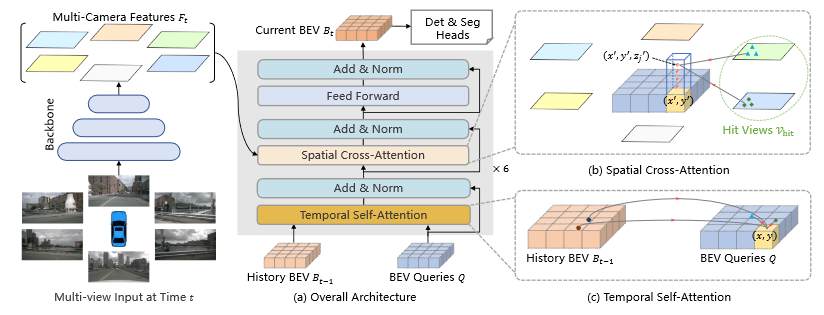
BEVFormer
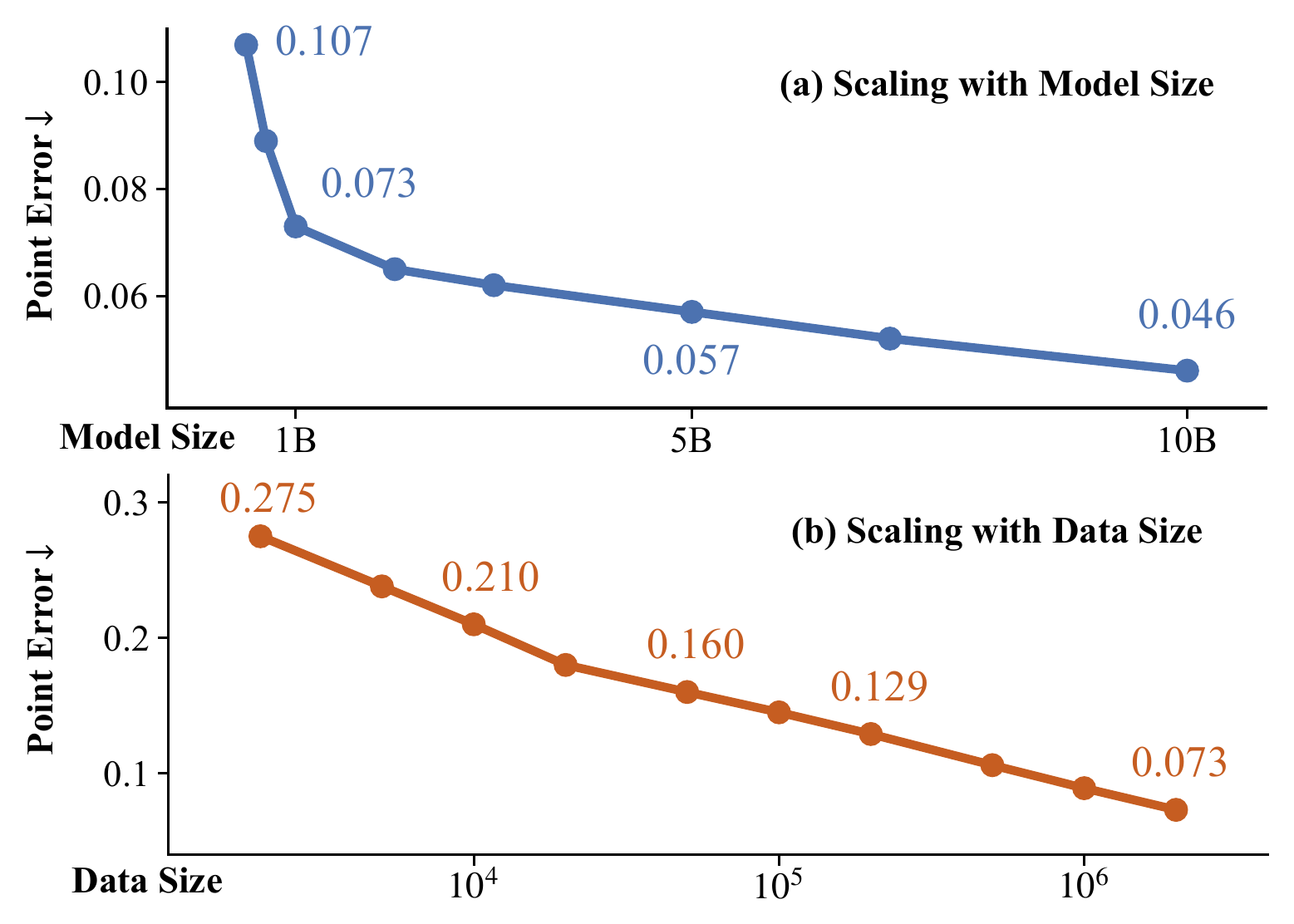
BEV Queries Q∈R^{H×W×C}where H, W are the spatial shape of the BEV plane. Each grid cell in the BEV plane corresponds to a real-world size of s meters. The center of BEV features corresponds to the position of the ego car by default. Spatial Cross-Attention \mathrm{S C A} ( Q_{p}, F_{t} )=\frac{1} {| \mathcal{V}_{\mathrm{h i t}} |} \sum_{i \in\mathcal{V}_{\mathrm{h i t}}} \sum_{j=1}^{N_{\mathrm{h i t}}} \mathrm{D e f o r m A t t n} ( Q_{p}, \mathcal{P} ( p, i, j ), F_{t}^{i} ), x^{\prime}...
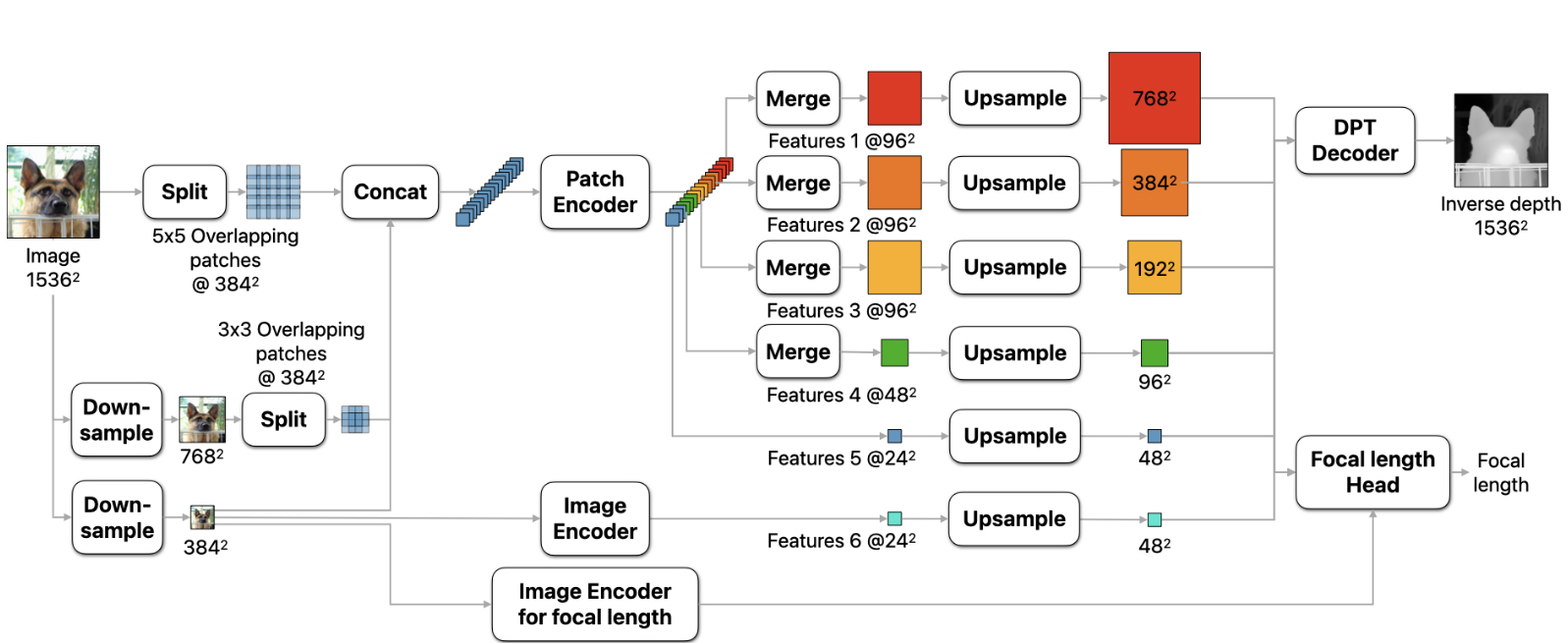
DEPTH PRO: SHARP MONOCULAR METRIC DEPTH IN LESS THAN A SECOND
思路:在不同的尺度提取patches,对patches应用ViT encoders,将patches 的预测结果融合成一个单独的高分辨率的稠密估计。 方法 1.相对于可变分辨率的方法,将输入分辨率固定为了1536×1536,保证了足够大的感受野,防止了out-of-memory的问题。使用普通的ViT encoder,能够利用多种预训练ViT的主干网络。 2.将输入图像分成5×5个分辨率为384×384的重叠patch,下采样至786×786后分成3×3个重叠的patch。将patch链接后输入patch encoder,每一个patch得到分辨率为24×24的feature。在精细的尺度上,进一步提取中间特征。得到特征之后将特征patches融合成maps输入decoder。 Sharp 单目深度估计训练目标网络预测的输出为canonical inverse depth,然后通过视场角转换为metric depth D_m=\frac{f_{px}}{wC}对于metric datasets,使用MAE...
最新文章