw + MTD 在室内和室外都显著降低 RMSE/MAE,并改善边界和缺失区域。对于 VGGT 多视角重建,MTD 用 correspondence triangulation 得到的 3D seeds 做尺度恢复,比简单 Align 更准,也超过 MVSAnywhere 的整体 RMSE/MAE。SLAM 实验中,Droid + MTD 在 KITTI Odometry 多个序列上明显降低 ATE-RMSE,说明这个后端不只是表格分数好,对几何下游也有帮助。


补充材料里的定性图说明了两个直观现象:一是 MTD 能在多数据集上比学习式深度补全保留更稳定的结构,二是对常见 range camera 的粗糙深度,它能补全空洞、锐化边界,并把 raw depth 中的大片噪声或模糊结构变得更接近真实几何。
优势与不足
优势
思路非常工程化。它不试图重新训练一个万能深度补全网络,而是把已有相对深度基础模型的泛化能力保留下来,用少量 3D seed 解决尺度问题。
数学解释比较清楚。Segment graph 负责局部尺度传播,geodesic cost 负责像素级边界感知传播,两部分都能说清楚为什么有效。
输入形式灵活。LiDAR sparse depth、range camera、stereo disparity、multi-view correspondences 都可以被统一成 3D seeds。
后端非常轻。1.9 ms 的后端开销使它更像一个几何校准模块,而不是一个额外大网络。
消融完整。论文不仅比较 SoTA,还分析了 seed 数量、segment scale、foundation model capacity、proxy domain、graph optimization 和 dynamic programming。
不足
MTD 仍然需要外部 3D seed。它不是纯单目 metric depth,若完全没有尺度输入,就无法凭空解决 absolute scale。
分段质量会影响局部尺度恢复。论文显示不同 superpixel 方法的最优结果接近,但真实复杂场景里,segment 与物体边界不一致时仍可能传播错误尺度。
前端相对深度模型仍是主要瓶颈。后端很快,但系统端实时性取决于 chosen backbone,轻量 backbone 会牺牲一定精度。
对传感器错位和噪声有鲁棒性实验,但极端遮挡、动态物体、多传感器时间不同步等情况仍可能影响 seed 的可靠性。
训练或蒸馏细节没有完整量化算力成本,复现实验时还需要代码和 checkpoint 进一步确认。
记忆点
MTD 的本质不是深度补全网络,而是“相对深度基础模型 + 极稀疏 3D seed”的米制尺度转换器。
全局 least-squares 只能解决整体尺度,真正的问题是 local scale inconsistency,所以 segment-wise calibration 是核心。
Discontinuity-aware geodesic cost 把像素级修正写成路径积分问题,传播会自然避开深度断裂。
当 3D seed 变稀疏时,算法退化到全局对齐附近;当 seed 变多时,它能自动转向更细的局部尺度恢复。
这类方法很适合做 depth foundation model 的几何后处理层:不破坏模型泛化能力,却补上 metric scale 和真实系统所需的稳定性。
 微信
微信 支付宝
支付宝